面试记录,加油!(停更)
文章目录
- 一:处女面,来自阿里的电话面试(2017/07/30,时长90分钟)
- 1.java中的反射Reflection
- 2.java中的动态代理
- 3.Hibernate中的缓存机制
- 3.1.为什么使用缓存机制
- 3.2 hibernate的缓存原理
- 3.3 Hibernate中的缓存是如何工作的
- 4. Spring中对事物的管理
- 5.Spring中事务隔离的级别
- 6.数据库中的乐观锁(读)、悲观锁(写)
- 7.java中几种常用设计模式
- 7.1 单例模式(一个类只有一个实例)
- 7.2 工厂模式
- 7.3 代理模式
- 7.4 适配器模式
- 8.JVM中的GC
- 9.Java中如何判断是不是同一个类
- 10.java中的类加载器ClassLoader
- 11.Spring中的依赖注入方式
- 12.java中常用的线程池有哪些
- 13.如何保证一个方法中的一小部分逻辑代码的线程安全,不用同步代码块、不用单独拎出来
- 14.java中的缓存,如何进行更新
- 15.java中继承和多态
- 16.java中覆盖和重载的概念
- 17.HashMap和Hashtable是否是线程安全的,他们内部机制是如何的
- 18.递归的概念以及使用场景
- 19.Java如何实现序列化的
- 二:广联达视频面试,2017/09/06,时长58分钟,一面成功
- 2.1 HashMap与ConcurrentHashMap的区别
- 2.2 SpringMVC的参数有哪些?
- 2.3 用charAt和for循环写一个子串在主串中出现的次数
- 2.4 数据库的索引有哪几种
- 2.5 设计模式:适配器和装饰者模式
- 2.6 Spring的常用注解
- 2.7 阶乘应该考虑哪些边界问题?
- 2.8 MyBatis中传参的方式
- 三:广州汇智通信
- 四:南京万得
- 五:大华
- 5.1 红黑树和B树,其他问题
- 5.1.1 2-3树
- 5.1.2 2-3-4树
- 5.1.3 B树
- 5.1.4 B+树
- 5.2 红黑树
- 5.3 可重入锁
- 5.4 线程
- 5.4.1 直接调用`run()`方法和`start()`方法的区别
- 5.4.2 线程通信
- 5.4.3 static方法可不可以加锁,有何区别
- 5.4.4 notify()如何实现,如果不设置优先级别,会通知哪个线程
- 5.4.5 可重入锁的概念和机制
- 5.4.6 4个线程计算,1个线程总和,代码实现
- 5.5 MyBatis中Mapper的接口是否可以重载
- 5.6 MySQL中支持事务的引擎
- 六:中兴
- 七:烽火星空
- 1.数据库死锁问题,如何解决?
- 2.最短路径算法,图的遍历
- 八:河狸家
- 1.如何保证数据库中更新的数据不会出现库存-1的情况?
- 2.若要对某一个类的集合进行排序,而该类不支持排序,咋办?
- 3.ConcurrentHashMap和Hashtable你会选用哪一个?
- 九:合合信息
- 1.递归会有引起什么问题
- 2.group by和order by的区别
- 3.联合索引
- 十.华三
- 1.Hibernate中的Session是如何共享的?
- 2.JVM中的CCS
- 3.平衡树的平衡过程
- 3.1平衡二叉树的构造
- 3.2调整方法
- 4.找出字符串中的字母空格以及数字的个数。
- 十一.中科创达
- 1.static的含义,意义。
- 十二.群硕
- 1.操作系统中的进程是什么?
- 2.多线程的效率是否一定比单线程要高?为什么,举例说明。(可以完美回答的同学可以留言)
- 3.在浏览器中输入网址访问,这一过程用到哪些协议?
- 4.IP是用来干嘛的?
- 5.普通的方法和static方法都加上synchronized关键字有啥区别?
- 十三.努比亚
- 1.Spring中的AOP和IOC,和传统的方式有哪些优势?AOP如何实现?
- 2.Java注解原理
- 3.ajax原理
- 十四. 上海银行
一:处女面,来自阿里的电话面试(2017/07/30,时长90分钟)
已被拒
1.java中的反射Reflection
反射能动态地加载一个类、调用方法、访问属性,出发点在于JVM为每个类创建了一个java.lang.Class类的实例,通过这份对象可以获取这个类的信息,通过反射包下的API达到各种动态需求。
Java中的反射是一种强大的工具(其他语言中基本没有这个特性),可以创建灵活的代码,这些代码可以在运行时装配,无须在组件中进行链接。反射允许在编写与执行时,使程序代码能接触到装载到JVM中类的内部信息。Java中类的反射Reflectio是Java程序对自身进行检查,并且能直接操作程序内部的属性。代码示例:
Class<Person> clazz = Person.class;
//1.创建clazz对应的运行时类Person,用的是clazz.newInstance()
//这里的clazz.newInstance()实际上是调用的是Person类的无参构造器
Person p = clazz.newInstance();
System.out.println(p);
//2.然后在调用,调用的时候先用clazz.getField(“属性名”)的方法来获取public作用域的属性,然后再往对象里面设值
Field f1 = clazz.getField("name");
f1.set(p, "test2");
System.out.println(p);
//获取private作用域的属性值方法比一样,用上面的方法获取不到
//首先应该获取声明的属性
Field f2 = clazz.getDeclaredField("age");
//将访问权限改为true
f2.setAccessible(true);
f2.set(p, 20);
//3.通过反射调用运行类的方法,首先获取方法
Method m1 = clazz.getMethod("show");
//然后调用方法,没有形参的直接m1.invoke(p);
m1.invoke(p);
//调用有形参的方法,clazz.getMethod时需要指明参数的类型
Method m2 = clazz.getMethod("display", String.class);
//有形参的话m2.invoke(p,形参);传入形参
m2.invoke(p, "HK");
2.java中的动态代理
定义:为其他对象提供一种代理以控制对这个对象的访问。
每一个动态代理类都必须实现InvocationHandler接口,并且每个代理类的实例都关联到了一个handler,当我们通过代理对象调用一个方法的时候,这个方法的调用就会被转发为由InvocationHandler这个接口的 invoke 方法来进行调用。这里主要是面向的切面思想。举个例子
//定义了一个接口
public interface Subject {
public void rent();
public void hello(String str);
}
//实现类
public class RealSubject implements Subject {
@Override
public void rent()
{
System.out.println("I want to rent my house");
}
@Override
public void hello(String str)
{
System.out.println("hello: " + str);
}
}
//动态代理类
public class DynamicProxy implements InvocationHandler {
// 这个就是我们要代理的真实对象
private Object subject;
// 构造方法,给我们要代理的真实对象赋初值
public DynamicProxy(Object subject)
{
this.subject = subject;
}
@Override
public Object invoke(Object object, Method method, Object[] args) throws Throwable {
//在代理真实对象前我们可以添加一些自己的操作
System.out.println("before rent house");
System.out.println("Method:" + method);
//当代理对象调用真实对象的方法时,其会自动的跳转到代理对象关联的handler对象的invoke方法来进行调用
method.invoke(subject, args);
//在代理真实对象后我们也可以添加一些自己的操作
System.out.println("after rent house");
return null;
}
}
//客户端
public class Client
{
public static void main(String[] args)
{
// 我们要代理的真实对象
Subject realSubject = new RealSubject();
// 我们要代理哪个真实对象,就将该对象传进去,最后是通过该真实对象来调用其方法的
InvocationHandler handler = new DynamicProxy(realSubject);
/* * 通过Proxy的newProxyInstance方法来创建我们的代理对象,我们来看看其三个参数 * 第一个参数 handler.getClass().getClassLoader() ,我们这里使用handler这个类的ClassLoader对象来加载我们的代理对象 * 第二个参数realSubject.getClass().getInterfaces(),我们这里为代理对象提供的接口是真实对象所实行的接口,表示我要代理的是该真实对象,这样我就能调用这组接口中的方法了 * 第三个参数handler, 我们这里将这个代理对象关联到了上方的 InvocationHandler 这个对象上 */
Subject subject = (Subject)Proxy.newProxyInstance(handler.getClass().getClassLoader(), realSubject
.getClass().getInterfaces(), handler);
System.out.println(subject.getClass().getName());
subject.rent();
subject.hello("world");
}
}
3.Hibernate中的缓存机制
3.1.为什么使用缓存机制
Hibernate是一个持久层框架,经常访问物理数据库。为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能。缓存内的数据是对物理数据源中的数据的复制,应用程序在运行时从缓存读写数据,在特定的时刻或事件会同步缓存和物理数据源的数据。
3.2 hibernate的缓存原理
Hibernate缓存包括两大类:Hibernate一级缓存和Hibernate二级缓存。
- 一级缓存:又称Session的缓存,Session内置不能被卸载,Session的缓存是事务范围的缓存(Session对象的生命周期通常对应一个事务),一级缓存中,持久化类的每个实例都具有唯一的OID,Session的缓存是不可选的,必须要有的,不会出现并发的情况;
- 二级缓存:又称为SessionFactory的缓存,二级缓存的生命周期是进程范围或者集群范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别,第二级缓存是可选的,是一个可配置的插件,默认下SessionFactory不会启用这个插件;
适合用二级缓存的数据:
- 很少被修改的数据 ;
- 不是很重要的数据,允许出现偶尔并发的数据 ;
- 不会被并发访问的数据;
- 常量数据;
适合存放到第二级缓存的数据:
- 经常被修改的数据 ;
- 绝对不允许出现并发访问的数据,如财务数据,绝对不允许出现并发 ;
- 与其他应用共享的数据;
3.3 Hibernate中的缓存是如何工作的
当Hibernate根据ID访问数据对象的时候,首先从Session一级缓存中查;查不到,如果配置了二级缓存,那么从二级缓存中查;如果都查不到,再查询数据库,把结果按照ID放入到缓存删除、更新、增加数据的时候,同时更新缓存。
Hibernate在性能提升上的几种方法:
- 懒加载:lazyLoad是常用提升性能的方法。不采用LazyLoad的情况下,Hibernate在获取PO(持久对象)时,将同时获取PO的属性,如果对象的关联结构深层次的话,可能会加载出大量数据,而实际中可能只需要几个属性,这样用懒加载的方式就会很棒,只有在调用这个属性的时候才会将这个属性从缓存中或数据库库中加载出来;
- 缓存:Cache是提升系统性能方面常用的方法。Hibernate中有一级缓存和二级缓存,一级缓存即Session缓存,是必须的,二级缓存即SessionFactory,是可选的,他可以明显的提升性能,同时也会更加消耗内存,可以指定上限从而避免过多的消耗内存;
4. Spring中对事物的管理
Spring配置事务管理器,这里需要注意的是Spring并不是直接管理事务的,而是将事务委托给JDBC、Hibernate或者JTA等持久化机制所提供的相关平台框架的事务来实现的。
Spring中事务传播的特性(所有的修饰词都是针对当前事务而言的):
- PROPAGATION_REQUIRED:如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。
- PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行。
- PROPAGATION_MANDATORY(强制的):强制使用当前的事务,如果当前没有事务,就抛出异常。
- PROPAGATION_REQUIRES_NEW:新建事务(只用新事务,坚决不用别人的),如果当前存在事务,把当前事务挂起。
- PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- PROPAGATION_NEVER:以非事务方式执行(不允许事务的出现),如果当前存在事务,则抛出异常。
- PROPAGATION_NESTED(嵌套):如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与 PROPAGATION_REQUIRED 类似的操作。
5.Spring中事务隔离的级别
数据库中事物的四大特性:原子性、一致性、隔离性、持久性。
这里主要讨论的是事物的隔离性,如果不考虑隔离性,那么将会发生下面这些情况:
- 脏读:一个事务读取另一个事务改写但还未提交的数据,如果这些数据被回滚,那么读到的数据是无效的;
- 不可重复读:是指在一个事务内,多次读同一数据但是结果不一样。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。在同一事务中,两次读取同一数据,得到内容不同,侧重点在于数据修改;
- 幻读(虚读):在一个事务中读取几行记录后,另一个事务插入一些记录,第一个事物就会发现有些原来没有的记录。同一事务中,用同样的操作读取两次,得到的记录数不相同,幻读的侧重点在于两次读取的纪录数量不一致;
下面找到一个不错的例子,仅供理解:
Read uncommitted 读未提交
公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整,非常高 兴。可是不幸的是,领导发现发给singo的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后singo实际的工资只有 2000元,singo空欢喜一场。出现上述情况,即我们所说的脏读 ,两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为Read uncommitted 时,就可能出现脏读,如何避免脏读,请看下一个隔离级别。
Read committed 读提交
singo拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到另一账户,并在 singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为 何…
出现上述情况,即我们所说的不可重复读 ,两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。当隔离级别设置为Read committed 时,避免了脏读,但是可能会造成不可重复读。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。如何解决不可重复读这一问题,请看下一个隔离级别。
Repeatable read 重复读(幻读侧重点是新插入了记录,不可重复读侧重的是修改)
当隔离级别设置为Repeatable read 时,可以避免不可重复读。当singo拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),singo的老婆就不可能对该记录进行修改,也就是singo的老婆不能在此时转账。虽然Repeatable read避免了不可重复读,但还有可能出现幻读 。singo的老婆工作在银行部门,她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额 (select sum(amount) from transaction where month = 本月)为80元,而singo此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction … ),并提交了事务,随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,singo的老婆很诧异,以为出 现了幻觉,幻读就这样产生了。
注:MySQL的默认隔离级别就是Repeatable read。
Serializable 序列化
Serializable 是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。
1.脏读:
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
2.不可重复读:
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(即不能读到相同的数据内容)
例如,一个编辑人员两次读取同一文档,但在两次读取之间,作者重写了该文档。当编辑人员第二次读取文档时,文档已更改。原始读取不可重复。如果只有在作者全部完成编写后编辑人员才可以读取文档,则可以避免该问题。
3.幻读:
是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
例如,一个编辑人员更改作者提交的文档,但当生产部门将其更改内容合并到该文档的主复本时,发现作者已将未编辑的新材料添加到该文档中。如果在编辑人员和生产部门完成对原始文档的处理之前,任何人都不能将新材料添加到文档中,则可以避免该问题。
6.数据库中的乐观锁(读)、悲观锁(写)
1.悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
2.乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
适用场景:乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适,适合写操作比较多的情况。
7.java中几种常用设计模式
经典的设计模式一共23种,下面说几个常用的设计模式。其中在框架中的MVC模型视图控制器也是其中一种,模型表示业务逻辑,视图表示界面相关的部分,控制器则根据用户的输入,控制界面数据显示和更新model状态,MVC主要体现的是功能模块的分离。
7.1 单例模式(一个类只有一个实例)
单例模式主要是为了避免因为创建多个实例造成资源浪费,保证整个应用中有且只有一个实例,有这样几个要求:
- 只提供私有的构造方法;
- 一个类只允许有一个实例;
- 自行实例化;
- 对外提供一个静态的公有的函数用于创建或获取它本身的静态私有对象,里面又分懒汉(时间换空间,不推荐)和恶汉(空间换时间,可行);
//1.懒汉线程不安全
public class Singleton {
//构造方法私有化
private Singleton(){}
//自己内部实例化
private static singleton = new Singleton();
//对外提供一个获取实例的方法
public static Singleton getSingleton() {
return singleton;
}
}
//2.改进的懒汉单例,加同步锁,保证线程安全
public class Singleton {
//这里有的书上提供了私有的构造方法,有的没有,这里先加上
private Singleton(){}
//初始化
private static Singleton instance = null;
public static synchronized Singleton getInstance() {
if(instance==null) {
instance = new Singleton();
}
return instance;
}
}
//3.饿汉单例
public class Singleton {
private Singleton(){}
//饿汉,顾名思义,上来先搞一个实例化对象,并且声明为final,以后不在改变,天生线程安全
private static final Singleton singleton = new Singleton();
public static Singleton getSingleton() {
return singleton;
}
}
7.2 工厂模式
观察者模式(是一种一对多的关系):定义了对象之间的一对多的依赖,这样一来,当一个对象改变时,它的所有的依赖者都会收到通知并自动更新。工厂模式又可以分为三类:
- 简单 工厂 模式 :属于创建型模式,又叫做静态工厂方法(Static Factory Method)模式,是由一个工厂对象决定创建出哪一种产品类的实例。简单工厂模式是工厂模式家族中最简单实用的模式。(这里可以抽象为简单工厂模式就是一个工厂全包所有产品的生产,要车就产车,要房就产房,车子具体怎么产你别问我,因为我也不知道)。
- 优点 :容易实现、使用者只需要关注调用的接口,不需要关心具体实现;
- 缺点 :实现类的增减都会牵扯到工厂类的修改,工厂类偶合了实例的业务逻辑,不符合高内聚低耦合的原则,也违背了开放封闭原则;
- 工 厂方法模式:就是我们通常简称的工厂模式,它属于类创建型模式,也是处理在不指定对象具体类型的情况下创建对象的问题。实质(使用)定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪个类。工厂方法让类的实例化推迟到子类中进行。”(这里可以抽象为一个工厂可以生产任何一类产品,但是具体这类中某一具体类型的产品它都有对应的生产车间,你要啥产品跟我讲,我让手下的人去给你办)。
- 优点 :实现简单,符合开闭原则 ;
- 缺点 :新增实现,会导到工厂类大量增加,不符合优化原则 ;
- 抽象工厂模式:提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。(这里可以抽象为这是一零件组装的工厂,你不但要告诉我你需要什么 ,还需要告诉我关于这个东西具体的要求,比如说组装电脑,你要告诉我你想要什么样的CPU、什么样的主板,什么样的显卡、声卡等等,有了这些我才能组装出你满意的产品)。
- 优 点:隔离了具体类的生成,使得客户并不需要知道什么被创建,而且每次可以通过具体工厂类创建一个产品族中的多个对象,增加或者替换产品族比较方便;
- 缺 点: 结构复杂,实现难度相对来说高;
【示例】
//普通的模式创建,产品从无到有,客户自己创建宝马车,然后拿来用
public class BMW320 {
public BMW320(){
System.out.println("制造-->BMW320");
}
}
public class BMW523 {
public BMW523(){
System.out.println("制造-->BMW523");
}
}
public class Customer {
public static void main(String[] args) {
BMW320 bmw320 = new BMW320();
BMW523 bmw523 = new BMW523();
}
}
//1.简单工厂模式。客户需要知道怎么去创建一款车,客户和车就紧密耦合在一起了.为了降低耦合,就出现了工厂类,把创建宝马的操作细节都放到了工厂里面去,客户直接使用工厂的创建工厂方法,传入想要的宝马车型号就行了,而不必去知道创建的细节.
//1.1产品类
abstract class BMW {
public BMW(){
}
}
public class BMW320 extends BMW {
public BMW320() {
System.out.println("制造-->BMW320");
}
}
public class BMW523 extends BMW{
public BMW523(){
System.out.println("制造-->BMW523");
}
}
//1.2工厂类
public class Factory {
public BMW createBMW(int type) {
switch (type) {
case 320:
return new BMW320();
case 523:
return new BMW523();
default:
break;
}
return null;
}
}
//1.3客户类
public class Customer {
public static void main(String[] args) {
Factory factory = new Factory();
BMW bmw320 = factory.createBMW(320);
BMW bmw523 = factory.createBMW(523);
}
}
//2.工厂方法模式。在每次工厂中需要引入新产品的时候并且进行生产
的时候,工厂类就会很被动,需要不断的改动。这样就需要优化,在工厂
模式中,工厂类被定义为一个接口,每次生产新引进车辆的时候,就增进
该车类型对应工厂类的实现,这样工厂的设计就可以进行扩展,而不必修
改原来的代码。工厂方法模式去除了简单工厂模式中工厂方法的静态属性,
使得它可以被子类继承,这样在简单工厂模式里集中在工厂方法上的
压力可以由工厂方法模式里不同的工厂子类来分担。
//2.1产品类,同上
//2.2工厂类(接口实现接口)
interface FactoryBMW {
BMW createBMW();
}
public class FactoryBMW320 implements FactoryBMW{
@Override
public BMW320 createBMW() {
return new BMW320();
}
}
public class FactoryBMW523 implements FactoryBMW {
@Override
public BMW523 createBMW() {
return new BMW523();
}
}
//2.3客户类
public class Customer {
public static void main(String[] args) {
FactoryBMW320 factoryBMW320 = new FactoryBMW320();
BMW320 bmw320 = factoryBMW320.createBMW();
FactoryBMW523 factoryBMW523 = new FactoryBMW523();
BMW523 bmw523 = factoryBMW523.createBMW();
}
}
//3.抽象工厂模式。工厂方法模式仿佛已经很完美的对对象的创建进行了包装,
使得客户程序中仅仅处理抽象产品角色提供的接口,但使得对象的数量成倍增长。
当产品种类非常多时,会出现大量的与之对应的工厂对象,这不是我们所希望的。
于是工厂方法模式的升级本版出现了--抽象工厂模式。
//3.1产品类
//发动机以及型号
public interface Engine {
}
public class EngineA extends Engine{
public EngineA(){
System.out.println("制造-->EngineA");
}
}
public class EngineBextends Engine{
public EngineB(){
System.out.println("制造-->EngineB");
}
}
//空调以及型号
public interface Aircondition {
}
public class AirconditionA extends Aircondition{
public AirconditionA(){
System.out.println("制造-->AirconditionA");
}
}
public class AirconditionB extends Aircondition{
public AirconditionB(){
System.out.println("制造-->AirconditionB");
}
}
//3.2工厂类
//创建工厂的接口
public interface AbstractFactory {
//制造发动机
public Engine createEngine();
//制造空调
public Aircondition createAircondition();
}
//为宝马320系列生产配件
public class FactoryBMW320 implements AbstractFactory{
@Override
public Engine createEngine() {
return new EngineA();
}
@Override
public Aircondition createAircondition() {
return new AirconditionA();
}
}
//宝马523系列
public class FactoryBMW523 implements AbstractFactory {
@Override
public Engine createEngine() {
return new EngineB();
}
@Override
public Aircondition createAircondition() {
return new AirconditionB();
}
}
//3.3客户类
public class Customer {
public static void main(String[] args){
//生产宝马320系列配件
FactoryBMW320 factoryBMW320 = new FactoryBMW320();
factoryBMW320.createEngine();
factoryBMW320.createAircondition();
//生产宝马523系列配件
FactoryBMW523 factoryBMW523 = new FactoryBMW523();
factoryBMW320.createEngine();
factoryBMW320.createAircondition();
}
}
7.3 代理模式
代理模式分为”静态代理”和“动态代理”,而动态代理又分为“JDK 动态代理”和“CGLIB (Code Generation Library代码生成库)动态代理”。
- 静态代理:代理对象和实际对象都继续了同一个接口,在代理对象中指向的是实际对象的实例,这样对外暴露的是代理对象而真正调用的是 Real Object。
- 优 点:可以很好的保护实际对象的业务逻辑对外暴露,从而提高安全性。
- 缺 点:不同的接口要有不同的代理类实现,会很冗余。
- 动态代理:动态代理又分为“JDK 动态代理”和“CGLIB (Code Generation Library代码生成库)动态代理”:
- JDK动态代理:为了解决静态代理中,生成大量的代理类造成的冗余,JDK 动态代理只需要实现 InvocationHandler 接口,重写 invoke 方法便可以完成代理的实现,从代理类的
Proxy.newProxyInstance(targetObject.getClass().getClassLoader(),targetObject.getClass().getInterfaces(), this)获取方式来看,必须传入实现的接口。
优 点:解决了静态代理中冗余的代理实现类问题;
缺 点:JDK 动态代理是基于接口设计实现的,如果没有接口,但会抛异常; - CGLIB代理 :由于 JDK 动态代理限制了只能基于接口设计,而对于没有接口的情况,JDK方式解决不了;CGLib 采用了非常底层的字节码技术,其原理是通过字节码技术为一个类创建子类,并在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑,来完成动态代理的实现。实现方式实现
MethodInterceptor接口,重写intercept方法,通过Enhancer类的回调方法来实现。
优 点:没有接口也能实现动态代理,而且采用字节码增强技术,性能也不错;
缺 点:技术实现相对难理解些;
- JDK动态代理:为了解决静态代理中,生成大量的代理类造成的冗余,JDK 动态代理只需要实现 InvocationHandler 接口,重写 invoke 方法便可以完成代理的实现,从代理类的
7.4 适配器模式
将一个类的接口转换成另一个接口,让原本接口不兼容的类可以相互合作。就像手机充电器充电的时候正常需要的是5V电压,而插座提供的是220V交流电,适配器模式就是提供这样一个从220V到5V接口转换的功能。
适配模式可以分为“类适配”和“对象适配”两种方式,这里要介绍场景举例说明(要不用白板画图说明)以上场景为例:管理中心的接口target(源接口),对外提供的用户上传接口为 outOjb 接口,实现类 adaptee,适配类 adapter。
- 类适配:适配类 adapter 需要继承 adaptee 类同时实现 target 源接口,在适配类中完成数据格式转化;
- 对象适配:与类适配不一样的是,不需要继续 adaptee,适配类 adapter 只要实现 target源接口,在 adapter 类中传入 outojb 的实现实例 adaptee 对象便可;
8.JVM中的GC
GC是典型的守护线程,只要当前JVM实例中尚存一个非守护线程(即用户线程)没有结束,守护线程就会全部工作,只有当最后一个非守护线程结束时,守护线程才回随着JVM一起结束工作。
GC不仅负责垃圾回收,还决定内存分配。GC分类主要按其生命周期划分为这样几类:年轻代、老年代、持久代。其中持久代主要存放的是类信息,所以与java对象的回收关系不大,与回收息息相关的是年轻代和年老代。他们的关系图如下
- 年轻代(Young Generation):年轻代被分为3个部分——Enden区和两个Survivor区(From和to)。当Eden区被对象填满时,就会执行Minor GC(从年轻代空间回收内存被称为 Minor GC)。并把所有存活下来的对象转移到其中一个survivor区(假设为from区)。Minor GC同样会检查存活下来的对象,并把它们转移到另一个survivor区(假设为to区)。这样在一段时间内,总会有一个空的survivor区。经过多次GC周期后,仍然存活下来的对象会被转移到年老代内存空间。通常这是在年轻代有资格提升到年老代前通过设定年龄阈值来完成的。需要注意,Survivor的两个区是对称的,没先后关系,from和to是相对的;
- 老年代(Old Generation):在年轻代中经历了N次回收后仍然没有被清除的对象,就会被放到年老代中,可以说他们都是久经沙场而不亡的一代,都是生命周期较长的对象。对于年老代和永久代,就不能再采用像年轻代中那样搬移腾挪的回收算法,因为那些对于这些回收战场上的老兵来说是小儿科。通常会在老年代内存被占满时将会触发Full GC(清理整个堆空间,回收堆内存,包括年轻代和老年代);
- 持久代(Permanent Generation):用于存放静态文件,比如java类、方法等,持久代对垃圾回收没有显著的影响;
这里找到一个不错的比喻:“假设你是一个普通的 Java 对象,你出生在 Eden 区,在 Eden 区有许多和你差不多的小兄弟、小姐妹,可以把 Eden 区当成幼儿园,在这个幼儿园里大家玩了很长时间。Eden 区不能无休止收容你们,所以当年纪稍大,就要被送到学校去上学,这里假设从小学到高中都称为 Survivor 区。开始的时候你在 Survivor 区里面划分出来的的“From”区,读到高年级了,就进了 Survivor 区的“To”区,中间由于学习成绩不稳定,还经常来回折腾。直到你 18 岁的时候,高中毕业了,该去社会上闯闯了。于是你就去了年老代,年老代里面人也很多。在年老代里,你生活了 20 年 (每次 GC 加一岁),最后寿终正寝,被 GC 回收。有一点没有提,你在年老代遇到了一个同学,他的名字叫爱德华 (慕光之城里的吸血鬼),他以及他的家族永远不会死,那么他们就生活在永生代(持久代)。”
9.Java中如何判断是不是同一个类
当时我回答的是使用instanceof,然后面试官又追问了一句,那java内部是如何判断是否为同一个类呢?当时有点懵。。
-
jvm中类相同的条件:包名+类名+类加载器实例ID,这里的类加载器实例就是指通过
Class.forName()或者类.class得到的实例,然后可以通过得到实例的getClassLoader()方法获取类加载器; -
java中类相同的条件:包名+类名
【注】
这里扩展一下Class.forName()和ClassLoader.loadClass的知识点,这两者都是用来装载类的,对于类的装载一般分为加载、连接、编译三个阶段,两者的主要区别为:
Class.forName():内部调用的调用的是forName(className,boolean,ClassLoader),三个参数分别表示类的包路径、是否在Loading时进行初始化(默认为true)、类加载器(默认使用当前类加载时的加载器),Class.forName(className)默认是需要初始化。一旦初始化,就会触发目标对象的 static块代码执行,static参数也也会被再次初始化;ClassLoader.loadClass():内部调用的是ClassLoader.loadClass(name,false)这个方法,第二个参数默认为flase,说明类加载时不会进行链接,不进行链接意味着不进行包括初始化等一些列步骤,那么静态块和静态对象就不会得到执行;
10.java中的类加载器ClassLoader
类加载主要有三种方式:
- 命令行启动应用时候由JVM初始化加载;
- 通过
Class.forName()方法动态加载; - 通过
ClassLoader.loadClass()方法动态加,ClassLoader主要作用是将class加载到JVM内,同时它还要考虑class由谁来加载;
ClassLoader的加载流程:
运行一个程序的时候,JVM启动,通常是如下的流程:
- 运行bootstrap classloader(称为启动类加载器,是Java类加载层次中最顶层的类加载器,负责加载JDK中的核心类库);
- 然后调用ExtClassLoader(称为扩展类加载器,负责加载Java的扩展类库,默认加载JAVA_HOME/jre/lib/ext/目下的所有jar)加载扩展API;
- 最后AppClassLoader(称为系统类加载器,负责加载应用程序classpath目录下的所有jar和class文件)加载CLASSPATH目录下定义的Class;
classLoader加载类的原理:
1、原理介绍
ClassLoader使用的是双亲委托模型来搜索类的,每个ClassLoader实例都有一个父类加载器的引用(不是继承的关系,是一个包含的关系),虚拟机内置的类加载器(Bootstrap ClassLoader)本身没有父类加载器,但可以用作其它ClassLoader实例的的父类加载器。当一个ClassLoader实例需要加载某个类时,它会试图亲自搜索某个类之前,先把这个任务委托给它的父类加载器,这个过程是由上至下依次检查的,首先由最顶层的类加载器Bootstrap ClassLoader试图加载,如果没加载到,则把任务转交给Extension ClassLoader试图加载,如果也没加载到,则转交给App ClassLoader 进行加载,如果它也没有加载得到的话,则返回给委托的发起者,由它到指定的文件系统或网络等URL中加载该类。如果它们都没有加载到这个类时,则抛出ClassNotFoundException异常。否则将这个找到的类生成一个类的定义,并将它加载到内存当中,最后返回这个类在内存中的Class实例对象。
2、为什么要使用双亲委托这种模型呢?
因为这样可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子ClassLoader再加载一次。考虑到安全因素,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义的类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时就被引导类加载器(Bootstrcp ClassLoader)加载,所以用户自定义的ClassLoader永远也无法加载一个自己写的String,除非你改变JDK中ClassLoader搜索类的默认算法。
3、 但是JVM在搜索类的时候,又是如何判定两个class是相同的呢?
JVM在判定两个class是否相同时,不仅要判断两个类名是否相同,而且要判断是否由同一个类加载器实例加载的。只有两者同时满足的情况下,JVM才认为这两个class是相同的。就算两个class是同一份class字节码,如果被两个不同的ClassLoader实例所加载,JVM也会认为它们是两个不同class。
11.Spring中的依赖注入方式
- 属性注入,在配置文件中用
property标签注入,实质上是调用的setter方法;普通的基本数据类型和String类型可以通过name、value的方式了配置,集合的话需要通过name、list(value)的方式来配置,对其他bean的引用用name、ref方式即可; - 构造器注入,bean在定义的时候好几个私有属性,且定义了含参构造方法,此时在配置文件中就可以用constructor-arg标签来注入;用index表明第几个参数,用value或者ref表明该参数具体赋值;
- 工厂方法注入,不推荐使用;
【注意】BeanFactory生产的Bean实例默认采用单例模式,即一个IOC容器生产的A对象只有一个;
【区别】settr方法注入是创建完对象在通过setter方法注入,比较灵活,而构造方法是在构建对象的同时就把依赖关系也购建好了,对象创建完了之后就已经准备好了所有资源,安全性要高一些。
12.java中常用的线程池有哪些
1.newCachedThreadPool(可缓存线程池)
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。这种类型的线程池特点是:
- 工作线程的创建数量几乎没有限制(其实也有限制的,数目为
Interger. MAX_VALUE), 这样可灵活的往线程池中添加线程; - 如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程;
- 在使用
CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪;
2.newFixedThreadPool(定长线程池)
创建一个指定工作线程数量的线程池。每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。FixedThreadPool是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,因此会占用一定的系统资源。
3.newSingleThreadExecutor(单线程化线程池)
创建一个单线程化的Executor,即只创建唯一的工作者线程来执行任务,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。如果这个线程异常结束,会有另一个取代它,保证顺序执行。单工作线程最大的特点是可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。
4.newScheduleThreadPool(周期、定长线程池)
创建一个定长的线程池,而且支持定时的以及周期性的任务执行,支持定时及周期性任务执行。
13.如何保证一个方法中的一小部分逻辑代码的线程安全,不用同步代码块、不用单独拎出来
这个问题没有找到靠谱的答案,正在查找中。。。。。
说法1:用concurent.automic包下的一些原子变量类来进行解决 线程安全问题,就是用一些线程安全类对象来替代 一些共享数据变量类型,比如automicLong类可以替换Long类型,从而实现线程安全
14.java中的缓存,如何进行更新
如果某些资源或者数据会被频繁的使用,而这些资源或数据存储在系统外部,比如数据库、硬盘文件等,那么每次操作这些数据的时候都从数据库或者硬盘上去获取,速度会很慢,会造成性能问题。一个简单的解决方法就是:把这些数据缓存到内存里面,每次操作的时候,先到内存里面找,看有没有这些数据,如果有,那么就直接使用,如果没有那么就获取它,并设置到缓存中,下一次访问的时候就可以直接从内存中获取了。从而节省大量的时间,当然,缓存是一种典型的空间换时间的方案。
1.缓存的实现
主要两种两大类:
- 一种是通过文件缓存,就是把数据存储在磁盘上,不管你是以XML格式,序列化文件DAT格式还是其它文件格式;
- 第二种是内存缓存,也就是实现一个类中静态Map,对这个Map进行常规的增删查;
在Java中最常见的一种实现缓存的方式就是使用Map, 基本的步骤是:
- 先到缓存里面查找,看看是否存在需要使用的数据;
- 如果没有找到,那么就创建一个满足要求的数据,然后把这个数据设置回到缓存中,以备下次使用;
- 如果找到了相应的数据,或者是创建了相应的数据,那就直接使用这个数据;
2.缓存的更新
具体的没有找到靠谱儿的,暂且可以理解为对Map的添加和删除
15.java中继承和多态
-
多态,就是多种状态,在具体点儿就是同一接口、多种不同的实现方式即为多态;
-
继承,继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力;
总而言之,多态可以总结为“一个接口,多种方法”,程序运行的过程中才决定调用哪个函数
16.java中覆盖和重载的概念
之前不确定覆盖和重写是否为同一个概念,现在确定了,实际上就是重写和重载的区别,略。
17.HashMap和Hashtable是否是线程安全的,他们内部机制是如何的
第一点比较好回答,前者不是线程安全的,后者是线程安全的。其中注意下这两个都是实现了的是Map接口(Hashtable也是实现的也是Map接口)。Hashtable中,key和value都不允许出现null值;在HashMap中,null可以作为键,但这样的键至多只有一个,可以有一个或多个键所对应的值为null。哈希值的使用不同,HashTable直接使用对象的hashCode,而HashMap重新计算hash值;HashMap未经同步,Hashtable是同步的,通过源码可以发现,Hashtable除构造方法外的所有public方法声明中都有synchronized关键字,而HashMap的源代码中则没有synchronized这个关键字。
总结:
- 他们都属于
Map接口,实现将唯一的键值映射到特定的value上; HashMap类没有分类或者排序,允许一个null键和多个null值;而HashTable则不允许null键和null值;- 两者都有
containsKey()和containsValue()方法;但是HashMap没有contains()方法,HashTbale中有contains()方法,该方法实际和containsValue()一样的功能; - 最大的不同是
HashTable是线程同步的,他的所有方法除构造方法外,都使用了synchronized关键字; - 两个遍历方式的内部实现上不同,
Hashtable、HashMap都使用了Iterator,而由于历史原因,Hashtable还使用了Enumeration的方式 。
18.递归的概念以及使用场景
妈的,这个最可气,当时知道啥意思,就是表达不出来,智商不够用了!!!
递归概念:递归简单的说就是自己调用自己,当边界条件不满足时,递归前进;当边界条件满足时,递归返回。
应用场景:
1.有5个人坐在一起,问第五个人多少岁?他说比第4个人大2岁。问第4个人岁数,他说比第3个人大2岁。问第三个人,又说比第2人大两岁。问第2个人,说比第一个人大两岁。最后问第一个人,他说是10岁。这时就可用递归来实现
2.删除指定路径下的文件夹里内容以及子文件夹以及子文件夹内容
19.Java如何实现序列化的
通过实现Serializable接口就好了。
【注意】声明为static和transient类型的成员数据不能被串行化。因为static代表类的状态, transient代表对象的临时数据。
要序列化对象,需要有如下流程:
- 必须先创建
OutputStream,然后把她嵌入到ObjectOutputStream,这时就能用writeObject()方法把对象写入OutputStream; - 读的时候需要把
InputStream嵌入到ObjectInputStream中,然后在调用readObject()方法,这样读出来的就是一个Object的reference,因此用之前还要先往下转。
对象序列化不仅能保存对象的副本,而且还会跟着对象中的reference把它所引用的对象也保存起来,然后再继续跟踪那些对象的reference,以此类推。
二:广联达视频面试,2017/09/06,时长58分钟,一面成功
(offer已拿)
2.1 HashMap与ConcurrentHashMap的区别
首先HashMap不是线程安全的,而ConcurrentHashMap是线程安全的。这里理解为什么ConcurrentHashMap是线程安全的,肯定不是在每个方法上加synchronized关键字,因为这和Hashtable没啥区别了。ConcurrentHashMap是引入了分段锁的概念,将Map分成各个Segment,put和get的时候都是根据key.hashCode()算出放到哪个Segment中。
2.2 SpringMVC的参数有哪些?
主要有如下的一些配置参数:@RequestMapping(value="映射路径",method=RequestMethod.POST/GET,produces={"application/json;charset=UTF-8"})
其中:
produces={"application/json;charset=UTF-8"}表示将功能处理方法将生产json格式的数据,此时根据请求头中的Accept进行匹配,如请求头“Accept:application/json”时即可匹配;就是你前台要是返回的是json,那就用这个;@ResponseBody用于读取Request请求的body部分数据,从前台获取指定的属性作为参数可以用在形参前面加上@RequestParam的注解即可,restful风格的占位符可以直接用形参{形参名}的方式去进行占位;
2.3 用charAt和for循环写一个子串在主串中出现的次数
当着面试官的面不好编呀,其实挺简单的一个小程序:
public static int getSubNumber(String str, String subStr) {
if(str.length() < subStr.length()) return 0;
int j = 0;
int count = 0;
for(int i = 0; i < str.length() - subStr.length() + 1; i++) {
if(str.charAt(i) == subStr.charAt(j)) {
while(j < subStr.length() && str.charAt(i) == subStr.charAt(j)) {
i++;
j++;
if(j == subStr.length()) {
count++;
j = 0;
}
}
}
j = 0;
}
return count;
}
2.4 数据库的索引有哪几种
索引的作用就是排好次序,使用查询时可以快速找到。
索引的优点:
- 大大加快数据的检索速度;
- 创建唯一性的索引,保证数据库库中每一行数据的唯一性;
- 加速表和表之间的连接;
- 在使用分组和排序子句进行数据检索时,可以显减少查询中分组和排序的时间;
索引的缺点:
- 索引需要占物理空间;
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态维护,降低了数维护的速度;
索引的几种分类:
- 唯一索引:MySQL数据库索引列的值必须唯一,但允许空值。如果是组合索引,则列值的组合必须唯一;
- 非唯一索引:在一个表上或多个字段组合建立的索引,这个或者这些字段的值组合起来在表中可以重复,不要求唯一;
- 主键索引:它是一种特殊的唯一索引,不允许有空值,一般是在建表时自动创建主键索引;
- 聚集索引(聚簇索引):表中记录的物理顺序与键值的索引顺序相同,一个表只能有一个聚集索引;
- 组合索引(联合索引):基于多个字创建的索引就是组合索引。
【注】:聚集索引和非聚集索引的根本区别是表中记录的物理顺序和索引的排列顺序是否一致。
2.5 设计模式:适配器和装饰者模式
略
2.6 Spring的常用注解
- 通用注解
@Component; - 持久层注解
@Repository; - 服务层注解
@Service; - 控制层注解
@Controller;
2.7 阶乘应该考虑哪些边界问题?
>=1;- 数据类型的考虑,会不会超限,
int可能超限,用String作为返回值比较合适;
2.8 MyBatis中传参的方式
- 单个参数传参可以直接用形参方式
#{形参}; - 多个参数可以用
HashMap,然后用#{键值}的方式可以取出指定的属性值,或者直接用序号#{0}、#{1}。。。
三:广州汇智通信
offer已拿
常规问题,参上,略
四:南京万得
offer已拿
常规问题,涉及部分操纵系统
AVL树:即平衡树,注意平衡树的概念,首先他必须是二叉搜索树(左小右大),然后节点的左右子树的高度差不超过1。
线程的五种状态以及之间的关系:
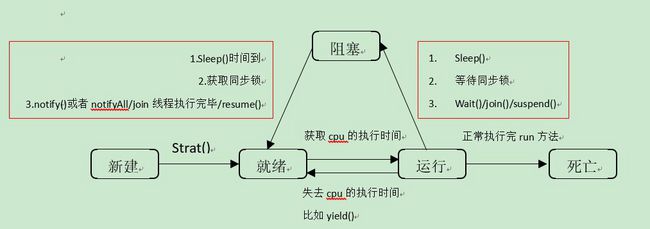
五:大华
二面被拒
5.1 红黑树和B树,其他问题
多路查找树:每个结点的孩子数可以多于两个,而且每个结点可以存储多个元素,这里稍微说一下多路查找树的四种特殊形式:2-3树、2-3-4树以及B树和B+树。
5.1.1 2-3树
2-3树是指树中的每个节点都具有2个孩子(称为2结点)或者3个孩子(称为3结点)。其中2结点包含一个元素和2个孩子或者没有孩子,与二叉搜索树相同的是两个孩子也是满足左小右大的原则的(以父节点为基准),但是它的要么没有孩子,要么有2个孩子,不能只有一个孩子。3结点也是类似的,包含2个元素和3个孩子结点或者没有孩子,要么没有孩子,要么有3个孩子,不能是其他情况,孩子们的顺序从到右也是一次变大的情况。2-3树中的叶子结点都在同一层上。
5.1.2 2-3-4树
2-3-4树就是上述2-3树的扩展,包含了4结点的使用。一个4结点包含3到4个元素和4个孩子或者没有,假设一个4结点我们有4个孩子,那么他们子树的分布是这样的,左子树包含小于4结点中最小元素的元素,第二子树包含大于4结点中最小元素且小于第二元素的元素,第三子树包含大于第二元素且小于最大元素的元素,右子树包含大于4结点中最大元素的元素。
5.1.3 B树
B树是一种平衡的多路查找树,上诉的2-3树和2-3-4树都是B树的特例,其中包含最大孩子数目的就称为B树的阶,如2-3树就是3阶B树、2-3-4树就是4阶B树。一颗m阶B树,有如下特性:
- 如果根节点不是叶节点,则至少有两棵子树;
- 每个非根的分支结点都有k-1个元素和k个孩子,其中m/2<=k<=m;
- 所有叶子结点都位于同一层;
5.1.4 B+树
通过中序遍历查找B树中的某一元素,我们往返与每个结点就意味着,必须要在硬盘的页面进行多次切换,这样的遍历方式麻烦,所以在B树结构上加上新的元素组织方式,形成B+树。
B+树和B树的区别在于:
- 有n棵子树的结点中包含n个关键字
- 所有的叶子结点包含全部关键字的信息
- 所有分支节点可以看成是索引,节点中仅含有其子树中最大(最小)关键字
5.2 红黑树
当插入节点时,要遵循红-黑规则,这时候插入的话树就是平衡的。红黑规则如下:(这里提一下平衡树的概念:一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树)。具备如下特性:
- 每个节点要么红色、要么黑色;
- 根节点总是黑色的;
- 如果节点是红色的,则她的子节点必须是黑色的(反之未必为真);
- 从根结点到叶节点或者空子节点(空子节点指的是一个有右子节点的节点的可能接左节点的位置,或者是有左子节点的节点可能接右子节点的位置,简单的说就是已经有一个子节点的父节点的另一个空着的自己子节点位置)的每一条路径必须包含相同数量的黑色节点(也称为黑色高度:从根结点到指定节点路径上黑色节点的数目);
如果红黑树的规则被违背了,那么就要执行修改操作,有两种方式修改:改变节点颜色、执行旋转操作,这里以右旋为例说明其中操作过程,左子节点移动到父节点位置,父节点移动到她的右子节点的位置,右子节点移动到下移。
在红黑树中插入节点的时候总是红色节点
还有一个问题(这个问题根没有试过,希望懂的同学帮忙解答)
两张表在不同的数据库中,一个涉及到两张表的事务如何保证在一张表更新数据的时候另一张表得到及时更新。
5.3 可重入锁
【定义】可重入锁以线程为颗粒度,持有锁的当前线程可以反复请求同一把锁,但非重入锁是以调用为颗粒度,同一线程无法多次请求同一把锁,将出现阻塞。常见的可重入锁有synchronized和ReentrantLock。
自旋锁:当一个线程在获取锁时,如果锁已经被其他线程获取,那该线程将循环等待,不断的判断锁是否可以被成功获取,直到获取到锁才会退出循环,获取锁的线程一直处于活跃状态,但并没有执行有效的任务,这样的锁会造成busy-waiting。
5.4 线程
5.4.1 直接调用run()方法和start()方法的区别
start():start()方法是线程启动的正确方式,会另起一个线程去执行;run():如果直接调用run()方法则和普通方法没有区别,是单线程顺序执行,不会额外起线程去执行,是启动线程的错误方式;
5.4.2 线程通信
t.join()的内部实现:首先这个方法会让当前线程停下来然后执行t线程,等 t 线程执行完毕后才可以继续执行当前线程。join()方法的实现是通过wait()方法实现的,具体源码实现如下:
public final void join() throws InterruptedException {
join(0);
}
/** * 该方法上增加了synchronized关键字,表示使用的是this对象(即当前对象)作为锁 * * @see Throwable#printStackTrace() */
public final synchronized void join(long millis)
throws InterruptedException {
long base = System.currentTimeMillis();
long now = 0;
if (millis < 0) {
throw new IllegalArgumentException("timeout value is negative");
}
// 会一直等待至调用方全部执行完毕处于非存活状态
if (millis == 0) {
while (isAlive()) {
wait(0);
}
} else {
// 如果调用方还处于存活状态,会等待指定时间,如果超过这个时间就停止等待
while (isAlive()) {
long delay = millis - now;
if (delay <= 0) {
break;
}
wait(delay);
now = System.currentTimeMillis() - base;
}
}
}
5.4.3 static方法可不可以加锁,有何区别
static静态方法可以加锁,而且静态方法加锁后,获取的类锁(也叫全局锁,static synchronized),针对的是类级别,只要是这个类实例化出来的对象,线程共享
static方法加锁后,不能交替执行,只能是某一个线程执行完毕后释放锁后另一个线程才能开始获得锁开始执行
5.4.4 notify()如何实现,如果不设置优先级别,会通知哪个线程
通常wait()会和notify()或notifyAll()配合使用,当一个线程调用了某个对象的wait()方法,它就会变为非运行状态,直到另一个线程调用了同一对象的notify()或notifyAll()方法,这个过程中,为了调用wait()、notify()或notifyAll()方法必须持有那个对象的锁,即线程必须在同步块或同步方法中去调用上述的几个方法(这种调用方式是强制的),如果一个线程没有持有对象锁,将不能调用上述的方法,否则会出现IllegalMonitorStateException。
在调用某个对象A的notify()方法时,将正在等待该对象A的所有线程中的一个唤醒并执行,具体是哪个线程被唤醒,这个是随机的且不可指定;notifyAll()则是唤醒所有等待A对象的线程,但同一时刻也只有一个线程可以退出wait(),因为每个线程在退出wait()时必须获得监视器的A锁。结合上述可以理解为什么wait()方法会释放锁,如果不释放锁,那其他线程中将获取不到锁(A对象),那也就无法调用notify()或者notifyAll()方法来唤醒调用wait()的线程,那它将永远在wait()。
5.4.5 可重入锁的概念和机制
ReentrantLock
5.4.6 4个线程计算,1个线程总和,代码实现
我在回来的路上简单做了个简单的模拟,代码如下:
// 计算的磁盘
public class DiskMemory {
private int memory;
private int total;
public int getMemory() {
return (new Random().nextInt() % 10 + 1);
}
public void setMemory(int memory) {
total += memory;
}
public int getTotal() {
return total;
}
}
// 计算的Runnable
public class CountRunnable implements Runnable {
private DiskMemory dm;
private CountDownLatch count;
@Override
public void run() {
int memory = dm.getMemory();
System.out.println(Thread.currentThread().getName() + "'memory: " + memory);
// 这里为了让并发写表现得更明显,睡眠1s
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (this) {
dm.setMemory(memory);
}
count.countDown();
}
CountRunnable(DiskMemory dm, CountDownLatch count) {
this.dm = dm;
this.count = count;
}
}
// 测试类
DiskMemory dm = new DiskMemory();
CountDownLatch count = new CountDownLatch(4);
CountRunnable countRunnable = new CountRunnable(dm, count);
for (int i = 0; i < 4; i++) {
Thread t = new Thread(countRunnable);
t.start();
}
count.await();
System.out.println("total: " + dm.getTotal());
5.5 MyBatis中Mapper的接口是否可以重载
不可以,MyBatis中mapper对应的xml中,定位方法的方式是通过xml中的 namespace + 增删改查标签中的id(即select/delete/update/insert标签中的id)决定的,所以方法名不能相同。
5.6 MySQL中支持事务的引擎
常见的存储引擎有:innodb、bdb、myisam 、memory,其中只有红色标出的引擎才支持事务操作。
六:中兴
(offer已拿)
两轮面试都是常规性的面试,对于中兴的面试体验来将,虽然专业面的时候面试官的普通话不怎么标准,但是给我印象很好,问了一些基础性的问题,关于Linux中的一些常规的指令,起先,记录的小哥在旁边小声跟我讲不要紧张,最后面试官特地起身跟我握手,感觉聊的不错,二面的时候,面试官一男一女,男面试官全程拉着脸,让应聘的我很不爽,全程盯着你怼。一个问题问你好几遍,之前都回答过了,能用点心听吗?对这名面试官有着极差的印象,女面试官还好。
七:烽火星空
offer已拿
1.数据库死锁问题,如何解决?
2.最短路径算法,图的遍历
八:河狸家
莫名奇妙被拒,这是我见过的最坦诚的面试官,上来直接问技术,面完了问了我一句,你叫什么名字,搞得我思路不太跟得上,哈哈~~
1.如何保证数据库中更新的数据不会出现库存-1的情况?
答:因为多个用户进行秒杀的时候,用户1进行库存减一操作前,用户2读到了库存为1的情况,那用户1进行库存减一操作后,用户2还要重新读取库存吗?虽然当时谈到了行级锁,但这不是面试官想要的,后来请教他,说可以从两方面进行考量,一个是用悲观锁,而是用乐观锁(利用时间戳或者版本号进行判断有没有更更新)
2.若要对某一个类的集合进行排序,而该类不支持排序,咋办?
- 可以建立比较器进行排序,创建比较器实现
Comparator接口即可,可以重写compare()和equals()方法,然后比较Collections.sort(list, new PriceComparator()); - 让对应的类实现
Comparable接口,重写compareTo(T o)方法即可,然后使用Collections.sort(list);
3.ConcurrentHashMap和Hashtable你会选用哪一个?
我蒙的是Hashtable,原因回来再更,要赶下一场的笔试了
九:合合信息
(超级想去的一家公司,offer已拿,1.1倍的工资苏州不给,所以黄了)
这家公司真的不一样,基础的根本没有问,直接从项目聊,技术性太强了,跟不上,分布式这类的东西。
1.递归会有引起什么问题
【解答】
递归算法的代码很简洁。但同时也存在缺点。
1.递归由于函数要调用自身,而函数调用是有时间和空间的消耗的。每一次函数调用,都需要在内存栈中分配空间以保存参数、返回地址及临时变量,而且往栈里压入数据和弹出数据都需要时间。
2.递归有可能很多计算都是重复的,从而对性能带来很大的负面影响。递归的本质是把一个问题分解成两个或者多个小问题。如果小问题有重叠的部分,那么就存在重复的计算。
3.除了效率外,递归还可能存在调用栈溢出的问题。前面提到的每一次函数调用在内存栈中分配空间,而每个进程的栈容量是有限的。当递归调用的层级太多时,就会超出栈的容量,从而导致调用栈溢出。
下面以拿斐波那契(Fibonacci)数列来做例子。如果现在让你以最快的速度用java写出一个计算斐波那契数列第n个数的函数(不考虑参数小于1或结果溢出等异常情况):
public static int Fib(int n) {
return (n == 1 || n == 2) ? 1:Fib(n - 1) + Fib(n - 2);
}
这段代码应该算是短小精悍,直观清晰。但如果用这段代码试试计算Fib(1000)就再也爽不起来了,它的运行时间也许会让你抓狂。
看来好看的代码未必中用,如果程序在效率不能接受那美观神马的就都是浮云了。如果简单分析一下程序的执行流,就会发现问题在哪,以计算Fibonacci(5)为例:

在计算Fib(5)的过程中,Fib(1)计算了两次、Fib(2)计算了3次,Fib(3)计算了两次,本来只需要5次计算就可以完成的任务却计算了9次。这个问题随着规模的增加会愈发凸显,以至于Fib(1000)已经无法再可接受的时间内算出。
我们当时使用的是简单的用定义来求 fib(n),也就是使用公式 fib(n) = fib(n-1) + fib(n-2)。这样的想法是很容易想到的,可是仔细分析一下我们发现,当调用fib(n-1)的时候,还要调用fib(n-2),也就是说fib(n-2)调用了两次,同样的道理,调用f(n-2)时f(n-3)也调用了两次,而这些冗余的调用是完全没有必要的。可以计算这个算法的复杂度是指数级的。
改进的斐波那契递归算法
那么计算斐波那契数列是否有更好的递归算法呢? 当然有。让我们来观察一下斐波那契数列的前几项:
1
1, 1, 2, 3, 5, 8, 13, 21, 34, 55 …
如果去掉前面一项,得到的数列依然满足f(n) = f(n-1) – f(n-2), (n>2),而我们得到的数列是以1,2开头的。很容易发现这个数列的第n-1项就是原数列的第n项。可以写这样的一个函数,它接受三个参数,前两个是数列的开头两项,第三个是我们想求的以前两个参数开头的数列的第几项。
int fib_i(int a, int b, int n);
在函数内部先检查n的值,如果n为3则我们只需返回a+b即可,这是简单情境。如果n>3,那么就调用f(b, a+b, n-1),这样就缩小了问题的规模(从求第n项变成求第n-1项)。好了,最终代码如下:
int fib_i(int a, int b , int n) {
if(n == 3)
return a+b;
else
return fib_i(b, a+b, n-1);
}
这样得到的算法复杂度是O(n)的。已经是线性的了。它的效率已经可以与迭代算法的效率相比了,但由于还是要反复的进行函数调用,还是不够经济。
递归与迭代的效率比较
递归调用实际上是函数自己在调用自己,而函数的调用开销是很大的,系统要为每次函数调用分配存储空间,并将调用点压栈予以记录。而在函数调用结束后,还要释放空间,弹栈恢复断点。所以说,函数调用不仅浪费空间,还浪费时间。
这样,我们发现,同一个问题,如果递归解决方案的复杂度不明显优于其它解决方案的话,那么使用递归是不划算的。因为它的很多时间浪费在对函数调用的处理上。在C++中引入了内联函数的概念,其实就是为了避免简单函数内部语句的执行时间小于函数调用的时间而造成效率降低的情况出现。在这里也是一个道理,如果过多的时间用于了函数调用的处理,那么效率显然高不起来。
举例来说,对于求阶乘的函数来说,其迭代算法的时间复杂度为O(n):
public int fact(n){
int i;
int r = 1;
for(i = 1; i < = n; i++) {
r *= i;
}
return r;
}
而其递归函数的时间复杂度也是O(n):
int fact_r(n) {
if(n == 0)
return 1;
else
return n * f(n);
}
但是递归算法要进行n次函数调用,而迭代算法则只需要进行n次迭代而已。其效率上的差异是很显著的。
小结
由以上分析我们可以看到,递归在处理问题时要反复调用函数,这增大了它的空间和时间开销,所以在使用迭代可以很容易解决的问题中,使用递归虽然可以简化思维过程,但效率上并不合算。效率和开销问题是递归最大的缺点。
虽然有这样的缺点,但是递归的力量仍然是巨大而不可忽视的,因为有些问题使用迭代算法是很难甚至无法解决的(比如汉诺塔问题)。这时递归的作用就显示出来了。
2.group by和order by的区别
2.1使用order by,一般是用来,依照查询结果的某一列(或多列)属性,进行排序(升序:ASC;降序:DESC;默认为升序)。
当排序列含空值时:
ASC:排序列为空值的元组最后显示。
DESC:排序列为空值的元组最先显示。
为了好记忆,可以把null值看做无穷大,因为不知道具体为多少。然后去考虑排序,asc升序null肯定在最后,而desc降序,null肯定在最前面。
单一属性排序:
如根据s表中的sno属性降序排列
select * from s order by sno desc
多列属性排序
选择多个列属性进行排序,然后排序的顺序是,从左到右,依次排序。
如果前面列属性有些是一样的话,再按后面的列属性排序。(前提一定要满足前面的属性排序,因为在前面的优先级高)。
如将表中记录按照sname降序,满足这个前提的情况下,再按照sage的降序排序,前面的优先级要比后面要高。若sname相同,那么就按照sage的降序排序即可,否则只要满足按sname降序排列即可。
select * from s order by sname desc, sage desc
2.2group by按照查询结果集中的某一列(或多列),进行分组,值相等的为一组。
3.联合索引
十.华三
一面被拒
1.Hibernate中的Session是如何共享的?
2.JVM中的CCS
3.平衡树的平衡过程
3.1平衡二叉树的构造
在一棵二叉查找树中插入结点后,调整其为平衡二叉树。若向平衡二叉树中插入一个新结点后破坏了平衡二叉树的平衡性。首先要找出插入新结点后失去平衡的最小子树根结点的指针。然后再调整这个子树中有关结点之间的链接关系,使之成为新的平衡子树。当失去平衡的最小子树被调整为平衡子树后,原有其他所有不平衡子树无需调整,整个二叉排序树就又成为一棵平衡二叉树
3.2调整方法
- 插入点位置必须满足二叉查找树的性质,即任意一棵子树的左结点都小于根结点,右结点大于根结点;
- 找出插入结点后不平衡的最小二叉树进行调整,如果是整个树不平衡,才进行整个树的调整;
下面是具体调整方式:
(1)LL型
LL型:插入位置为左子树的左结点,进行向右旋转(LL表示的是在做子树的左结点进行插入)

(2)RR型
RR型:插入位置为右子树的右孩子,进行向左旋转

(3)LR型
LR型:插入位置为左子树的右孩子,要进行两次旋转,先左旋转,再右旋转;第一次最小不平衡子树的根结点先不动,调整插入结点所在的子树,调整后的树变成LL型树,第二次再调整最小不平衡子树(根据LL型的调整规则,调整为平衡二叉树)。
由于在A的左子树B的右子树上插入了结点F,A的平衡因子由1变为了2,成为不平衡的最小二叉树根结点。第一次旋转A结点不动,先将B的右子树的根结点D向左上旋转提升到B结点的位置,然后再把该D结点向右上旋转提升到A结点的位置。
(4)RL型
RL型:插入位置为右子树的左孩子,进行两次调整,先右旋转调整为RR型,再左旋转,从RR型调整到平衡二叉树;处理情况与LR类似。

(5)RR型:插入位置为右子树的右孩子,进行向左旋转
由于在A的右子树C的右子树插入了结点F,A的平衡因子由-1变为-2,成为不平衡的最小二叉树根结点。此时,A结点逆时针左旋转,遵循“旋转优先”的规则,A结点替换D结点成为C的左子树,D结点成为A的右子树。
总结:RR型和LL型插入导致的树失去平衡,只需要做一次旋转调整即可。而RL型和LR型插入导致的结点失去平衡,要调整两次。对于RL/LR的调整策略是: 第一次调整,最小不平衡子树的根结点先不动,调整插入结点所在的子树(这个子树是指最小不平衡结点的一颗子树,且这棵子树是插入结点的子树)为RR型或者LL型,第二次再调整最小不平衡子树(调整策略要么是RR型要么是LL型)。
4.找出字符串中的字母空格以及数字的个数。
//比较low的写法,觉得用正则会好很多
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String str = sc.nextLine();
getNum(str);
}
public static void getNum(String str) {
int count1 = 0;
int count2 = 0;
int count3 = 0;
for(int i=0;i='a'&&str.charAt(i)<='z')||(str.charAt(i)>='A'&&str.charAt(i)<='Z')) {
count1++;
}
if(str.charAt(i)>='0'&&str.charAt(i)<='9') {
count2++;
}
if(str.charAt(i)==' ') {
count3++;
}
}
System.out.println("count1 = " + count1);
System.out.println("count2 = " + count2);
System.out.println("count3 = " + count3);
}
}
十一.中科创达
offer已拿
1.static的含义,意义。
- 修饰成员变量;
- 修饰成员方法;
- 修饰静态代码块;
被修饰的变量和成员方法是被这个类的所有实例共享的。static对象可以在他的任何对象创建之前访问,无需引用任何对象,静态方法和静态变量可以通过类名直接访问。静态代码块在JVM加载类的时候,会执行静态代码块,如果有多个static代码块,JVM将按照定义的顺序依次执行;
其他的忘了,时间太长了,面试我的是总监,hr面试直接省了,人挺好的
十二.群硕
不去了,面试官看着像个小混混
1.操作系统中的进程是什么?
进程就是运行中的程序,它是线程的载体。进程有3大特性:
- 动态性:在程序运行的过程中,它的状态是一直变化的;
- 独立性:每个进程都是一个独立的实体,是计算机系统资源的使用单位,每个进程都有自己的寄存器和内部状态;
- 并发性:对于单个cpu而言,宏观上每个进程是同时运行的,而实际上就某一个具体的时刻而言,是只有一个进程在运行的;
进程拥有3中状态:就绪状态、执行状态、阻塞状态,之间的状态切换可以是:就绪–>执行–>阻塞/就绪;阻塞–>运行
2.多线程的效率是否一定比单线程要高?为什么,举例说明。(可以完美回答的同学可以留言)
这个问题的答案是否定的,多线程未必就比单线程运行高效。一般那情况下,处理时间短的服务或者启动频率高的用单线程,否则用多线程(只有在需要响应时间要求比较高的情况下,或者某种操作允许并发而且可能发生阻塞时,用多线程,比如socket和磁盘操作等);在单个CPU的情况下,多线程的出现是为了提高cpu的效率,在一个线程执行等待结果的时候,此时cpu是处于等待的状态,那么这个时候其他线程可以利用cpu这段空闲时间去做其他的事情。但是多线程的场景下,线程之间的切换是有代价的,但对于用户来说,可以减少响应时间。
3.在浏览器中输入网址访问,这一过程用到哪些协议?
比如访问:http://www.cfca.com.cn/chanpin/chanpin.htm,它的各部分含义如下:
- http:代表访问该资源所使用的应用层传输协议,通知cfca.com.cn服务器显示web网页;
- www 代表一个Web(万维网)服务器 cfca.com.cn这时装有网页服务器的域名,或站点服务器的名称;
- chanpin:这是该服务器上的某个路径,就好像我们的文件夹 chanpin.htm 这是文件夹中的一个HTML文件(网页);
- 域名解析协议:通过域名找出IP,DNS查找如下:首先查找浏览器缓存(浏览器会缓存DNS一段时间);
- 浏览器和服务器cfca.com.cn建立TCP链接:三次握手;
- 浏览器开始HTTP访问;
- 断开TCP链接:四次挥手;
4.IP是用来干嘛的?
IP就像是家庭住址一样,要给一个人写信,必须知道他家的地址呀
5.普通的方法和static方法都加上synchronized关键字有啥区别?
&esmp;非静态方法加synchronized关键字加锁的范围是一个类的对象/实例,防止多线程同时访问这个对象的synchronized代码块;而静态方法加synchronized关键字表示的范围是一个类,防止多线程同时访问这个类的synchronized代码块。
十三.努比亚
等待消息,被拒
1.Spring中的AOP和IOC,和传统的方式有哪些优势?AOP如何实现?
AOP和IOC是Spring的两个核心功能,介绍如下:
- AOP:面向切面编程,可以实现横切关注点,业务的主要流程是横切关注点,与业务关系不大的部分就是横切关注点,它经常发生在核心关注点的多处,而且基本相似,比如权限认证、日志、事务管理等;
- IOC:控制反转,也叫依赖倒置。比如A方法需要调用B,那么一般需要A自己去创建B这个对象,现在不必了,需要B的时候其他人会主动把B送给A,这样的方式实现了对象之间的解耦。这里比如你是用户,现在需要水,正常情况下,你要依赖小电驴开到超市去买水,这个需求的本质就是你和你需要的水,但是这中间需要依赖车或者其他一些工具;但是Spring现在给我们提供了另一种方式来完成这件事情,你需要做的只有两个事情:在超市注册用户信息,当你需要水的时候告诉超市,超市会主动将你需要的水送给你;
下面看代码:
第一:在Spring中声明一个类:A(注册会员)
第二:告诉Spring,A需要B
假设A是UserAction类,而B是UserService类
<bean id="userService" class="org.leadfar.service.UserService"/>
<bean id="documentService" class="org.leadfar.service.DocumentService"/>
<bean id="orgService" class="org.leadfar.service.OrgService"/>
<bean id="userAction" class="org.leadfar.web.UserAction">
<property name="userService" ref="userService"/>
bean>
在Spring这个商店(工厂)中,有很多对象/服务:userService,documentService,orgService,也有很多会员:userAction等等,声明userAction需要userService即可,Spring将通过你给它提供的setter方法userService送上门来,因此UserAction的代码示例类似如下所示:
public class UserAction{
private UserService userService;
public String login(){
userService.valifyUser(xxx);
}
public void setUserService(UserService userService){
this.userService = userService;
}
}
2.Java注解原理
java注解是从5.0版本引入,注解用一个词就可以描述注解,那就是元数据,即一种描述数据的数据。像用的比较多的对一个对象重写toString方法,会加上@Override的注解,但是不难发现即使不加这个注解也不会报错,那么加这个注解有什么用呢?这个注解告诉编译器这个方法是个重写的方法,如果父类中没有这个方法加了这个注解就会报错,比如无意间将toString写成了toStrring,如果不加这个注解不会报错,程序照常运行,但是当我们真正调用toString的时候,结果会和我们期盼的相差很远。
Annotation是一种应用于类、方法、参数、变量等的特殊修饰符。Annotation的机制
3.ajax原理
十四. 上海银行
重点从项目着手开始问问题,面试官人都挺好,常规
好了,最终签了广联达,祝愿后来者,此博文停更。