python 爬虫自己动手做一个种子搜索器
一般来说,一般下载资源都是从种子搜索网站搜种子,然后用迅雷下载,需要打开几个网页同时点开下载,稍微有些繁琐,所以就想自己动手用python爬虫实现一个种子搜索器,并用pyqt4做成客户端,一站式完成搜索下载,方便快捷,不用来回打开页面。
大致思路是这样的:从种子搜索网站爬取种子,用python驱动迅雷下载。关于种子的来源还有一种方式是冒充DHT节点,加入到DHT网络中获取种子,我们这里直接从种子搜索网站爬取数据。
我们用火狐浏览器打开打开一个种子搜索网站http://www.zhongzimao.com/
输入“变形金刚”点击搜索
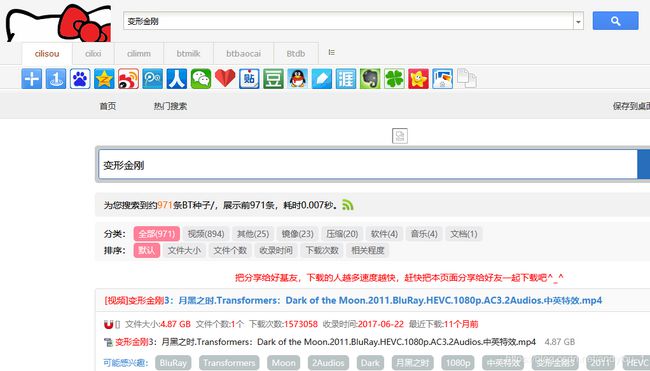
按F12打开控制台,再次点击搜索

第一个请求就是搜索的http请求,查看响应,发现是一个html页面,查看请求

请求网址是“https://btdb.cilimm.com/search/变形金刚”,打开“https://btdb.cilimm.com/”发现是另一个网站,原来是盗链。
分析网页源代码,为爬取种子做准备

每一个条目是一个class为popobox的div,子元素中,title是标题,sortbar是资源信息,比如文件个数,文件大小,下载次数等,slist是完整文件列表,like是猜你喜欢。我们主要从前两个子元素中爬取信息
首先每一个种子的信息封装成一个类
class Popobox():
titletype = ""
title = ""
moto_link = ""
filesize = ""
filecount = ""
downloadnum = ""
includedtime = ""
latestdownload = ""
filetype = ""
def __str__(self):
return '%s;标题=%s;文件大小=%s;文件个数=%s;下载次数=%s;上传时间=%s;filetype=%s' \
%(self.titletype,
self.title,
self.filesize,
self.filecount,
self.downloadnum,
self.includedtime,
self.filetype
)
搜索model类,我们用lxml做html解析工具,在类的构造函数里生成一个lxml的html解析器,和迅雷驱动
# -*- coding: utf-8 -*-
import requests
from lxml import etree
from win32com.client import Dispatch
import sys
from PyQt4 import QtCore, QtGui
class MotoScan():
def __init__(self):
self.parser = etree.HTMLParser(encoding="utf-8")
self.thunder = Dispatch('ThunderAgent.Agent64.1')
我们首先从title标签下获取标题
popobox_list = htmlEmt.xpath('//*[@class="popobox"]')
for popo_elem in popobox_list:
popo = Popobox()
title_elem = popo_elem.xpath('child::div[@class="title"]')[0]
popo.titletype = title_elem.xpath('child::h3/span')[0].text
title_spans = title_elem.xpath('child::h3/a/span')
try:
popo.title = "%s" % (title_elem.xpath('child::h3/a')[0].text)
for span in title_spans:
popo.title = popo.title + "%s%s" % (span.text, span.tail)
except:
pass
if (popo.title is None or popo.title == ""):
popo.title = "%s%s" % (title_elem.xpath('child::h3/a')[0].text)
popo.title = popo.title.replace("None", "")
然后分析sortbar标签

获取种子的链接等信息
popo.title = popo.title.replace("None", "")
sort_bar = popo_elem.xpath('child::div[@class="sort_bar"]')[0]
popo.moto_link = sort_bar.xpath('child::span[1]/a')[0].get("href")
popo.filesize = sort_bar.xpath('child::span[2]/b')[0].text
popo.filecount = sort_bar.xpath('child::span[3]/b')[0].text
popo.downloadnum = sort_bar.xpath('child::span[4]/b')[0].text
popo.includedtime = sort_bar.xpath('child::span[5]/b')[0].text
popo.latestdownload = sort_bar.xpath('child::span[6]/b')[0].text
驱动迅雷下载
def download(self,filename,motolink):
self.thunder.AddTask(motolink, filename)
self.thunder.CommitTasks()
最后是GUI,布局很简单,一个输入框一个按钮,一个列表,双击列表条目就开启下载
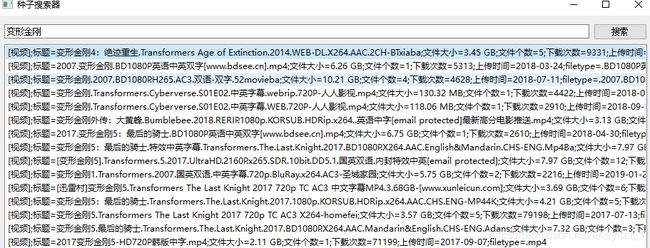
全部代码已经上传到github
https://github.com/wongqueng/motoscan
项目已经打包成exe,下载地址:
https://download.csdn.net/download/andylou_1/11033959
2019.3.29更新,这个网站的源代码改了,这上面的解析方式不行了