windows本地Eclipse开发spark程序打包到集群运行
windows环境下基于Eclipse开发spark的配置可以看上一篇博文:https://blog.csdn.net/ASN_forever/article/details/84747317
本篇主要记录如何在windows本地用Eclipse开发spark程序以及如何打包到Linux集群去运行。
首先在Eclipse中创建一个maven项目,并配置好pom(具体细节看上一篇配置博文)。
编写Wordcount程序
然后就是新建class了,我的类名是WordCount.java,这段代码不仅实现单词统计,还实现了排序的功能,具体代码如下:
package FirstSpark;
import java.util.Arrays;
import java.util.Iterator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class WordCount {
public static void main(String[] args) {
//创建一个java版本的spark context
SparkConf conf = new SparkConf().setMaster("local").setAppName("wc");//setMaster("local")表示在本机运行,如果要在集群运行,直接去掉这个方法即可
JavaSparkContext sc = new JavaSparkContext(conf);
//获取hdfs上的文件创建rdd
JavaRDD text = sc.textFile("hdfs://master:9000/word.txt");
JavaRDD words = text.flatMap(new FlatMapFunction() {
private static final long serialVersionUID = 1L;
@Override
public Iterator call(String line) throws Exception {
return Arrays.asList(line.split(" ")).iterator();
}
});
JavaPairRDD pairs = words.mapToPair(new PairFunction() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(String word) throws Exception {
// TODO Auto-generated method stub
return new Tuple2(word, 1);
}
});
JavaPairRDD results = pairs.reduceByKey(new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer value1, Integer value2) throws Exception {
// TODO Auto-generated method stub
return value1 + value2;
}
});
JavaPairRDD temp = results.mapToPair(new PairFunction, Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(Tuple2 tuple)
throws Exception {
return new Tuple2(tuple._2, tuple._1);
}
});
JavaPairRDD sorted = temp.sortByKey(false).mapToPair(new PairFunction, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2 call(Tuple2 tuple)
throws Exception {
// TODO Auto-generated method stub
return new Tuple2(tuple._2,tuple._1);
}
});
sorted.foreach(new VoidFunction>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2 tuple) throws Exception {
System.out.println("word:" + tuple._1 + " count:" + tuple._2);
}
});
sc.close();
}
}
需要注意的是,网上很多资料包括《spark快速大数据分析》这本书上,在使用flatMap处理文件的时候都是返回的iterable对象,如下所示:
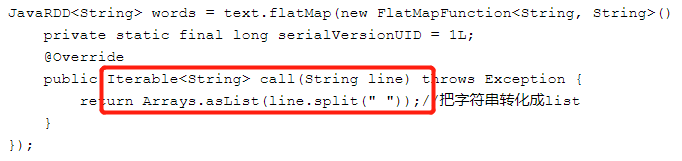
但我这样使用的时候会报编译时错误,如下:
The return type is incompatible with FlatMapFunction.call(String)
为此我把返回类型改成iterator类型,结果顺利通过。

打包本地运行
接下来打包,右键类名WordCount.java,点击Export,选择JAR file后一路点击next最终finish即可。
然后将jar包通过Xftp之类的工具上传到Linux集群的spark主节点上,然后需要保证hdfs上有要统计的word.txt文件,如果没有的话就要先创建。
打包完之后,可以先在windows本地的cmd中通过命令运行(因为设置了setMaster("local")就表示在本机运行),查看是否符合预期。在本地运行的时候,前提是要保证Linux集群的hdfs是打开的(也就是hadoop集群start-all.sh),这样它会自动找到集群上的文件进行处理,不然会报错。


虽然是运行成功了,但是发现有个错误报告,说没能删除掉临时文件。。。还不知道什么情况。。。先不管了,反正能运行就行。

打包集群运行
要在集群运行的话,需要去掉setMaster(“local”)这一项设置,即默认采用集群方式运行。
去掉后重新打包,发送到集群的所有节点的相同目录下(如果只放在了master中,虽然也能得到结果,但会报一些RPC错误,但是如果使用的是yarn管理器时,好像就可以只放在某一个节点上),然后在某一台机器上去运行。
输入如下命令即可完成统计:
spark-submit --class FirstSpark.WordCount --master spark://master:7077 --executor-memory 500m --total-executor-cores 2 /opt/hadoop/FirstSpark.jar
名词解释
spark-submit:spark为各种集群管理器提供的统一的提交作业的工具
class FirstSpark.WordCount:指明运行的类,FirstSpark是类所在的包名,WordCount是类名
master spark://master:7077:指明连接到7077端口的spark独立集群上(还有其他方式,如local、yarn等)
executor-memory 500m:指定执行器进程使用的内存为500m
total-executor-cores 2:指定为此程序分配2个核
/opt/hadoop/FirstSpark.jar:指明此jar包在主节点上的位置
运行结果

