开始入坑深度学习(DeepLearning)
现在游戏越来越难做,国家广电总局审核越来越变态,国家各种打压游戏,游戏产业也成为教育失败的背锅侠,所以本人现在开始做深度学习方向。
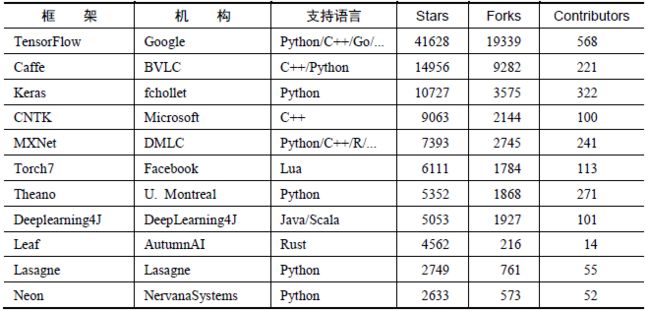
深度学习研究的热潮持续高涨,各种开源深度学习框架也层出不穷,其中包括TensorFlow、Caffe、Keras、CNTK、Torch7、MXNet、Leaf、Theano、DeepLearning4、Lasagne、Neon,等等。然而TensorFlow却杀出重围,在关注度和用户数上都占据绝对优势,大有一统江湖之势。表2-1所示为各个开源框架在GitHub上的数据统计(数据统计于2017年1月3日),可以看到TensorFlow在star数量、fork数量、contributor数量这三个数据上都完胜其他对手。
TensorFlow
TensorFlow是相对高阶的机器学习库,用户可以方便地用它设计神经网络结构,而不必为了追求高效率的实现亲自写C++或CUDA代码。它和Theano一样都支持自动求导,用户不需要再通过反向传播求解梯度。其核心代码和Caffe一样是用C++编写的,使用C++简化了线上部署的复杂度,并让手机这种内存和CPU资源都紧张的设备可以运行复杂模型(Python则会比较消耗资源,并且执行效率不高)。除了核心代码的C++接口,TensorFlow还有官方的Python、Go和Java接口,是通过SWIG(Simplified Wrapper and Interface Generator)实现的,这样用户就可以在一个硬件配置较好的机器中用Python进行实验,并在资源比较紧张的嵌入式环境或需要低延迟的环境中用C++部署模型。SWIG支持给C/C++代码提供各种语言的接口,因此其他脚本语言的接口未来也可以通过SWIG方便地添加。不过使用Python时有一个影响效率的问题是,每一个mini-batch要从Python中feed到网络中,这个过程在mini-batch的数据量很小或者运算时间很短时,可能会带来影响比较大的延迟。现在TensorFlow还有非官方的Julia、Node.js、R的接口支持,地址如下。
Julia: github.com/malmaud/TensorFlow.jl
Node.js: github.com/node-tensorflow/node-tensorflow
R: github.com/rstudio/tensorflow
在数据并行模式上,TensorFlow和Parameter Server很像,但TensorFlow有独立的Variable node,不像其他框架有一个全局统一的参数服务器,因此参数同步更自由。TensorFlow和Spark的核心都是一个数据计算的流式图,Spark面向的是大规模的数据,支持SQL等操作,而TensorFlow主要面向内存足以装载模型参数的环境,这样可以最大化计算效率。
TensorFlow的另外一个重要特点是它灵活的移植性,可以将同一份代码几乎不经过修改就轻松地部署到有任意数量CPU或GPU的PC、服务器或者移动设备上。相比于Theano,TensorFlow还有一个优势就是它极快的编译速度,在定义新网络结构时,Theano通常需要长时间的编译,因此尝试新模型需要比较大的代价,而TensorFlow完全没有这个问题。TensorFlow还有功能强大的可视化组件TensorBoard,能可视化网络结构和训练过程,对于观察复杂的网络结构和监控长时间、大规模的训练很有帮助。TensorFlow针对生产环境高度优化,它产品级的高质量代码和设计都可以保证在生产环境中稳定运行,同时一旦TensorFlow广泛地被工业界使用,将产生良性循环,成为深度学习领域的事实标准。
除了支持常见的网络结构[卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurent Neural Network,RNN)]外,TensorFlow还支持深度强化学习乃至其他计算密集的科学计算(如偏微分方程求解等)。TensorFlow此前不支持symbolic loop,需要使用Python循环而无法进行图编译优化,但最近新加入的XLA已经开始支持JIT和AOT,另外它使用bucketing trick也可以比较高效地实现循环神经网络。TensorFlow的一个薄弱地方可能在于计算图必须构建为静态图,这让很多计算变得难以实现,尤其是序列预测中经常使用的beam search。
TensorFlow的用户能够将训练好的模型方便地部署到多种硬件、操作系统平台上,支持Intel和AMD的CPU,通过CUDA支持NVIDIA的GPU(最近也开始通过OpenCL支持AMD的GPU,但没有CUDA成熟),支持Linux和Mac,最近在0.12版本中也开始尝试支持Windows。在工业生产环境中,硬件设备有些是最新款的,有些是用了几年的老机型,来源可能比较复杂,TensorFlow的异构性让它能够全面地支持各种硬件和操作系统。同时,其在CPU上的矩阵运算库使用了Eigen而不是BLAS库,能够基于ARM架构编译和优化,因此在移动设备(Android和iOS)上表现得很好。
TensorFlow在最开始发布时只支持单机,而且只支持CUDA 6.5和cuDNN v2,并且没有官方和其他深度学习框架的对比结果。在2015年年底,许多其他框架做了各种性能对比评测,每次TensorFlow都会作为较差的对照组出现。那个时期的TensorFlow真的不快,性能上仅和普遍认为很慢的Theano比肩,在各个框架中可以算是垫底。但是凭借Google强大的开发实力,很快支持了新版的cuDNN(目前支持cuDNN v5.1),在单GPU上的性能追上了其他框架。表2-3所示为https://github.com/soumith/convnet-benchmarks给出的各个框架在AlexNet上单GPU的性能评测
Caffe
官方网址:caffe.berkeleyvision.org/
GitHub:github.com/BVLC/caffe
Caffe全称为Convolutional Architecture for Fast Feature Embedding,是一个被广泛使用的开源深度学习框架(在TensorFlow出现之前一直是深度学习领域GitHub star最多的项目),目前由伯克利视觉学中心(Berkeley Vision and Learning Center,BVLC)进行维护。Caffe的创始人是加州大学伯克利的Ph.D.贾扬清,他同时也是TensorFlow的作者之一,曾工作于MSRA、NEC和Google Brain,目前就职于Facebook FAIR实验室。Caffe的主要优势包括如下几点。
- 容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络。
- 训练速度快,能够训练state-of-the-art的模型与大规模的数据。
- 组件模块化,可以方便地拓展到新的模型和学习任务上。
Caffe的核心概念是Layer,每一个神经网络的模块都是一个Layer。Layer接收输入数据,同时经过内部计算产生输出数据。设计网络结构时,只需要把各个Layer拼接在一起构成完整的网络(通过写protobuf配置文件定义)。比如卷积的Layer,它的输入就是图片的全部像素点,内部进行的操作是各种像素值与Layer参数的convolution操作,最后输出的是所有卷积核filter的结果。每一个Layer需要定义两种运算,一种是正向(forward)的运算,即从输入数据计算输出结果,也就是模型的预测过程;另一种是反向(backward)的运算,从输出端的gradient求解相对于输入的gradient,即反向传播算法,这部分也就是模型的训练过程。实现新Layer时,需要将正向和反向两种计算过程的函数都实现,这部分计算需要用户自己写C++或者CUDA(当需要运行在GPU时)代码,对普通用户来说还是非常难上手的。正如它的名字Convolutional Architecture for Fast Feature Embedding所描述的,Caffe最开始设计时的目标只针对于图像,没有考虑文本、语音或者时间序列的数据,因此Caffe对卷积神经网络的支持非常好,但对时间序列RNN、LSTM等支持得不是特别充分。同时,基于Layer的模式也对RNN不是非常友好,定义RNN结构时比较麻烦。在模型结构非常复杂时,可能需要写非常冗长的配置文件才能设计好网络,而且阅读时也比较费力。
Caffe的一大优势是拥有大量的训练好的经典模型(AlexNet、VGG、Inception)乃至其他state-of-the-art(ResNet等)的模型,收藏在它的Model Zoo(github.com/BVLC/ caffe/wiki/Model-Zoo)。因为知名度较高,Caffe被广泛地应用于前沿的工业界和学术界,许多提供源码的深度学习的论文都是使用Caffe来实现其模型的。在计算机视觉领域Caffe应用尤其多,可以用来做人脸识别、图片分类、位置检测、目标追踪等。虽然Caffe主要是面向学术圈和研究者的,但它的程序运行非常稳定,代码质量比较高,所以也很适合对稳定性要求严格的生产环境,可以算是第一个主流的工业级深度学习框架。因为Caffe的底层是基于C++的,因此可以在各种硬件环境编译并具有良好的移植性,支持Linux、Mac和Windows系统,也可以编译部署到移动设备系统如Android和iOS上。和其他主流深度学习库类似,Caffe也提供了Python语言接口pycaffe,在接触新任务,设计新网络时可以使用其Python接口简化操作。不过,通常用户还是使用Protobuf配置文件定义神经网络结构,再使用command line进行训练或者预测。Caffe的配置文件是一个JSON类型的.prototxt文件,其中使用许多顺序连接的Layer来描述神经网络结构。Caffe的二进制可执行程序会提取这些.prototxt文件并按其定义来训练神经网络。理论上,Caffe的用户可以完全不写代码,只是定义网络结构就可以完成模型训练了。Caffe完成训练之后,用户可以把模型文件打包制作成简单易用的接口,比如可以封装成Python或MATLAB的API。不过在.prototxt文件内部设计网络节构可能会比较受限,没有像TensorFlow或者Keras那样在Python中设计网络结构方便、自由。更重要的是,Caffe的配置文件不能用编程的方式调整超参数,也没有提供像Scikit-learn那样好用的estimator可以方便地进行交叉验证、超参数的Grid Search等操作。Caffe在GPU上训练的性能很好(使用单块GTX 1080训练AlexNet时一天可以训练上百万张图片),但是目前仅支持单机多GPU的训练,没有原生支持分布式的训练。庆幸的是,现在有很多第三方的支持,比如雅虎开源的CaffeOnSpark,可以借助Spark的分布式框架实现Caffe的大规模分布式训练。