哪些算法和数据结构是需要程序员必须掌握的?
作为一名程序员,大家有没有想过:编码最本质的知识是什么?或许是算法和数据结构,至少很多人这么认为。
本场 Chat 从以下几个方面讨论算法的性能:
- 算法研究的科学方法;
- 编写衡量算法的时间性能类 StopWatch;
- ThreeSum 的例子阐述算法的方方面面;
- 衡量时间复杂度的一种简单度量:波浪线表示;
- 一些典型的 Order of Growth, 比如 log2n, n, nlog2n, n2 , n3;
- 分析 Java 中各种类型的内存消耗,包括原生类型,对象类型,字符串和数组。
-
-
- 1. 科学方法(Scientific method)
- 2. 时间度量
- 3. ThreeSum 例子
- 3.1 加倍假设
- 3.2 经验分析
- 3.3 数学分析
- 4. 波浪线符号
- 5. 增长的阶数(order of growth)
- 6. 内存消耗
- 6.1 原生类型(Primitive types)
- 6.2 对象
- 6.3 数组和字符串(Arraysand strings)
-
1. 科学方法(Scientific method)
以下 5 个步骤总结了此方法,依次为如下,我们设计的实验必须是可以重现的,我们形成的假设必须是具有真伪的。

2. 时间度量
测试程序运行的精确时间有时是困难的,但是我们有许多辅助工具。在这里,我们简化程序运行时间的模型,考虑各种输入情况,并测试每种情况下的运行时间,编写的这个程序名称为:Stopwatch.java,如下所示:
1 public class Stopwatch { 2 3 private final long start; 4 5 public Stopwatch() { 6 start = System.currentTimeMillis(); 7 } 8 9 public double elapsedTime() {10 long now = System.currentTimeMillis();11 return (now - start) / 1000.0;12 }1314 public static void main(String[] args) {15 int n = Integer.parseInt(args[0]);1617 // sum of square roots of integers from 1 to n using Math.sqrt(x).18 Stopwatch timer1 = new Stopwatch();19 double sum1 = 0.0;20 for (int i = 1; i <= n; i++) {21 sum1 += Math.sqrt(i);22 }23 double time1 = timer1.elapsedTime();24 StdOut.printf("%e (%.2f seconds)\n", sum1, time1);2526 // sum of square roots of integers from 1 to n using Math.pow(x, 0.5).27 Stopwatch timer2 = new Stopwatch();28 double sum2 = 0.0;29 for (int i = 1; i <= n; i++) {30 sum2 += Math.pow(i, 0.5);31 }32 double time2 = timer2.elapsedTime();33 StdOut.printf("%e (%.2f seconds)\n", sum2, time2);34 }35} 对于大多数程序,首先我们能想到的量化观察是它们有问题的大小(problem size)区别,这个表征了计算复杂度或计算难度。
一般地,问题大小既可以指通过输入数据的大小,也可以指通过命令行参数输入值。
直觉上,运行时间应该会随着问题大小而增加,但是增加的程度怎么度量,这是我们编程运行程序时常遇到的问题。
3. ThreeSum 例子
为了阐述方法,我们先引入一个具体的编程问题:ThreeSum,它是在给定的含有 n 个元素的数组中找出三元组之和等于 0 的个数。
这个问题最简单的一个解法:枚举。代码如下:
1 public class ThreeSum { 2 3 // print distinct triples (i, j, k) such that a[i] + a[j] + a[k] = 0 4 public static void printAll(int[] a) { 5 int n = a.length; 6 for (int i = 0; i < n; i++) { 7 for (int j = i+1; j < n; j++) { 8 for (int k = j+1; k < n; k++) { 9 if (a[i] + a[j] + a[k] == 0) {10 StdOut.println(a[i] + " " + a[j] + " " + a[k]);11 }12 }13 }14 }15 } 1617 // return number of distinct triples (i, j, k) such that a[i] + a[j] + a[k] = 018 public static int count(int[] a) {19 int n = a.length;20 int count = 0;21 for (int i = 0; i < n; i++) {22 for (int j = i+1; j < n; j++) {23 for (int k = j+1; k < n; k++) {24 if (a[i] + a[j] + a[k] == 0) {25 count++;26 }27 }28 }29 }30 return count;31 } 3233 public static void main(String[] args) { 34 int[] a = StdIn.readAllInts();35 Stopwatch timer = new Stopwatch();36 int count = count(a);37 StdOut.println("elapsed time = " + timer.elapsedTime());38 StdOut.println(count);39 } 40} 我们在这里主要关心的是输入数据大小与运行时长的关系。我们循着如下的思路分析两者间的关系。
3.1 加倍假设
加倍假设(Doubling hypothesis)对于大量的程序而言,我们能很快地形成如下假设:假如输入数据的个数加倍,运行时间怎么变化。
3.2 经验分析
经验分析(Empirical analysis)一种简单的实现加倍假设的方法是使输入数据的个数加倍,然后观察对运行时长的影响。
如下所示为一个简单的通过加倍输入个数,测试运行时长的程序:DoublingTest.Java。
1public class DoublingTest { 2 3 public static double timeTrial(int n) { 4 int[] a = new int[n]; 5 for (int i = 0; i < n; i++) { 6 a[i] = StdRandom.uniform(2000000) - 1000000; 7 } 8 Stopwatch s = new Stopwatch(); 9 ThreeSum.count(a);10 return s.elapsedTime();11 }121314 public static void main(String[] args) { 15 StdOut.printf("%7s %7s %4s\n", "size", "time", "ratio");16 double previous = timeTrial(256);17 for (int n = 512; true; n += n) {18 double current = timeTrial(n);19 StdOut.printf("%7d %7.2f %4.2f\n", n, current, current / previous);20 previous = current;21 } 22 } 23}再回到 ThreeSum.java 程序中,我们生成一系列随机数,填充到输入数组中,每一个时步都加倍输入元素个数,然后观察到每一次程序所运行的时间都会大致增加 8 倍,这个就可以让我们下结论说输入数据加倍后运行时间增加了 8 倍。
如下图中左侧视图所示,当输入大小为 4K 时,运行时长为 64T,当输入带下为 8K 时,运行时长变为原来的 8 倍:512T。
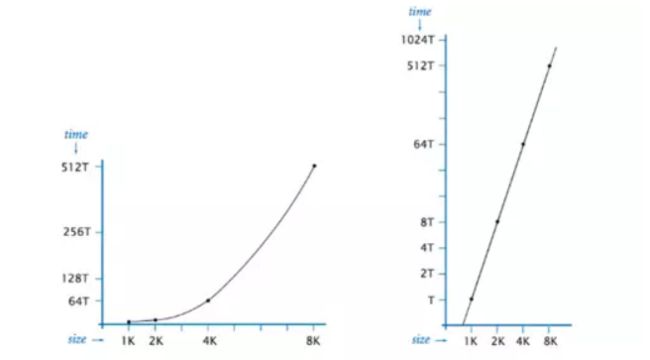
Log–logplot:绘制 log 图也是衡量运行时间的一种方法,因为是log级别的,所以与上面说的经验公式没有本质区别,如图右所示,取完对数后,输入数据大小与运行时间的对数变为线性关系。
3.3 数学分析
总的运行时长受到两个主要指标影响:
- 执行每一个语句的成本
- 执行每一个语句的次数
其中,第一个是系统属性,后面一个是算法的属性。假如我们知道了程序中所有指令的这两个属性值,那么两者相乘求和后便是整个程序的运行时间。
主要的挑战是确定第二个指标,即语句的执行次数。一些语句是很容易分析出执行次数,比如将 count 设置初始值为 0,在 ThreeSum.count() 中仅仅执行一次。
但是,有些需要更高层次的推理演算才能得到语句的执行频次,比如 if 语句被执行的次数恰好为:n(n-1)(n-2)/6。
4. 波浪线符号
我们用波浪线符号形成更加简单的近似表示。首先,我们用数学表达式的主项作为波浪线的近似表示。写作:∼g(n) 。表示为算法的时间复杂度,当它被 f(n) 除的时候,随着 n 的增大,g(n) 接近1。我们也可以写 g(n) ~ f(n) 表示,随着 n 的增大g(n)/f(n) 接近 1。
在这个表示下,我们忽略表达式中次要项。例如,在 ThreeSum.count() 中的 if 语句的执行次数用波浪线表示为:∼n3/6。因为 n(n-1)(n-2)/6 = n3/6 –n2/2+ n/3,当被n3/6 相除时,随着 n 的增长,等于1。
我们专注于那些执行次数最多的指令,有时指内层循环。在 ThreeSum.java 程序中,我们可以合理地推理出内层循环以外的指令相对来说不重要。
5. 增长的阶数(order of growth)
分析一个程序的运行时长时,关键的一个点是大多数程序的运行时长满足关系:T(n) ~cf(n),此处c是一个常数,f(n) 是一个关于时间的增长阶次函数。对于一些典型的程序,f(n) 是一个函数,例如: log2n、n、nlog2n、n2、n3。
再看 ThreeSum.java 程序,增长的阶数等于 n3,常数 c 的值取决于执行指令的成本和次数的细节上,但是我们通常不需要算出精确值。刚才说加倍输入数据个数,运行时长变为原来 8 倍,具体推导公式如下:

下面详细列出程序的增长阶数的典型例子:

6. 内存消耗
除了需要考虑时间成本,我们也要注意内存消耗。内存消耗在 Java 程序中很好地被定义,但是 Java 程序可以编译在各种不同配置环境的计算设备上,内存消耗因实现方式不同而不同,在这里讨论 Java 中三种类型的内存消耗。
6.1 原生类型(Primitive types)
因为 java int 数据类型是整数值的集合,取值范围位于:−2,147,483,648 ~ 2,147,483,647,所占的字节数为 4 个。如下图所示为主要原生类型所占的内存字节数:

6.2 对象
对象(objects)为了确定一个对象的内存消耗,我们需要求以下两者的和:
- 每一个实例的内存消耗
- 每一个对象关联的头部消耗,典型的是 8 个字节
例如,一个复数对象消耗内存为 32 个字节,其中 16 个字节被头部所占,另外,每个 double 变量各占 8 个字节。

对一个对象的引用通常消耗 8 个字节的内存。当一个数据类型包含一个对象的引用时,我们必须单独分配 8 个字节用于存储引用关系,每个对象的头部消 耗16 个字节,还包括此对象的实例变量所耗内存。
6.3 数组和字符串(Arraysand strings)
在 Java 中,数组是通过 objects 被实现的,典型的实现方法:带有 2 个实例变量,一个指针指向第一个元素的首地址,另一个指向元素长度。对于原生类型,含有 n 个元素的数组用 24 字节的头部信息,另外包括存储一个元素需要的字节数乘以元素个数。典型的例子如下:

本文首发于GitChat,未经授权不得转载,转载需与GitChat联系。
阅读全文: http://gitbook.cn/gitchat/activity/5b35856c18887615fe36ffa7
您还可以下载 CSDN 旗下精品原创内容社区 GitChat App ,阅读更多 GitChat 专享技术内容哦。
