大数据实践的6个阶段
戳蓝字“CSDN云计算”关注我们哦!
来源公众号 | 智领云科技
作者 | 智领云 彭锋博士
在最新的“2018年Gartner数据管理技术成熟度曲线”报告中,DataOps的概念被首次提出,Gartner标记其目前在“极为初级”这个阶段里面,并预计需要5-10年的达到一个技术成熟时期。
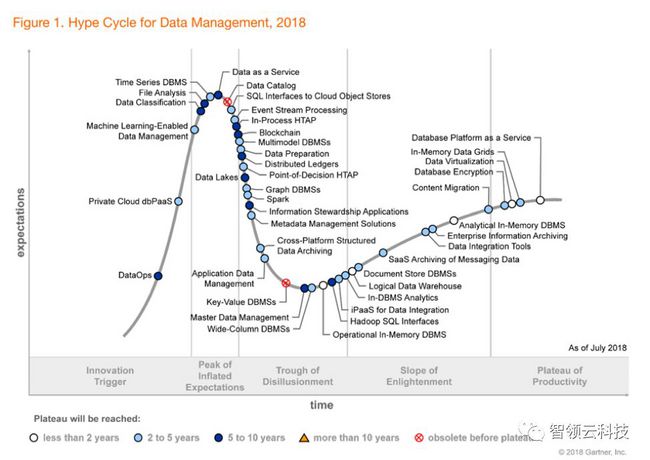
“极为初级”阶段是报告描述的技术成熟曲线的五个阶段之一,Gartner预计一项技术从出现到公众熟知将经历以下的五个阶段:
“极为初级” 阶段 一项潜在的技术突破可以解决问题。早期的概念验证故事和媒体兴趣引发了重要的宣传。通常没有可用的产品存在且商业可行性未经证实。
“爆发增长”阶段 早期宣传产生了许多成功故事 – 通常伴随着许多失败。一些公司采取行动; 大部分都没有。
“幻灭的低谷” 阶段 由于实验和实施无法实现,早期的利好逐渐减弱。该技术的生产者放弃技术或宣告失败。只有幸存的供应商改进其产品以满足早期采用者的需求,投资才会继续。
“启蒙的斜坡”阶段 更多关于技术如何使企业受益的实例开始明确并且得到更广泛的理解。后期迭代的产品来自技术提供商。更多企业资助开始注资试点项目; 保守的公司仍然保持谨慎。
“生产力的高原”阶段 技术开始被广泛接受。评估技术提供者的可行性的标准更明确。该技术广泛的市场适用性和相关性显然得到了回报。如果该技术不仅仅是一个利基市场,那么它将继续增长。
基于上面的定义,Gartner报告基本上表明DataOps刚刚出现在数据管理领域,并且被认为是像在几年前Spark和流处理一样的潜在市场颠覆性技术之一。那么DataOps到底意味着什么?为什么它只是在Hadoop引领大数据浪潮近10年后才出现?
我们将尝试通过描述大数据项目的六个阶段来回答这些问题,并了解DataOps真正带来了什么。
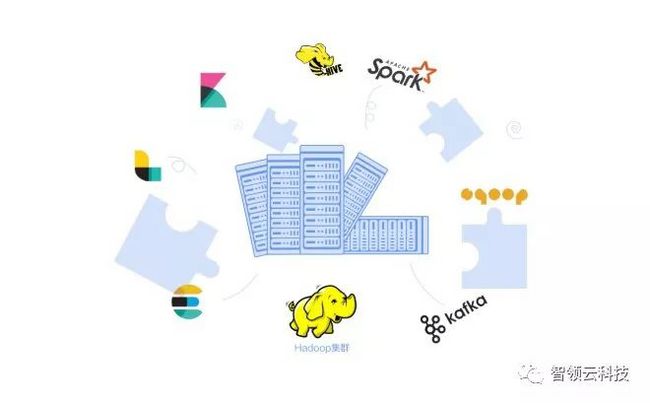
阶段1 技术试验阶段
在此阶段,你的团队可能会安装一个Hadoop集群和Hive(可能带有Sqoop),以便将一些数据传输到集群并运行一些查询。近年来,包括Kafka和Spark在内的组件也被考虑在内。如果要进行日志分析,也可以安装ELK(ElasticSearch,LogStash,Kibana)等套件。
但是,这些系统大多数都是复杂的分布式系统,其中一些系统需要数据库支持。虽然许多提供单节点模式供你使用,但你的团队仍需要熟悉常见的Devops工具,如Ansible,Puppet,Chef,Fabric等。
由于开源社区的辛勤工作,对大多数工程团队来说,使用这些工具和原型设计应该是可行的。如果团队里面有一些优秀的工程师,你可能会在几周内设置好一个可以联通及运行的系统,具体的工作量一般取决于你要安装的组件数量。
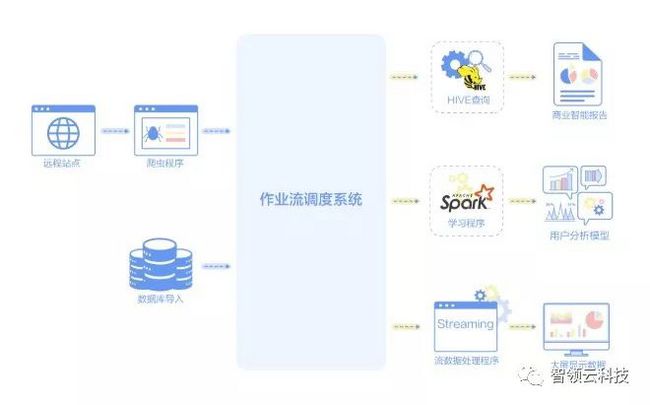
阶段2 自动化阶段
在这个阶段,你已经拥有了一个基本的大数据系统,接下来你的需求可能有:
一些定期运行的Hive查询,比如每小时一次或每天一次,以生成一些商业智能报告;
使用一些Spark程序运行机器学习程序,生成一些用户分析模型,使你的产品系统可以提供个性化服务;
一些需要不时从远程站点提取数据的爬虫程序;
或一些流数据处理程序,用于创建实时数据仪表板,显示在大屏幕上。
要实现这些需求,你需要一个作业调度系统,以根据时间或数据可用性来运行它们。像Oozie,Azkaban,Airflow等工作流系统允许你指定何时运行程序(类似Linux机器上的Cron程序)。
工作流系统之间的功能差异很大。例如,一些系统提供依赖关系管理,允许你指定调度逻辑,如作业A仅在作业B和作业C完成时运行;一些系统允许仅管理Hadoop程序,而另一些系统则允许更多类型的工作流程。你必须决定一个最符合你要求的。
除了工作流程系统,你还有其他需要自动化的任务。例如,如果你的HDFS上的某些数据需要在一段时间后删除,假设数据只保留一年,那么在第366天,我们需要从数据集中最早的一天中删除数据,这称为数据保留策略。你需要编写一个程序,为每个数据源指定并实施数据保留策略,否则你的硬盘将很快耗尽。
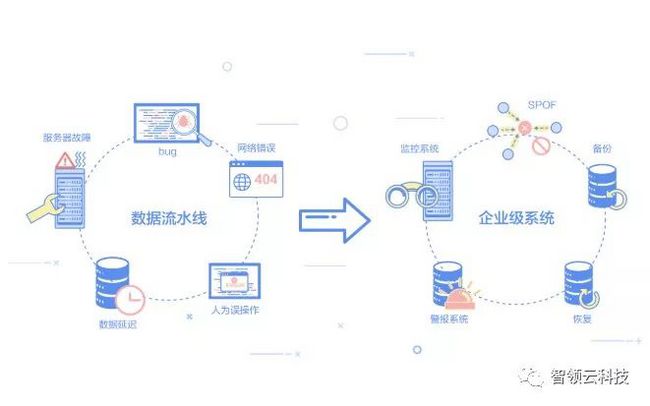
阶段3 投入生产阶段
现在你已经拥有了一个自动数据管道,数据终于可以在这个数据流水线上流动起来!大功告成?现实情况是你的生产环境会遇到下面这些棘手的问题:
第一年硬盘故障率为5.1%(与第一年服务器故障率类似)
第4年服务器的故障率为11%
大量使用的开源程序有很多bug
你的程序可能估计也会有一些bug
外部数据源有延迟
数据库有停机时间
网络有错误
有人在运行“sudo rm -rf / usr / local /”时使用了额外的空格
这些问题发生的次数会比你想象的要频繁得多。假设你有50台机器,每台机器有8个硬盘驱动器,那么一年内将有20个硬盘驱动器故障,一个月大约2个。经过几个月的手动过程挣扎,你终于意识到你迫切地需要:
监控系统:你需要一个监控程序来监控硬件,操作系统,资源使用情况,程序运行;
系统探针:系统需要告诉你它的各种运行指标,以便它可以被监控;
警报系统:出现问题时,需要通知运维工程师;
SPOF:避免单点故障,如果你不想在凌晨3点被叫醒,最好系统里不要出现SPOF;
备份:你需要尽快备份重要数据;不要依赖Hadoop的3份数据副本,它们可以通过一些额外的空格被轻松删除;
恢复:如果你不希望每次发生时都手动处理所有错误,那么这些错误最好尽可能自动恢复。
在这个阶段你意识到建立一个企业级的系统并不像安装一些开源程序那么容易,可能我们要多下一点苦功了。
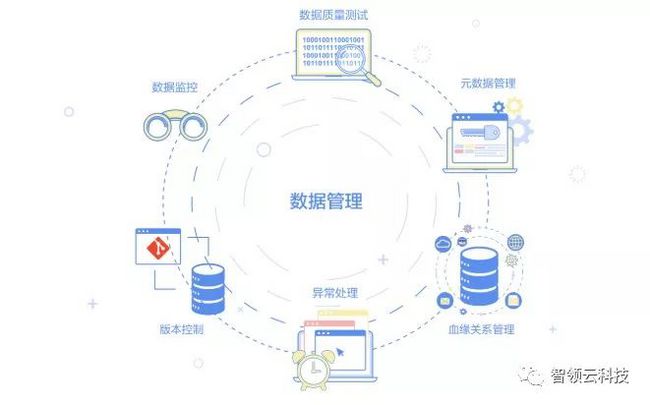
阶段4 数据管理阶段
一个企业级的大数据系统不仅要处理与任何标准系统操作类似的硬件和软件故障问题,还要处理与数据相关的问题。对于一个真正数据驱动的IT系统,你需要确保你的数据完整,正确,准时,并为数据进化做好准备。
那么这些意味着什么?
你需要知道在数据流水线的任何步骤中数据都不会丢失。因此,你需要监控每个程序正在处理的数据量,以便尽快检测到任何异常;
你需要有对数据质量进行测试的机制,以便在数据中出现任何意外值时,你接收到告警信息;
你需要监控应用程序的运行时间,以便每个数据源都有一个预定义的ETA,并且会对延迟的数据源发出警报;
你需要管理数据血缘关系,以便我们了解每个数据源的生成方式,以便在出现问题时,我们知道哪些数据和结果会受到影响;
系统应自动处理合法的元数据变更,并应立即发现和报告非法元数据变更;
你需要对应用程序进行版本控制并将其与数据相关联,以便在程序更改时,我们知道相关数据如何相应地更改。
此外,在此阶段,你可能需要为数据科学家提供单独的测试环境来测试其代码。并给他们提供各种便捷和安全的工具,让他们能快速验证自己的想法,并能方便地发布到生产环境。
阶段5 重视安全性阶段
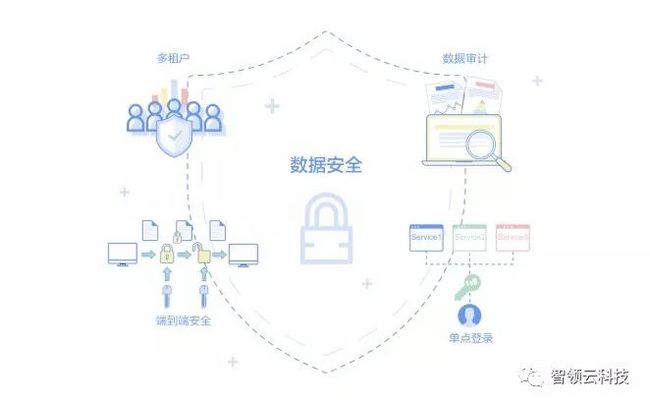
在这个阶段大数据已经与你密不可分:面向客户的产品由数据驱动,你的公司管理层依靠实时的业务数据分析报告来做出重大决策。你的数据资产安全将变得非常最重要,你能确定你的数据只有合适的人员才能访问吗?并且你的系统拥有身份验证和授权方案吗?
一个简单的例子是Hadoop的Kerberos身份验证。如果你没有使用Kerberos集成运行Hadoop,那么拥有root访问权限的任何人都可以模拟Hadoop集群的root用户并访问所有数据。其他工具如Kafka和Spark也需要Kerberos进行身份验证。由于使用Kerberos设置这些系统非常复杂(通常只有商业版本提供支持),我们看到的大多数系统都选择忽略Kerberos集成。
除了身份验证问题,以下是你在此阶段需要处理的一些问题:
审计:系统必须审计系统中的所有操作,例如,谁访问了系统中的内容
多租户:系统必须支持多个用户和组共享同一个集群,具有资源隔离和访问控制功能;他们应该能够安全,安全地处理和分享他们的数据;
端到端安全性:系统中的所有工具都必须实施正确的安全措施,例如,所有Hadoop相关组件的Kerberos集成,所有网络流量的https / SSL;
单点登录:系统中的所有用户在所有工具中都应具有单一身份,这对于实施安全策略非常重要。
由于大多数开源工具都没有在其免费版本中提供这些功能,因此许多项目在安全问题上采用“撞大运”的方法并不奇怪。我们同意安全的价值对不同的项目来说有不同的理解,但人们必须意识到潜在的问题并采取适当的方法。
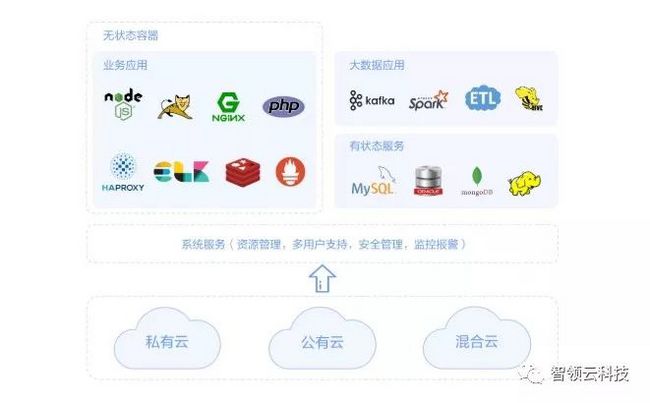
阶段6 云基础架构的大数据阶段
在这个阶段随着业务的不断增长,越来越多的应用程序被添加到大数据系统中。除了像Hadoop / Hive / Spark这样的传统大数据系统,你现在需要使用TensorFlow运行深度学习,使用InfluxDB运行一些时间序列分析,使用Heron来处理流数据,或者一些Tomcat程序来提供数据服务API。每当你需要运行一些新程序时,你会发现配置机器和设置生产部署的过程非常繁琐,并且有很多的坑要踩。此外,有的时候你需要临时搞到一些机器来完成一些额外的分析工作,例如,可能是一些POC,或者要对一个比较大的数据集进行训练。
这些问题是你首先需要在云基础架构上运行大数据系统的原因。像Mesos这样的云平台为分析工作负载和一般工作负载提供了极大的支持,并提供了云计算技术提供的所有好处:易于配置和部署,弹性扩展,资源隔离,高资源利用率,高弹性,自动恢复。
在云计算环境中运行大数据系统的另一个原因是大数据工具的发展。传统的分布式系统(如MySQL集群,Hadoop和MongoDB集群)倾向于处理自己的资源管理和分布式协调。但是现在由于Mesos / Yarn这样的分布式资源管理器和调度程序的出现,越来越多的分布式系统(如Spark)将依赖底层分布式框架来提供这些资源分配和程序协调调度的分布式操作原语。在这样的统一框架中运行它们将大大降低复杂性并提高运行效率。
总结
我们看到过处于各种阶段的实际的大数据项目。在Hadoop被采用了10多年之后,我们看到的大部分项目仍然停留在第1阶段或第2阶段。这里主要的问题是在第3阶段实施系统需要大量的专业知识和大量投资。Google的一项研究表明,构建机器学习系统所花费的时间中只有5%用于实际的机器学习代码,另外95%的时间用于建立正确的基础架构。由于数据工程师因难以培训而非常昂贵(由于需要对分布式系统有很好的理解),因此大多数公司都很不幸的没能走进大数据时代的快车道。
与DevOps一样,DataOps是一个需要正确工具和正确思维的持续过程。DataOps的目标是使以正确的方式更容易地实现大数据项目,从而以更少的工作从数据中获得最大的价值。Facebook和Twitter等公司长期以来一直在内部推动类似DataOps的做法。然而,他们的方法通常与他们的内部工具和现有系统相绑定,因此很难为其他人推广。
在过去几年中,通过Mesos和Docker等技术,大数据操作的标准化成为可能。结合更加广泛的采用数据驱动的文化,DataOps终于准备好可以进入到大家的视野。我们相信这一运动将降低实施大数据项目的障碍,使每个企业和机构都更容易获取数据的最大价值。
![]()
福利
扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

关于智领云
武汉智领云科技有限公司于2016年成立于武汉光谷,专注于大数据、云计算领域的核心技术研发。公司创始团队成员来自于推特(Twitter)、苹果(Apple)和艺电(EA)等硅谷知名企业,拥有多年的云计算和大数据系统的软件开发、项目运作和公司管理的经验。公司已经获得了数千万元国内外著名风险投资机构及天使投资人的投资。公司研发的BDOS(大数据操作系统)采用业界领先的容器技术对大数据系统需要的各种组件进行标准化和产品化,在统一的云平台架构下运行,为物联网、机器学习、人工智能、商业智能、互联网应用提供全面的大数据平台及运维支持,快速高效地实施、开发和管理一个企业级的大数据系统。BDOS使用户可集中精力在业务逻辑上而无须考虑系统底层技术细节,极大地提高了大数据及人工智能应用的开发效率,降低运维成本,持续高效地实现大数据价值。
推荐阅读:
做了中台就不会死吗?每年至少40%开发资源是被浪费的!
美女主播变大妈:在bug翻车现场说测试策略
漫画高手、小说家、滑板专家……解锁程序员的另一面!
手把手教你如何用Python模拟登录淘宝
鸿蒙霸榜 GitHub,从最初的 Plan B 到“取代 Android”?
每天超50亿推广流量、3亿商品展现,阿里妈妈的推荐技术有多牛?
真香,朕在看了!