HEVC的帧间预测
1.MV搜索
MV搜索的目的是要在参考帧中找到最佳匹配块,即Cost最小。其中Cost与图像失真和码率有关,例如,图像失真越小,码流也越小(即编码的比特大小),Cost就最小。然而这是不可能的。可以理解为,图像越逼真,需要编码的量就越大,我们只能在图像质量和编码大小二者中做一个trade off。Cost的定义可以如下所示:
其中 ΔD Δ D 的D是Difference,是图像的失真的衡量,可以是SAD,SSE等等, λ λ 是拉格朗日乘数,就是一个实数系数而已, R R 是码流的大小。
具体的搜索方法是:
1.确定起始搜索点,(可以)利用Cost最小的AMVP(Advanced Motion Vector Prediction)作为起始搜索点(非强制)。
AMVP是一种运动向量预测,利用空域和时域上的运动向量的相关性,为当前PU建立候选预测MV(MVP)列表,如下图1所示。
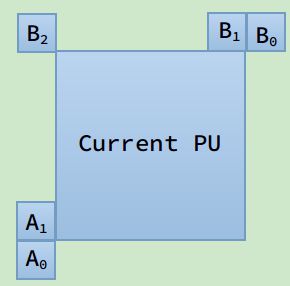
图1 当前PU候选MV列表
2.在参考帧中按照一定规则搜索其它块(具体方法标准没有强制要求,此处省略)
3.计算每个块的cost,取最小的cost的块作为最佳匹配块
整个过程是,我们在一个当前帧(非参考帧)里有一个块,我们想要找这个块在参考帧中的最佳匹配块(另一个块),计算两个块之间位置的位移,这样,通过参考帧加上这个位移就得到了我们的当前帧,这种编码方式可以获得更小的码率。
2.MV预测
所谓预测,是利用空域上或时域上相邻块的MV拿来给自己使用,或者说预先人为这些块可以给自己使用。其中的原理是利用了空间邻域的局部性和时间邻域的局部性,即空间上相邻块的MV很有可能比自己搜索出来的MV更好,时域同理。
2.1.Merge模式
Merge模式的第一步是构建一个空域或时域的MV候选列表,所谓候选列表是说选择的一些相邻的块,到时将会用到这些候选列表中的块的MV和搜索出来的MV做对比,看看它们谁的率失真Cost比较小,就选择那个作为最佳的MV。这里有两个问题,第一是,搜索加上和候选列表比较,不是会增加算法的复杂度吗?答案是,是的,确实是会增加算法的复杂度,但也是为了更好的效果;第二个问题是,既然已经搜索出来了最佳MV为什么还要再用候选列表再比较一次?这个问题和第一个问题也是相关的,首先是为了更好的效果,其次是merge模式下,候选列表是有限的,标准规定最多就5个,因此,编码这些列表内块的index需要的比特位是很少的,这样,如果可以用候选列表内的块代替最佳MV,那么只需要编码这些index,可以节省比特。总的来说就是,用算法的复杂度换取更高的PSNR(即更低的图像失真和更低的码率)。
那我们如何构建候选列表呢?
2.1.1.空域候选列表的构建
在空间上,我们如图1所示,选取5个可选的候选块,根据 A1→B1→B0→A1→(B2) A 1 → B 1 → B 0 → A 1 → ( B 2 ) 的顺序构建,其中,只有前面四个出现缺失时才会取B2。取这样的顺序的原因是,编码是按之字形扫描的,因此A1是最有可能已经编好的,虽然B1也很可能是编号的,但是如果在第一行的话,整个第一行都是没有B1的,当然如果在第一列的话A1也是没有的,若出现某个没有的情况,才会取B2。这也同时解释了候选列表为什么不用右下角的块加入候选列表,也是因为编码顺序的问题。
2.1.2.时域候选列表的构建
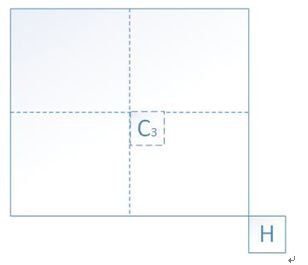
图2 时域候选列表
在参考帧中,候选的块有H和C两个,这里C的左上角是PU的中心,H的左上角是PU的右下角,我们首先找H位置的块,如果H不存在或者H在下一行的CTU中,就找C。至于为什么H在下一行的CTU就不找,我也不知道,可能是出于硬件实现的角度,因为参考帧的信息都是要存储的,在预取的时候,可能是先考虑取相邻的一些CTU。
确定了同位PU后,不能直接使用,还需要进行比例伸缩,原因是同位PU和当前PU的参考帧可能不一样。具体的公式是:
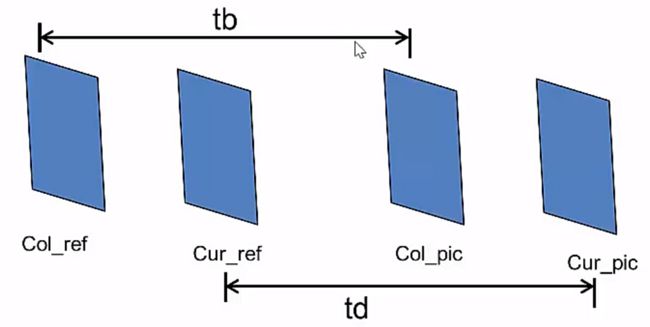
图3 比例伸缩
其中td和tb是帧之间的时间差。如图3,col代表collocated,意思是对应,即时域上同位块对应的帧;cur意思是current帧。这里还分成了当前帧和参考帧,对应帧和对应帧的参考帧,以说明,“同位块对应的帧可能与当前帧的参考帧不相同”。既然不相同,就有可能出现从对应帧相对于它自己的参考帧求得的MV与当前帧与当前帧的参考帧的MV不同的情况。为了解决这种情况,我们就用了上述公式所示的比例伸缩方法。原理大致可以想象成,有一个物体正在进行匀速运动,从Col_ref到Col_pic间的运动的尺度/规模/距离/大小和Cur_ref到Cur_pic之间尺度/规模/距离/大小的比例就是 tdtb t d t b 。如图4所示,小球从A点运动到D点,已知距离AC和BD,求A到C的运动矢量(距离加方向)和B到D的运动距离之比。乍一看好像是废话,可是这里的前提是A到D做的是匀速直线运动。当然,实际上视频里的运动是不可能那么理想的,所以这里就存在精度的问题–这种粗暴的方法在应用上精度会不高。HEVC中有精度更高的算法,但总的原理是比较相似的。
2.2.AMVP模式
在之前说的Merge模式下建立了一个候选列表,我们希望的是在候选列表中的块的MV可以直接代替当前块的MV,这样我们只需要编码这些候选列表块的编号(一般很小)就可以,也就是这样可以节省码率。但是万一要是候选列表里的块的MV经过比较以后发现不是最好的怎么办?这时我们就需要进入AMVP模式。
AMVP模式下也需要候选列表,只不过它的候选列表的长度是2,也包括时域和空域,而且它也不编码这个列表的索引,而是编码MVD(Motion Vector Difference),MVD指的是当前搜索到的最佳MV和AMVP候选列表中MV的差值。在AMVP模式下,候选块的位置其实是和Merge模式一样的,只不过只在图1中的A0和A1中选择一个B0和B1中选择一个MV,如果这两个MV的大小相同,则合并为一个MV。但是这里还有一个问题,就是即使这些块都在同一个帧内,它们的参考帧也有可能不同,当它们参考的帧不同的时候,就要像之前说的时域的情况一样,参考使用比例伸缩的方法。AMVP模式下的时域候选列表的选取和Merge模式下一样。如果在选取了空域和时域的候选列表之后,所得到的候选列表不足2个(即候选列表里的块为未编码块或不存在)则用(0,0)作为MV补充。
2.3.Skip 模式
Skip模式只存在于帧间预测时,即P帧或B帧,Skip模式下,一个CU的大部分语法元素都不需要编,一个CU是否为Skip模式,取决于三点,一是该CU的划分方式为 2N×2N 2 N × 2 N ,二是该CU下PU的预测方式时Merge模式,第三是该CU的残差变换系数全为0。这个意义上可以将Skip视为Merge模式的一种特殊情况。
2.4.PCM模式
PCM下不经过预测变换,就是上面的过程都不需要了,搜索预测等等都不需要了,取而代之的是直接对像素值进行编码,代码如如图4:

上述代码循环中cbSize只的是8*8或4*4,例如8*8的CB,log2CbSize就等于3,那么括号里它左移一位就为6,1左移六位就为64了,也就是8*8。至于为什么不直接用 22∗log2CbSize 2 2 ∗ l o g 2 C b S i z e ,可能是因为位运算速度更快,处于优化考虑吧。
2.5.加权预测
MV的作用是去模拟一个块的运动的方向,但就我们的观影体验来说,有时候物体的变化并不带表它移动了,也有可能仅仅是颜色变化了。当所有像素做了一个整体变化的时候,可以用加权预测来带来更好的效果。加权预测是以slice为基本单位的。加权预测的值时被定义在在 slicesegmentheader() s l i c e s e g m e n t h e a d e r ( ) 里的,也就是说一个slice存储的是一样的。同样,加权预测旨在P_Slice和B_Slice中有。
加权预测有两种,一种是默认的加权预测,一种是