CompressAI:深度学习与传统图像压缩
1、图像压缩算法原理
传统的有损图像压缩方法,如JPEG , JPEG2000 , HEVC或AV1或VVC,在类似的编码方案上进行了迭代改进:将图像划分为像素块,使用变换域通过线性变换(例如:DCT或DWT)去相关空间频率,基于相邻值执行一些预测,量化转换系数,最后使用有效的熵编码器(例如:CABAC[11])将量化值和预测侧信息编码成比特流。
另一方面,基于人工神经网络的编解码器主要依赖于学习分析和综合非线性变换。像素值通过分析变换映射到潜在表示,然后对潜在进行量化和(无损)熵编码。类似地,解码器由近似逆变换或合成变换组成,然后将潜在表示转换回像素域。
CompressAI最重要的特性之一是能够轻松实现端到端的图像压缩深度神经网络。一些领域特定的层、操作和模块已经在PyTorch上实现,比如熵模型、量化操作、颜色变换。

从最先进的学习图像压缩中重新实现的模型目前在CompressAI中可用。完全支持本表中列出的模型的训练、微调、推理和评估。
由于参考模型的设计,需要遵守一些约束:H和W预计至少为64像素长。基于特定模型的跨行卷积和反卷积的数量,用户可能必须将输入张量的H和W填充到适当的维度。
大多数模型的训练或评估模式都有不同的表现。例如,量化操作可以以不同的方式进行:通常在训练期间向潜在张量添加均匀噪声,而在推理阶段使用舍入。用户可以通过model.train()或model.eval()在模式之间切换

finding the right quality parameter to reach a given PSNR or bit-rate on a target image (see example in listing
找到正确的质量参数以达到目标图像的给定PSNR或比特率(参见清单中的示例)
2、Traditional codecs传统的编解码器
为了便于与传统编解码器进行比较,CompressAI包含了一个简单的python API和命令行接口。支持最常见的图像和视频编解码器,支持的编解码器的完整列表及其各自的实现可在表4中找到

此时,传统方法和基于人工神经网络的方法之间的运行时效性比较无法准确和公平地报告。测量基于人工神经网络的编解码器的推理效率是一个活跃的研究课题。神经网络被有效地设计为在大规模并行架构上运行,而传统的编解码器通常被设计为在单个CPU核心上运行。
注意:CompressAI不附带上述传统编解码器的二进制文件,而是在可执行文件上提供一个通用的Python接口,JPEG和WebP例外,它们默认使用Python Pillow Image库链接
3、CompressAI介绍
CompressAI 构建在 PyTorch 之上,并提供:
(1)基于深度学习的数据压缩的自定义操作、层和模型
(2)官方TensorFlow 压缩库的部分移植
(3)用于学习图像压缩的预训练端到端压缩模型
(4)用于将学习模型与经典图像/视频压缩编解码器进行比较的评估脚本
CompressAI 旨在通过提供资源来研究、实施和评估基于机器学习的压缩编解码器,让更多的研究人员为学习的图像和视频压缩领域做出贡献。


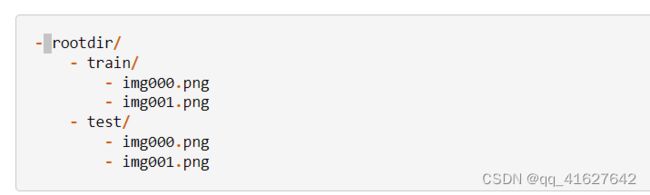
构造训练数据集(compressai.datasets)

ImageFolder
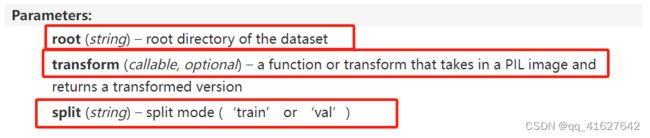
class compressai.datasets.ImageFolder(root, transform=None, split='train')
加载图像文件夹数据库。训练和测试图像样本分别存储在不同的目录中:
VideoFolder
class compressai.datasets.VideoFolder(root, rnd_interval=False, rnd_temp_order=False, transform=None, split='train')[source]
加载视频文件夹数据库。训练和测试视频剪辑存储在包含多个子目录的目录中,例如 Vimeo90K 数据集:

训练和测试(有效)剪辑将从列出相关文件夹的相应输入文件导航的子目录中撤回。
此类返回元组中的一组三个视频帧。如果子文件夹包含超过 6 帧,则可以应用随机间隔。

Models 模型


bmshj2018_factorized
compressai.zoo.bmshj2018_factorized(quality, metric='mse', pretrained=False, progress=True, **kwargs)

bmshj2018_hyperprior
compressai.zoo.bmshj2018_hyperprior(quality, metric='mse', pretrained=False, progress=True, **kwargs)[source]
mbt2018_mean
compressai.zoo.mbt2018_mean(quality, metric='mse', pretrained=False, progress=True, **kwargs)[source]
mbt2018
compressai.zoo.mbt2018_mean(quality, metric='mse', pretrained=False, progress=True, **kwargs)[source]
cheng2020_anchor
compressai.zoo.cheng2020_anchor(quality, metric='mse', pretrained=False, progress=True, **kwargs)[source]

cheng2020_attn
compressai.zoo.cheng2020_attn(quality, metric='mse', pretrained=False, progress=True, **kwargs)[source]


模型训练
An example training script train.py is provided script in the examples/ folder of the CompressAI source tree.
python3 examples/train.py -m mbt2018-mean -d /path/to/image/dataset \
--batch-size 16 -lr 1e-4 --save --cuda
运行train.py-help来列出可用的选项。请参见模型动物园训练部分,以重现预训练模型的性能。

python examples/train.py -m bmshj2018-factorized -d dataset/htht1024 --save --cuda --seed 4
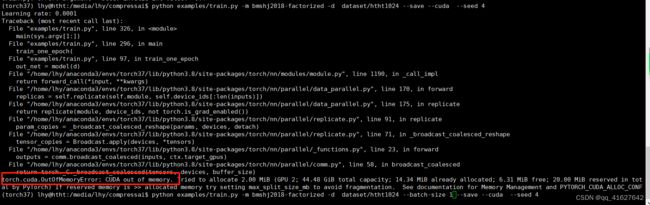
python examples/train.py -m bmshj2018-factorized -d dataset/htht1024 --batch-size 1 --save --cuda --seed 4

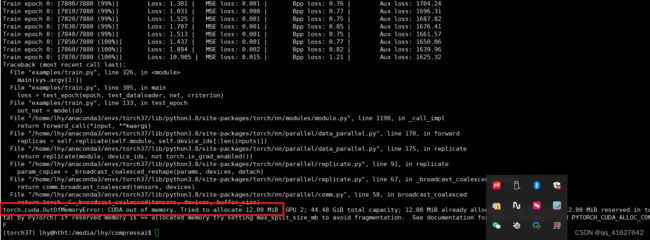
python examples/train.py -m bmshj2018-factorized -d dataset/htht512 --batch-size 4 --save --cuda --seed 4
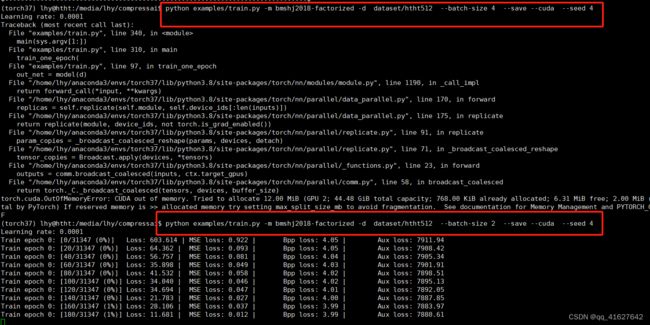
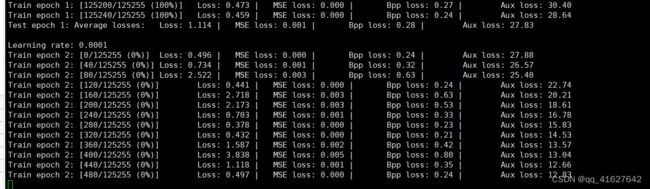
模型更新Model update
一旦一个模型被训练,你需要运行update_model脚本来更新 entropy bottlenecks的内部参数:
python -m compressai.utils.update_model --architecture ARCH checkpoint_best_loss.pth.tar
这将修改与学习到的执行实际熵编码所需的累积分布函数(CDFs)相关的缓冲区。
您可以运行python -m compressai.utils.update_model --help以获取完整的选项列表。
或者,您可以在保存模型检查点之前在训练脚本末尾调用update() a CompressionModel或EntropyBottleneck 实例的方法。
模型评估Model evaluation
更新模型检查点后,您可以使用eval_model来获取其在图像数据集上的性能
python -m compressai.utils.eval_model checkpoint /path/to/image/dataset \
-a ARCH -p path/to/checkpoint-xxxxxxxx.pth.tar
您可以运行python -m compressai.utils.eval_model --help以获取完整的选项列表。
熵编码
默认情况下,CompressAI 使用一系列非对称数字系统 (ANS) 熵编码器。您可以使用compressai.available_entropy_coders()获取已实现的熵编码器的列表,并通过 compressai.set_entropy_coder() 更改默认的熵编码器。
将图像张量压缩为比特流
x = torch.rand(1, 3, 64, 64)
y = net.encode(x)
strings = net.entropy_bottleneck.compress(y)
将比特流解压缩为图像张量
shape = y.size()[2:]
y_hat = net.entropy_bottleneck.decompress(strings, shape)
x_hat = net.decode(y_hat)
训练你自己的模型
在本教程中,我们将使用 CompressAI 中预定义的一些模块和层来实现自定义自动编码器架构。
定义自定义模型
让我们构建一个简单的自动编码器,其中包含一个 EntropyBottleneck模块、编码器的 3 个卷积、解码器的 3 个转置反卷积和 GDN激活函数:
import torch.nn as nn
from compressai.entropy_models import EntropyBottleneck
from compressai.layers import GDN
class Network(nn.Module):
def __init__(self, N=128):
super().__init__()
self.entropy_bottleneck = EntropyBottleneck(N)
self.encode = nn.Sequential(
nn.Conv2d(3, N, stride=2, kernel_size=5, padding=2),
GDN(N)
nn.Conv2d(N, N, stride=2, kernel_size=5, padding=2),
GDN(N)
nn.Conv2d(N, N, stride=2, kernel_size=5, padding=2),
)
self.decode = nn.Sequential(
nn.ConvTranspose2d(N, N, kernel_size=5, padding=2, output_padding=1, stride=2)
GDN(N, inverse=True),
nn.ConvTranspose2d(N, N, kernel_size=5, padding=2, output_padding=1, stride=2)
GDN(N, inverse=True),
nn.ConvTranspose2d(N, 3, kernel_size=5, padding=2, output_padding=1, stride=2)
)
def forward(self, x):
y = self.encode(x)
y_hat, y_likelihoods = self.entropy_bottleneck(y)
x_hat = self.decode(y_hat)
return x_hat, y_likelihoods
卷积的跨步减少了张量的空间维度,同时增加了通道数量(这有助于学习更好的潜在表示)。瓶颈模块用于在训练时获得潜在张量的可微熵估计。
损失函数
(1)Rate distortion loss
我们将定义一个简单的率失真损失,它最大化 PSNR 重建 (RGB) 并最小化量化潜在张量 ( ) 的长度(以位为单位)y_hat。
标量用于平衡重建质量和比特率(如 JPEG 质量参数或 HEVC 的 QP)

import math
import torch.nn as nn
import torch.nn.functional as F
x = torch.rand(1, 3, 64, 64)
net = Network()
x_hat, y_likelihoods = net(x)
# bitrate of the quantized latent
N, _, H, W = x.size()
num_pixels = N * H * W
bpp_loss = torch.log(y_likelihoods).sum() / (-math.log(2) * num_pixels)
# mean square error
mse_loss = F.mse_loss(x, x_hat)
# final loss term
loss = mse_loss + lmbda * bpp_loss
(2)Auxiliary loss