BERT模型
1、背景
语言模型的与训练在自然语言处理的任务中有着重要的作用。
1.1 自然语言处理的任务
a.句子层面(sentence-level)=>判断句子之间的关系
- 自然语言推理(natural language inference)
- 自然语言改写(natural language paraphrasing)
b.词层面(token-level)
- 命名实体识别(named entity recognition)
- 知识问答(SQuADquestion answering)
1.2 目前将预训练表示(pre-trained representations)用到自然语言处理任务策略
a.基于特征的方法(feature-based),将预训练的表示向量作为额外特征(作为输入),利用任务相关模型
b.基于微调的方法(fine-tuning),通过引入少量与任务相关的参数,将预训练的表示向量在模型训练过程的同时进行微调
1.3 现状与局限
目前预训练表示(pre-trained representations)的方法都是单向语言模型。也就是说每个词只能利用该词之前的词信息进行训练,这样的约束条件严重限制了pre-trained representations的表示能力。这样得到的pre-trained representations,对于sentence-level的自然语言任务,将会得到局部最优解;而对于token-level的自然语言任务,将会是毁灭性的灾难。因此,本文提出的BERT模型来解决上述约束。并且BERT是一个MASK model。BERT将随机的mask输入序列的词,目标就是利用上下文信息(相对于传统自左向右的语言模型,mask model可以同时使用masked词左右上下文进行预测)预测被mask的词。同时利用masked左右的上下文信息是通过Transformer的双向encoder来实现。这样既可以解决“语言模型是单向的”限制。此外,BERT模型引入“预测是否为下一句”的任务,来共同学习pre-trained representations。因此,BERT pre-trained representations的目标就是同时预测被mask的词是什么和预测句子对是否为“下一句”的关系。
1.4 BERT贡献
a.BERT利用masked model实现了语言模型的双向性,证明了双向性对语言表示预训练的重要性。如下图,传统的方法如OpenAI GPT是单向语言模型,每个词只能用到该词左边的词信息进行学习(RNN时间序列模型);ELMo是利用双向LSTM,将一层left-to-right 和right-to-left两个单独的LSTM进行结合;而BERT模型是真正意义上的双向语言模型,每个词可以同时利用该词的上下文信息。
b.BERT是第一个微调模型在sentence-level和token-level自然语言任务都达到了最好效果。证明了pre-trained representations可以缓解了不同任务对特殊模型结构的设计需求。
c.BERT在11个自然语言处理任务上达到了最好效果。并在BERT的extensive ablations证明了“BERT的双向性”是一个重要的创新。代码在 goo.gl/language/bert

2.BERT模型
2.1模型结构
BERT模型是一个多层的Transformer,具体Transformer模型结构见,一下模型结构根据代码可得
- embedding层:将input_id转化为word embedding
- embedding_processor层:word embedding + position embedding(和Transformer一致) +segment embedding(BERT模型创新)
- Transformer层
BERT-base: L=12, H=768, A=12, Total Parameters=110M
BERT-large: L=24, H=1024, A=16, TotalParameters=340M
BERT-base为了和OpenAI GPT进行对比,所以模型大小与OpenAI GPT设置一致。不同的在于OpenAI GPT使用left-to-right的self-attention,而BERT使用双向self-atten
2.2 输入表示(Input Representation)
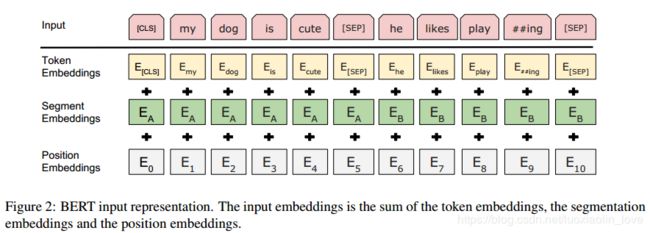
无论是单个文本还是文本对,输入都是一个token sequence。其中[CLS]表示sequence的开始,[SEP]表示两个文本的分割。输入向量是由词向量,位置向量和分割向量构成的,如下图:
input embedding= word embedding+ position embedding + segment embedding
- word embedding用的是WordPiece embeddings,包含30000tokens
- position embedding是学习得到的,支持最长序列长度为512个tokens
- [CLS]的隐状态的输出,对于分类问题,可以作为sequence的表示;对于非分类问题,则忽略
- 句子pair也用一个sequence进行输入。a.利用[SEP]作为两个句子的区分;b.segment embedding可以区分两个句子;对于一个句子的输入,可以只用segment embedding A
2.3 预训练任务
2.3.1 Task #1: Masked LM
理论上深度双向模型应该比浅层模型和单向模型的效果好。因为当多层context信息被利用,每个词将会"看到自己",所以标准的语言模型只能单向训练.Unfortunately, standard conditional language models can only be trained left-to-right or right-to-left, since bidirectional conditioning would allow each word to indirectly “see itself” in a multi-layered context.
为了解决上述问题,采用一种直接的方法。将输入序列按照一定的概率,随机的mask token。本文采用15%的概率进行mask。例如:token(my dog is hairy 选择hairy。但这样做存在两个缺点:
缺点1:由于[mask]在fine-tuning过程中没有遇到过,使得Pre-trainning和fine-tuning过程不匹配
解决1:
•80%情况下用[mask]代替 :my dog is hairy ->my dog is [MASK]
•10%情况下用错误的词代替: my dog is hairy -> My dog is apple
•10%的情况下用正确词代替: my dog is hairy -> my dogis hairy
缺点2:每个batch只有15%的词被训练到->需要更多次的训练
2.3.2 Task #2: Next Sentence Prediction
由于pre-trainning Representation的应用大多是知识问答或者自然语言推理这种判断句子之间关系的任务。因此,本文采用预测“是否为下一句”的任务。
训练任务:句子B是否为句子A的下一句
训练数据:
•50%情况下句子B为句子A的下一句
•50%情况下句子B是从语料库中随机选取的一句

最终,预训练的目标函数是:最小化(“预测masked词”的损失+“预测是否为下一句”的损失)
2.4微调过程
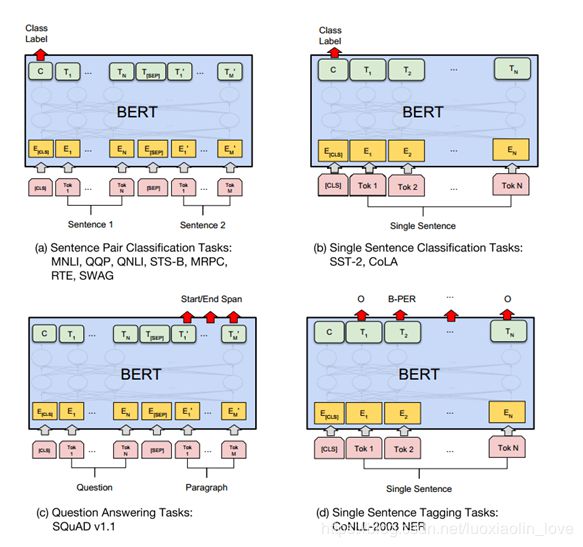
分类任务:利用Transformer在[CLS]位置的输出C,类别概率(softmax)如下,目标函数:Maximize the log probability of the correct label
![]()
非分类任务:利用Transformer的输出向量,设定特定任务的网络结构
3.小见解
1.双向?通过self-attention实现的,利用Transformer中的encoder实现的,可以使用当前词前后的词,因此成为双向Transformer(Transformer中由于decoder限制了只能使用当前词之前词的信息,所以decoder是单向的;但是encoder在每一个词输入时,是可以利用前后所有词的信息,因此称为双向)
2.深层?因为Transformer只是用self-attention,没有使用RNN或者CNN,并且利用了残差网络,因此可以训练深层模型
3.利用非标注数据?BERT可以利用文档生成“预测是否为下一句”任务的 训练数据,从而不受标注数据量的影响
4.双向预测?由于BERT是双向的,利用词前后词的信息,所以多层之后就知道了该位置的词是什么,因此采用了mask的方式(个人觉得有点像降噪自编码器)
5.预训练过程主要解决“预测是否为下一句”的任务,因此目标函数是最小化(mask位置预测损失+是否为下一句分类任务损失)