Hbase原理的介绍和使用场景分析
主流nosql
MongoDB、Hbase、Redis

本文只介绍Hbase:
HBase数据模型
命名空间
命名空间是对表的逻辑分组,不同的命名空间类似于关系型数据库中的不同的Database数据库。利用命名空间,在多租户场景下可做到更好的资源和数据隔离。
表
对应于关系型数据库中的一张张表,HBase以“表”为单位组织数据,表由多行组成。
行
行由一个RowKey和多个列族组成,一个行有一个RowKey,用来唯一标示。
列族
每一行由若干列族组成,每个列族下可包含多个列,如上ImployeeBasicInfoCLF和DetailInfoCLF即是两个列族。列族是列共性的一些体现。注意:物理上,同一列族的数据存储在一起的。
列限定符
列由列族和列限定符唯一指定,像如上的name、age即是ImployeeBasicInfoCLF列族的列限定符。
单元格
单元格由RowKey、列族、列限定符唯一定位,单元格之中存放一个值(Value)和一个版本号。
时间戳
单元格内不同版本的值按时间倒序排列,最新的数据排在最前面
HBase 优点
1) 存储容量大,一个表可以容纳上亿行,上百万列;
2)可通过版本进行检索,能搜到所需的历史版本数据;
3)负载高时,可通过简单的添加机器来实现水平切分扩展,跟Hadoop的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce);
4)在第3点的基础上可有效避免单点故障的发生。
HBase 缺点
基于Java语言实现及Hadoop架构意味着其API更适用于Java项目;
node开发环境下所需依赖项较多、配置麻烦(或不知如何配置,如持久化配置),缺乏文档;
占用内存很大,且鉴于建立在为批量分析而优化的HDFS上,导致读取性能不高;
API相比其它 NoSql 的相对笨拙。
思考几个问题
1、region是如何划分?
hbase的表中的行rowkey按照字典顺序进行排序
在行的方向上基于rowkey分割为多个region
2、region是如何分配管理的?
一张表上面有多个region被随机分配到集群中的regionserver中进行管理,由master进行随机分配
同一个regionserver上可以管理不同表中的region,每个rengionserver上管理的regin的数量是均衡。
每张表默认创建时候只用一个region,随着表中数据量的增大到一定阀值(10G),会自动分为两个region,分割后region会被master再次分配给regionserver去管理
当某台机器的regionserver发生宕机,那么其管理的region丢失管理,master把这台regionserver管理的region重新分配给其他的regionserver去管理
3、为什么HBase 中不建议单表列簇超过 3 个
1. 多列簇导致持有数据量最少的列簇扫描性能下降,主要是因为数据太分散。
2.存在多个列簇的时候,由于它们是共享的同一个 Region,如果其中的一个 列簇触发了 flush 动作,相应关联的其他列簇也会进行 flush 。导致系统整体产生更多的 IO , 耗费资源 。
HBase 适用场景
1在线业务查询:订单,商品,快递单号,如历史订单
2离线业务的存储
Hbase三个重要的机制
flush机制:
思考:一个regionserver上面有多个region。即多个metastore,当单个metastore没有达到128M。但是整个regionserver,metastore的总大小已经很大了,比如已经占用了20个metastore,每个120M,2.4G
| 当metastore达到128MB的时候,会把数据flush成为storeFile
当regionserver上全部的metastore达到40%的时候,强制阻塞操作,直接把metastore中数据,flush成storeFile
当regionserver上全部的metastore达到38%的时候,把占比比较大的metastore中数据,flush成storeFile |
compact机制:
当storeFile越来越多,会触发compact机制,把多个storeFile合并成一个大的storeFile
合并分为两个:小合并(min compact) 大合并(major compact)
split机制:
当合并后的storeFile越来越大,(10G)就会触发split机制。把region一分为二
默认的老版本的是248M
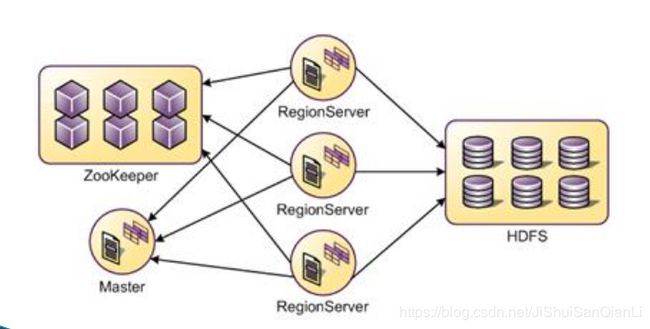
Hbase写入数据的流程
1.client先去zookeeper访问,从zookeeper中获取meta表
2.通过读取meta表,确定region所在的regionserver的服务器
3.client直接向这台服务器发出写入数据的请求
4.regionserver接到请求,然后响应
5.client首先把数据写入Hlog中,防止丢失
6.把数据写入metastore进行缓存。默认的大小是128M
7.当Hlog和metastore全部完成,这次写入才算成功
8.当数据达到128M的时候,发生flush机制把数据变为storeFile
9.当storeFile越来越多,会触发compact(压紧)机制,把多个storeFile合并成一个大的storeFile
10.当合并后的storeFile越来越大,(10G)会触发split机制,把region拆分为2个region,
一个列簇对应一个store,一个store下面会有多个storeFile,最终落地在HDFS,形成Hfile