4用于cifar10的卷积神经网络-4.25/4.26Tensorflow中的四种学习率衰减方法(上/下)
TensorFlow中的可变学习率
1、exponential_decay指数式衰减:


功能:对输入学习率learning rate实现指数衰减。
当我们训练一个模型的时候,经常需要根据训练过程的进展来逐渐降低学习率。上面的函数把一个指数衰减函数应用到初始学习率上以达到在训练过程中不断减少学习率。它需要一个“global step”值来计算衰减以后的学习率。你可以传入一个TensorFlow variable,只要这个Variable在每个训练步都自增就可以啦。
更新公式:
decayed_learning_rate = learning_rate *
decay_rate ^ (global_step / decay_steps)如果参数‘staircase ’为true,那么‘global_step/decay_step’是一个整数除法,衰减后的学习率是一个阶梯状的函数。
示例代码:以0.1的初始学习率开始,每隔100000步衰减一下,衰减速率:0.96
global_step = tf.Variable(0, trainable=False)
starter_learning_rate = 0.1
learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,
100000, 0.96, staircase=True)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)参数:
learning_rate : 初始的learning rate
global_step : 全局的step,与 decay_step 和 decay_rate一起决定了 learning rate的变化。
staircase : 如果为 True global_step/decay_step 向下取整
decayed_learning_rate为每一轮优化时使用的学习率;
learning_rate为事先设定的初始学习率;
decay_rate为衰减系数;
decay_steps为衰减速度。

2、polynomial_decay多项式衰减:


功能:对输入学习率learning rate实施多项式衰减
大量的实验观察表明:通过精心的选择学习率的单调下降速率,可以获得一个性能更好地模型。这个函数使用一个多项式衰减函数使得学习率从指定的初始值(‘learning_rate’)经过指定的步数(‘decay_steps’)单调下降到指定的结束值(‘end_learning_rate’)
衰减以后的学习率是如下计算的:
python
global_step = min(global_step, decay_steps)
decayed_learning_rate = (learning_rate - end_learning_rate) *
(1 - global_step / decay_steps) ^ (power) +
end_learning_rate示例代码:decay from 0.1 to 0.01 in 10000 steps using sqrt (i.e. power=0.5):
python
...
global_step = tf.Variable(0, trainable=False)
starter_learning_rate = 0.1
end_learning_rate = 0.01
decay_steps = 10000
learning_rate = tf.train.polynomial_decay(starter_learning_rate, global_step,
decay_steps, end_learning_rate,
power=0.5)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)
3、natural_exp_decay自然指数衰减:
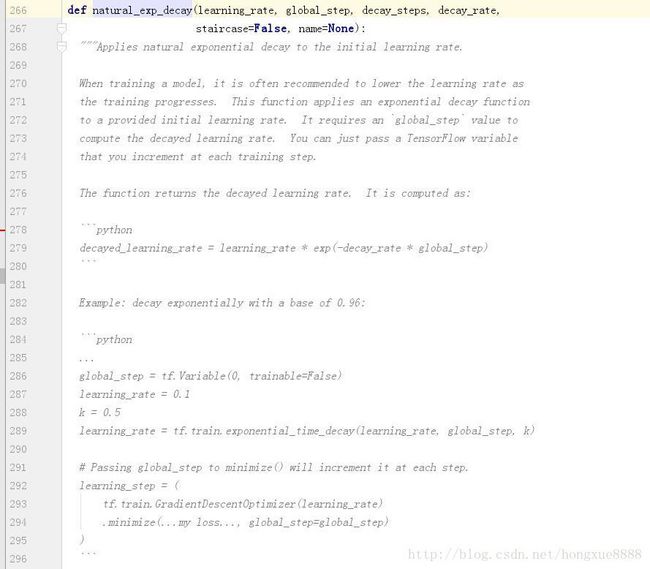

衰减以后的学习率是如下计算的:
decayed_learning_rate = learning_rate * exp(-decay_rate * global_step)示例代码: decay exponentially with a base of 0.96:
global_step = tf.Variable(0, trainable=False)
learning_rate = 0.1
k = 0.5
learning_rate = tf.train.exponential_time_decay(learning_rate, global_step, k)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)
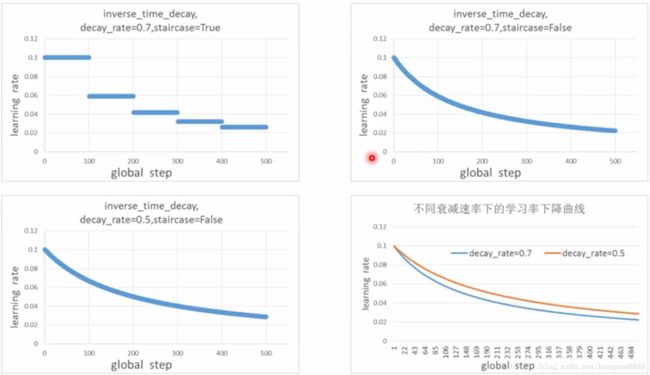
4、inverse_time_decay逆时间衰减:


衰减以后的学习率是如下计算的:
decayed_learning_rate = learning_rate / (1 + decay_rate * t)示例代码: decay 1/t with a rate of 0.5:
global_step = tf.Variable(0, trainable=False)
learning_rate = 0.1
k = 0.5
learning_rate = tf.train.inverse_time_decay(learning_rate, global_step, k)
# Passing global_step to minimize() will increment it at each step.
learning_step = (
tf.train.GradientDescentOptimizer(learning_rate)
.minimize(...my loss..., global_step=global_step)
)
代码如下:
#-*- coding:utf-8 -*-
#实现简单卷积神经网络对MNIST数据集进行分类:conv2d + activation + pool + fc
import csv
import tensorflow as tf
import os
from tensorflow.examples.tutorials.mnist import input_data
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import sys
from six.moves import urllib
import tarfile
import cifar10_input
import numpy as np
# 设置算法超参数
training_epochs = 5
num_examples_per_epoch_for_train = 10000
batch_size = 100
learning_rate_init = 0.1
learning_rate_final = 0.001
learning_rate_decay_rate = 0.7
# learning_rate_decay_rate = 0.5
num_batches_per_epoch = int(num_examples_per_epoch_for_train/batch_size)
num_epochs_per_decay = 1 #Epochs after which learning rate decays
learning_rate_decay_steps = int(num_batches_per_epoch * num_epochs_per_decay)
display_step = 50
conv1_kernel_num = 32
conv2_kernel_num = 32
fc1_units_num = 250
fc2_units_num = 150
activation_func = tf.nn.relu
activation_name = 'relu'
l2loss_ratio = 0.05
with tf.Graph().as_default():
#优化器调用次数计算器,全局训练步数
global_step = tf.Variable(0,name='global_step',trainable=False,dtype=tf.int64)
#使用exponential_decay产生指衰减的学习率
learning_rate = tf.train.exponential_decay(learning_rate_init,
global_step,
learning_rate_decay_steps,
learning_rate_decay_rate,
staircase=False)
#使用polynomial_decay产生多项式衰减的学习率
# learning_rate = tf.train.polynomial_decay(learning_rate_init,
# global_step,
# learning_rate_decay_steps,
# learning_rate_decay_rate,
# staircase=False)
# 使用natural_exp_decay产生自然指数衰减的学习率
# learning_rate = tf.train.natural_exp_decay(learning_rate_init,
# global_step,
# learning_rate_decay_steps,
# learning_rate_decay_rate,
# staircase=False)
# 使用inverse_time_decay产生逆时间衰减的学习率
# learning_rate = tf.train.inverse_time_decay(learning_rate_init,
# global_step,
# learning_rate_decay_steps,
# learning_rate_decay_rate,
# staircase=False)
#定义损失函数
weights = tf.Variable(tf.random_normal([9000,9000],mean=0.0,stddev=1e9,dtype=tf.float32))
myloss = tf.nn.l2_loss(weights,name="L2Loss")
#传入 learning_rate创建优化器对象
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
#将global_step传入minimize(),每次调用minimize都会使得global_step自增1.
training_op = optimizer.minimize(myloss,global_step=global_step)
#添加所有变量的初始化节点
init_op = tf.global_variables_initializer()
#将评估结果保存到文件
results_list = list()
results_list.append(['train_step','learning_rate','train_step','train_loss'])
#启动会话,训练模型
with tf.Session() as sess:
sess.run(init_op)
#训练指定轮数,每一轮的训练样本总数为:num_examples_per_epoch_for_train
for epoch in range(training_epochs):
print('********************************************')
#每一轮都要把所有的batch跑一遍
for batch_idx in range(num_batches_per_epoch):
#获取learning_rate的值
current_learning_rate = sess.run(learning_rate)
#执行训练节点,获取损失节点和global_step的值
_,loss_value,training_step = sess.run([training_op,myloss,global_step])
print("Training Epoch:" + str(epoch) +
",Training Step:" + str(training_step)+
",Learning Rate = " + "{:.6f}".format(current_learning_rate) +
",Learning Loss = " + "{:.6f}".format(loss_value))
#记录结果
results_list.append([training_step,current_learning_rate,training_step,loss_value])
#将评估结果保存到文件
print("训练结束,将结果保存到文件")
results_file = open('evaluate_results/learning_rate/exponential_decay/evaluate_results(decay_rate=0.7,staircase=False).csv','w',newline='')
csv_writer = csv.writer(results_file,dialect='excel')
for row in results_list:
csv_writer.writerow(row)