生成对抗网络GAN系列(六)--- CycleGAN---文末附代码

Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
---文末附代码
Jun-Yan Zhu Taesung Park Phillip Isola Alexei A. Efros
Berkeley AI Research (BAIR) laboratory, UC Berkeley
1.概述
本篇提出的cycleGAN其实也是在做image to image translation,之前已经有较为成功的网络pix2pix了(其实是同一个团队的人做的),本篇论文的出发点和pix2pix的不同在于:
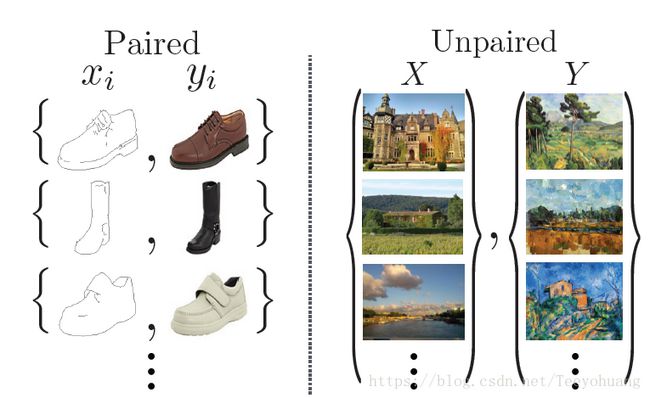
①pix2pix网络要求提供 image pairs,也即是要提供x和y,整个思路为:从噪声z,根据条件x,生成和真实图片y相近的y’。条件x和图像y是具有一定关联性的!
②而本篇cycleGAN不要求提供pairs,如题目中所说:Unpaired。因为成对的图像数据集其实并不多。这里的X和Y不要求有什么较好的关联性,可以是毫不相干的两幅图像。
对比关系如下:
2.核心思想
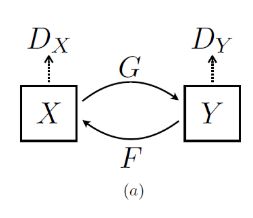
从X生成Y,再从Y生成回X,如此循环往复,故名为cycleGAN
3.具体实现
两个Generator网络:G和F
两个Discriminator网络,Dx和Dy,如下图:

①所以Adversarial Loss有两部分,
因为是要对两个D和G进行优化:
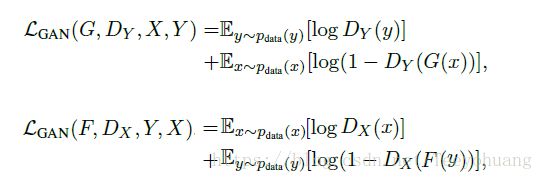
②另外还有一个Cycle Consistency Loss,
这个说直白一点,就是希望:从X生成Y’再重新生成的X’,能够接近X:
![]() 此过程得到的称为forward cycleloss
此过程得到的称为forward cycleloss
![]() 此过程得到的称为backward cycleloss
此过程得到的称为backward cycleloss
采用的L1损失函数:
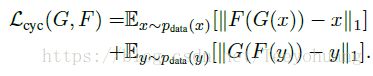
总得损失函数就是:
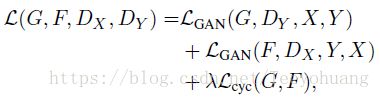
补充!!!!!!
在作者给的代码中,还加入了一个identity loss!!!也有两部分:
详细点说:
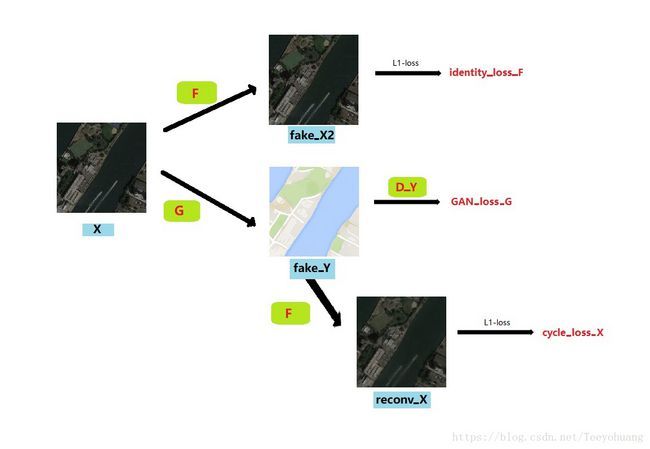
本来我要从X经过G生成fake_Y,
但如果我把Y输入进G呢?它还是应该生成fake_Y,我们可以称为fake_Y2;
也就是说,本来生成器G是用来生成Y这种风格的图像的,如果输入本身就是Y,那么就更应该生成Y这个图像了,
这就是要让这个生成器G能够做到identity mapping,所以可以计算fake_Y2和输入Y的L1-loss,称之为identity-loss;
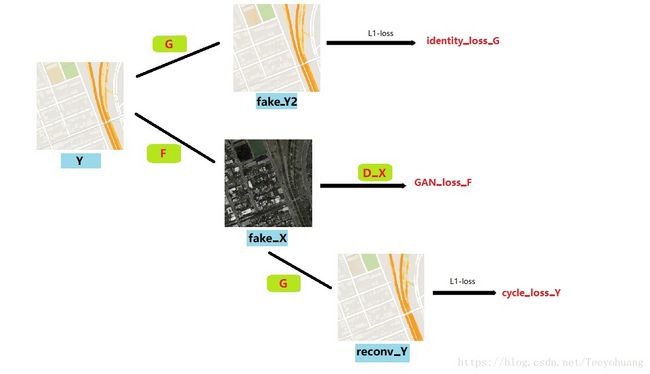
同理,对于生成器F,如果输入Y,就会生成fake_X;
但如果我把X输入F,那么就得到fake_X2,也要让生成器F具备identity mapping的能力;
计算二者的L1-loss,也是作为identity-loss的一部分
所以总得来说,可以参考如下图:
4.网络结构
Generator采用的是Perceptual losses for real-time style transfer and super-resolution 一文中的网络结构;
简而言之,就是一个resblock组成的网络,降采样部分采用stride 卷积,增采样部分采用反卷积;
注意采用的是instance normalization
Discriminator采用的仍是pix2pix中的PatchGANs结构,大小为70x70
详细结构参考代码
5.一些实验细节:
①具体的损失函数采用的不是log而是 least-squares loss,具体来说:
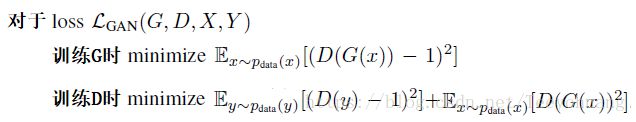
关于采用此损失函数的好处,在我的此系列中第(四)篇博文中讲过,即是LSgan
②为了减少震荡,使用历史生成图片而不是最新生成图片来进行D的训练。具体为缓存50张历史生成图像;
③令λ = 10 ,使用Adam优化,base learning rate = 0.0002. We keep the same learning rate for the first 100 epochs and linearly decay the rate to zero over the next 100 epochs.
6.代码:
我自己复现的精简版pytorch代码:
https://github.com/TeeyoHuang/CycleGAN-pytorch
论文作者写的pytorch版本的代码:
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix,
。
。