论文学习笔记:曹哲 实时多人人体姿态识别 CVPR2017
最近学习了曹哲的这篇Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,认真读了,也看了曹哲直播的视频,虽然程序还是看不懂,但也算是学到东西了,写个笔记记录一下,其实大部分也就是直接把论文翻译过来,里面出现的PPT截图也是我之前自己做的,但是不小心存成兼容模式之后文字变成图片了o(╥﹏╥)o,所以就直接截了图,还是希望能和大家多多交流,更好地学习理解这篇论文。
本文的研究目标为给定一张RGB图像,得到所有人体关键点的位置信息,同时知道每一个关键点是属于图片中具体哪个人的,即得到关键点之间的连接信息。具体的效果展示即实时的在视频上对每一帧图像进行检测的结果,并没有做任何的目标追踪,或其他利用时间上的连续性加速这个结果。

一、与传统多人人体姿态估计方法的对比
论文首先介绍了该方法与传统多人人体姿态估计方法的对比,大多数方法都是采用一种自上而下的方式(Top-down Approach:Person Detection + Pose Estimation),就是给定一张图片,先做人体的检测,在每个人的位置上都得到一个边缘方框信息,在每个方框上,做单人的人体姿态估计,重复这个步骤,直到得到最终的结果。

这种方法存在两个主要的缺陷:
1)十分依赖人体姿态检测的结果(假如说有两个人靠的很近,有的时候会只得到一个方框信息,它的最终结果也会少一个人)
2)算法速度与图片上人的数目成正比,假如说一张图有30个人,它要重复30次单人的人体估计,这样使得这个方法在复杂场景下变得十分缓慢
为改进上述缺陷,该论文采用了一种自下而上的方法(Down-topApproach:PartsDetection + Parts Association),首先检测人关键点的位置,比如图片上人体右肩膀的位置,得到检测结果是通过预测人体关键点的热点图,可以看到在每个人体关键点上都有一个高斯的峰值,代表神经网络相信这里有一个人体的关键点。同样的我们对其他人体关键点比如说右手肘作同样的处理,得到这个检测结果。在得到检测结果之后,对关键点检测结果进行连接,换句话说,就是想知道每个关键点具体是属于图片中哪个人。
对于这个步骤,他们的方法是通过一个新的特征进行推测,这个特征是一个矢量场,叫作人体关键点亲和场(PAFs),在后面会具体介绍这个特征的表示,这里先整体介绍方法的结构。然后重复这个步骤,对另外关键点之间(另外人体的躯干)的连接进行推测,同样是通过人体关键点亲和场来进行推测,重复这个步骤,直到得到人体的全部骨架信息。

二、Jointly Learning Parts Detection and Parts Association
同时对人体关键点检测和关键部位连接进行学习。这个方法主要包括两个部分,第一个部分右侧的分支,人体关键点的检测。第二个部分就是人体关键点的连接。他们的创新点就是设计了一个设计了一个深度学习网络结构,同时学习人体关键点的检测和人体关键点的连接。并且,同时学习会使得他们互相帮助,得到更好的结果。
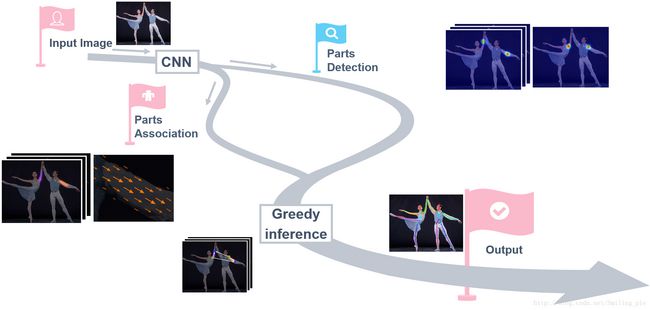
下面是同时学习的一些具体内容。这是两分支多阶段的结构图,每个分支都是一个迭代的预测架构,具体内容是在CPM论文中提出的,后面会给大家简单介绍一下。对于最终的结果每个分支各输出一个集合。检测部分(上面的分支)输出身体各部分位置信息的二维置信图集S,有J个置信图,每类关键点对应一个。连接部分(下面的分支)输出身体各部分亲和力矢量场L,有C个矢量场,每类肢体对应一个。

图像首先被一个卷积神经网络处理后生成特征图集F(通过VGG-19的前10层进行初始化并微调),这里简单介绍一下VGG19,VGG是由Visual Geometry Group实验室提出的,论文原标题《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》,VGG16和VGG19是这篇文章提出的两个非常好的DCNN(Deep Convolutional Neural Network )。VGG网络非常深,通常有16-19层,卷积核大小为3 x 3,16和19层的区别主要在于后面三个卷积部分卷积层的数量。可以看到VGG的前几层为卷积和maxpool的交替,后面紧跟三个全连接层,激活函数采用Relu,训练采用了dropout。这里就不贴图了,大家感兴趣的可以自己去搜一下这个结构,读一下相关论文。
处理后生成的特征图集F作为输入送到第一阶段,可以看到第一个阶段的输入只与F有关,对有t阶段的输入则与三个变量有关。


这个损失函数的公式也比较好理解,S分支t阶段的损失函数,对每一类关键点的每一个位置p处的权重乘以预测值减标注的真实值的平方(即距离)累加求和。后面的式子同理,只不过是针对每一类肢体而言,求解人体关键点亲和场的损失函数。
这里想说一个这个W(p),为什么要加这个权重呢?
在论文中也介绍了,这里用我的理解我的语言说一下,因为在标注真实值的过程中,人为标注可能不会标出图片中所有人的所有关键点,有的部位被遮挡了那么人为可能不会标注这个点,但是训练之后的系统可能会根据其他点的位置和连接信息预测出这个点,那么当图像中的p处没有标注而系统又预测出这里有关键点存在时,这时损失函数中的预测值减标注的真实值的平方(即距离)就会变的非常大。最终训练出的结果可能就偏差比较严重,可以说是非常机智了。
三、Confidence Maps for Part Detection
人体关键点检测。使用深度学习神经网络,对单张彩图进行卷积操作,大部分方法是输出热点图谱,对人体每个关键点都输出一张热点图谱,用峰值来代表关键点的位置。这一部分是在CPM的基础上,大家可以去看这篇论文,不过我看了还是不太懂,大部分都是文字性的叙述,深度学习这边刚开始学习,基础渣的不行。
采用多个阶段进行人体姿态的学习,在第一阶段得到不同关键点的热点图谱预测,比如说这个例子,显示的是人右手腕关键点预测的热点图谱,可以看到是预测错误的,它在左手腕位置给了一个更高的峰值,但是我们把所有热点图谱的预测值放进下一个阶段,用一个类似的神经网络进行卷积操作,它会优化上一阶段的结果。主要是第二阶段有了上一个阶段的预测结果,同时有了上一个阶段对各个人体关键点的信息,推测关键点之间的连接信息,进而用新的学习人体结构之间的关系,进而优化这个结果。可以看到第二个阶段的预测结果已经有了很大的提高,它很确定右手腕的位置。反复这个过程,直到最终结果,最终结果已经很接近目标值。

接下来在论文中,介绍了标注的真实值的处理方法,利用高斯函数:


可以看出,关键点标注的真实值x即为曲线的对称轴,那对于每一个x都存在这样一条曲线,生成众多曲线之后该作什么处理呢?最后取所有曲线的最大值构成最终的S*。那这里为什么取最大值不取平均值呢?
应该也是非常好理解,每一条曲线的峰值都表示这个位置存在关键点的可能性最高,如上图所示,可能有两个关键点距离比较近,这两条高斯曲线如果取平均值的话,很明显就从两个峰值变成一个峰值了,那最后预测出的结果可能就只有一个关键点了。所以这里取的是最大值。
四、Part Affinity Field for PartAssociation
关键点预测出来了,那么如何把检测出的身体关键点组合成未知数目人的整体动作呢?
起初,他们想到的方法是取中点连接法,即预测每个关键点之间的中点的热点图谱,假设有这个预测结果和两个关键点的位置,连接的中点在热点图谱对应的像素点的响应值作为这个连接的确信值。那么这个点是两个关键点之间的中点的可能性越高,这个连接是正确的可靠性就越高。这个方法也存在一定的局限性,看一下最右边这张图。中间的绿点在三条曲线上是中点的概率都很高,那么就可能出现误判。

所以这种方法的两个局限性总结为:只考虑了每个肢体的位置信息,而没有肢体的旋转信息(方向信息);将肢体的支撑范围缩小到了一个点上(听上去比较奇怪,其实意思就是你这么大个胳膊,这么大个身子,取中点的话就只用了一个点来表示整个躯干,难免出点问题对不对)。

在训练时,人体关键部分亲和场不是手工标注的,是预测出关键点之后,利用两点生成一个椭圆(自己调节参数),使这个椭圆能大致把整个躯干包在里面(如上图紫圈)。在这个紫圈内(在肢体上)的每一个像素点上,都设置一个单位向量v,如果像素点在圈外(不在肢体上),则此处的L*就是0。两个不等式就是为了保证点p在肢体上。v和p-x1的点乘,即x1p线段向v方向上的投影,即p点要在x1x2线段内。第二个不等式就是宽度上要在范围内。

对于这个取平均,其实不难看出,当没有肢体重叠的情况出现时,此处的L*c就等于L*c,k。那当有肢体重叠的情况呢,如上图左下那张,假设紫色椭圆是另一个肢体,此时p同时位于两个肢体上,在p处就有两个不同方向的单位向量,对他们求和,得到的就是黄色的向量,之后除以n(p),即p处非零向量的个数这里举例即为2,得到的就是一个比单位向量小的方向如图的向量了。
只得到每个p处的向量是不能评估这个连接是否可靠的,这是就采用积分的方法,E在最后进行连接的时候就起到了一个权重的作用。这个积分也比较好理解,两个可能的关键点位置大家可以在上图中看到,我这里用d1和d2简单代替一下,p(u)即是在d1和d2连接线上取值,从d1到d2这条线上进行积分。预测出此处的向量L(p)与d1d2的单位向量点乘,即往d1d2方向上投影的长度,那么预测出的单位向量如果和d1d2同方向的话,这个值就会比较大,值越大这个连接的可靠性越高。所以这里积分E可以作为权重,在后面评估连接的好坏(实际计算是用对u等间隔采样求和来逼近结果的)。
五、Multi-Person Parsing using PAFs
现在预测出了关键点的位置,也得到了PAFs的预测信息,但是得到的预测点有很多很多很多可能的连接,现在就是在一个K维匹配问题中找到最优解(NP-Hard)。什么是NP-Hard问题呐?这里也给大家贴一下,省了百度了。
NP是指非确定性多项式(non-deterministicpolynomial,缩写NP)。所谓的非确定性是指,可用一定数量的多项式运算去解决的问题。


针对这个问题,加入两个放松条件简化问题:
具体的执行: 从一个树的节点出发,连接另外一个节点,重复这个过程,直到把人体所有的树状结构里的连接都走一遍。
注意到这个变量Z是个非0即1的集合。即系统预测为连接则为1,未连接则为0,应该就是根据那个匈牙利算法来的。
