MASK-RCNN阅读笔记
2017:Mask R-CNN - 扩展 Faster R-CNN 以用于像素级分割
背景
何凯明的这篇大作是想像Fast/Faster-RCNN,FCN做为检测任务与分割任务的基础框架那样,将MASK-RCNN做为实例分割的基础框架。
由于既要求检测出图像中的每个物体,又要求分割出每一个实例,这里有可能一类物体同时出现多个实例,这样就会使问题的难度增加,因此实例分割是一项非常有挑战性的任务。
本文的方法是在Faster R-CNN的基础上,增加一个预测分支,这个分支主要是在RoI上进行分割任务。与原来的分类与bounding box的回归任务平行。
掩码分支是一个小的FCN,对每一个ROI生成一个像素级别的掩码。
在给定Faster R-CNN的架构后,MASK-RCNN的实施训练非常简单,而且适用于很多灵活的架构。
另外这个掩码分支计算代价很小,保证了系统的实时性。
重要的一点Faster R-CNN不是像素到像素的网络结构,有力的证据就是ROI pool的时候,特征提取的空间量化比较粗糙。为了弥补这个缺陷,本文提出一种简单不必量化的层,RoIAlign,能够很好的保持空间位置信息。
虽然看起来改变很小,但是RoIAlign的作用确是巨大的:它提升了mask的准确率10%-50%,在严格的定位方面具有更大的优势;第二,本文发现将分类与分割分开是很有必要的。
本文给每一个类别预测一个二值的掩码,基于ROI分类的分支来预测所属类别。形成对比的是FCN,通常解决像素级别的多类分割任务,但是在实例分割中表现却一般。
Mask R-CNN介绍
在原有Faster R-CNN的基础上增加掩码预测分支,如下图所示:
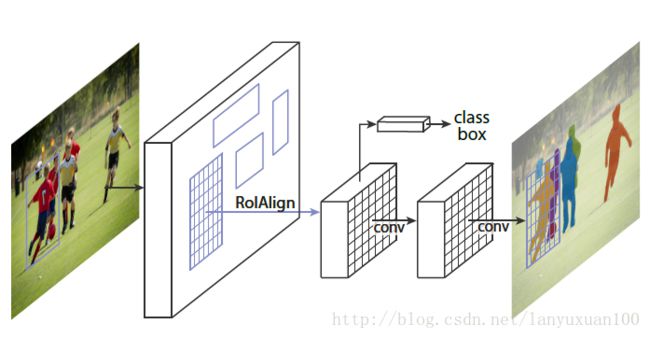
目标掩码与已有的class和box输出的不同在于它需要对目标的空间布局有一个更精细的提取。
因为原有的Faster R-CNN架构缺少精细的像素对齐,故此Mask R-CNN进行了一定程度的弥补。
Mask R-CNN工作原理
Mask R-CNN主要分为两个阶段:
(1)生成候选框区域。该流程与Faster R-CNN相同,都是使用的RPN(Region Proposal Network)。
(2)在候选框区域上使用RoIPool来提取特征并进行分类和边界框回归,同时为每个RoI生成了一个二元掩码。
这与当前大部分系统不一样,当前这些系统的类别分类依赖于 mask 的预测。我们还是沿袭了 Fast R-CNN 的精神,它将矩形框分类和坐标回归并行的进行,这么做很大的简化了R-CNN的流程。
注释:掩码将一个对象的空间布局进行了编码,与类标签或框架不同的是,Mast R-CNN可以通过卷积的像素对齐来使用掩码提取空间结构。

图像实例分割的目的是在像素级场景中识别不同目标。
到目前为止,我们已经懂得如何以许多有趣的方式使用 CNN,以有效地定位图像中带有边框的不同目标。
我们能进一步扩展这些技术,定位每个目标的精确像素,而非仅限于边框吗?这个问题被称为图像分割。Kaiming He 和一群研究人员,包括 Girshick,在 Facebook AI 上使用一种称为 Mask R-CNN 的架构探索了这一图像分割问题。
在 Mask R-CNN 中,在 Faster R-CNN 的 CNN 特征的顶部添加了一个简单的完全卷积网络(FCN),以生成 mask(分割输出)。请注意它是如何与 Faster R-CNN 的分类和边界框回归网络并行的。
Mask R-CNN 通过简单地向 Faster R-CNN 添加一个分支来输出二进制 mask,以说明给定像素是否是目标的一部分。如上所述,分支(在上图中为白色)仅仅是 CNN 特征图上的简单的全卷积网络。以下是其输入和输出:
输入:CNN 特征图。输出:在像素属于目标的所有位置上都有 1s 的矩阵,其他位置为 0s(这称为二进制 mask)。
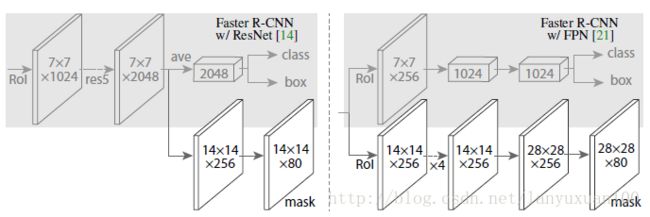
但 Mask R-CNN 作者不得不进行一个小的调整,使这个流程按预期工作。
RoiAlign——重对齐 RoIPool 以使其更准确
RoIPool对齐不准确的原因:
在RoIPool的处理流程中,需要根据前面提前特征的stride来对ROI进行同样比例的缩放,以便找到在当前的特征图中ROI所对应的区域。这里以stride = 16为例,以x来表示ROI在原图中的坐标,那么在特征图中对应的位置就使用[x/stride]即[x/16]来表示。取整所引入的位置误差与前面提前特征所进行的缩放比例有关,且比例越大,误差越大。
在目标检测中,给出的bounding box与原图有一些误差也不影响分类检测的结果;但是在像素级别的图像分割中,这样的空间位置误差,会严重影响分割结果。因此本文提出使用双线性插值来解决这一问题,即RoIAlign.
图像通过 RoIAlign 而不是 RoIPool 传递,使由 RoIPool 选择的特征图区域更精确地对应原始图像的区域。这是必要的,因为像素级分割需要比边界框更细粒度的对齐。
当运行没有修改的原始 Faster R-CNN 架构时,Mask R-CNN 作者意识到 RoIPool 选择的特征图的区域与原始图像的区域略不对齐。因为图像分割需要像素级特异性,不像边框,这自然地导致不准确。
作者通过使用 RoIAlign 方法简单地调整 RoIPool 来更精确地对齐,从而解决了这个问题。
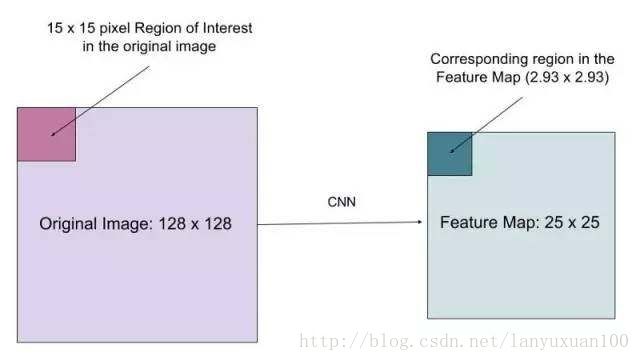
假设我们有一个尺寸大小为128x128的图像和大小为25x25的特征图谱。如果我们想要在特征图谱中表示原始图像中左上角15x15像素的区域,该如何从特征图中选择这些像素?
我们知道原始图像中的每个像素对应于特征图谱中的25/128个像素。要从原始图像中选择15像素,我们就在特征图谱中选择15*(25/128)=2.93个像素。
在RoIPool中,我们会舍弃小数点后的部分,只选择2个像素,导致轻微的错位。然而,在RoIAlign中,我们避免了这样的舍弃。相反,我们使用双线性插值来精确地得到这2.93像素中的信息。这样子在很大程度上避免了RoIPool方法造成的像素错位。
Mask R-CNN在生成这些掩码后,将它们与Faster R-CNN输出层的对象类别和边界框组合起来,产生了奇妙的精确分割。

RoIPool 是一个标准的提特征运算,它从每个 RoI 提取出一个小的特征( 7×7),RoIPool 首先对浮点的 RoI 进行量化,然后再提取分块直方图,最后通过 最大池化 组合起来。这种分块直方图对于分类没有什么大的影响,但是对像素级别精度的 mask 有很大影响。
多任务loss
在训练阶段,我们对每个样本的 RoI 定义了多任务损失函数 L = L_cls + L_box + L_mask ,其中 L_cls 和 L_box 的定义和Fast R-CNN 是一样的。在 mask 分支中对每个 RoI 的输出是 K*m*m,表示K个 尺寸是 m*m的二值 mask,K是物体类别数目,。这里我们使用了 per-pixel sigmoid,将 的损失函数定义为 L_mask average binary cross-entropy,我们的 L_mask 只定义对应类别的 mask损失,其他类别的mask输出不会影响该类别的 loss。
我们定义 L_mask 的方式使得我们的网络在生成每个类别的 mask 不会受类别竞争影响,解耦了mask和类别预测。
3.1. Implementation Details
Training: 对于 mask loss L_mask 只在正样本的 RoIs 上面定义。
我们采用文献【9】的图像-中心 训练方法。将图像长宽较小的一侧归一化到 800个像素。在每个 mini-batch 上每个 GPU 有2个图像,每个图像 N个样本 RoIs,正负样本比例 1:3.其中 对于 C4 框架的 N=64, 对 FPN框架的 N=512。在8个GPU上训练,还有其他一些参数设置。
Inference: 在测试阶段,C4的候选区域个数是300, FPN 是 1000.对这些候选区域我们进行坐标回归,再非极大值抑制。然后对前100个得分最高的检测框进行 mask 分支运算。这样做可以提高速度改善精度。在 mask 分支中 ,我们对每个 RoI 给出 K 个 mask预测,但是我们只使用 分类分支给出的那个类别对应的 mask。然后我们将 m×m 浮点 mask 归一化到 RoI 尺寸,使用一个0.5阈值进行二值化。
human pose estimation:

1.R-CNN:https://arxiv.org/abs/1311.2524
2.Fast R-CNN:https://arxiv.org/abs/1504.08083
3.Faster R-CNN:https://arxiv.org/abs/1506.01497
4.Mask R-CNN:https://arxiv.org/abs/1703.06870
以及文中提到的选择性搜索:
http://www.cs.cornell.edu/courses/cs7670/2014sp/slides/VisionSeminar14.pdf