Hbase 详解(上)
HBase是什么?
Apache HBase™ is theHadoop database, a distributed, scalable, big data store.
Apache Hbase 是hadoop数据库,一个分布式的,可扩展的大数据存储。
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
当你需要对你的大量数据进行随机近实时读写时使用Hbase。HBase的目标是在商用硬件集群上管理非常大的表,数十亿行X数百亿列。HBase是一个模仿Gootable’s Bigtable的,开源的、分布式的、版本化的非关系型数据库。Google’s Bigtable是一个由Chang等人创建的一个结构化的分布式存储系统。正如Bigtable利用谷歌的分布式文件存储系统,Apache HBase 在Hadoop和HDFS上提供类似Bigtable的功能。
注:Hbase也是常见的Nosql之一。
RDBMS:关系型数据库的特点:存储结构化数据、文本存储、单机、存储小1G以下或左右
什么是nosql?
Nosql的定义
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,具体来说就是跟关系型数据库有些类似(查询低延迟),但同时能够存储的数据类型却更加灵活,常见的有列式存储和文档存储等,为了跟关系型数据库加以区分,称之为非关系型的数据库。Hbase是Nosql的一个种类,其特点是列式存储。
出现的原因
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
互联网+
普通+物联网
--数据量产生巨大
Nosql的作用
NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
常见的nosql数据库类型及其代表
非关系型数据库——列存储(HBase)
非关系型数据库——文档型存储(MongoDb)
非关系型数据库——内存式存储(redis) KV
非关系型数据库——图形模型(Graph)
HBase能用来干什么?
存储大量结果集数据,并提供低延迟的随机查询。说的通俗一些,就是一个超级版的数据库,相比较与mysql、postgresql和oracle、sqlserver等关系型数据库而言,能够存储的数据量更大(比关系型数据库大很多很多),同时查询延迟相比较与其他hadoop产品(pig、hive)要低。
HBase跟hive有什么区别?
Hive的定位是数据仓库,虽然也有增删改查,但其删改查对应的是整张表而不是单行数据,查询的延迟较高。其本质是更加方便的使用mr的威力来进行离线分析的一个数据分析工具。
HBase的定位是hadoop的数据库,是一个典型的Nosql,所以HBase是用来在大量数据中进行低延迟的随机查询的。
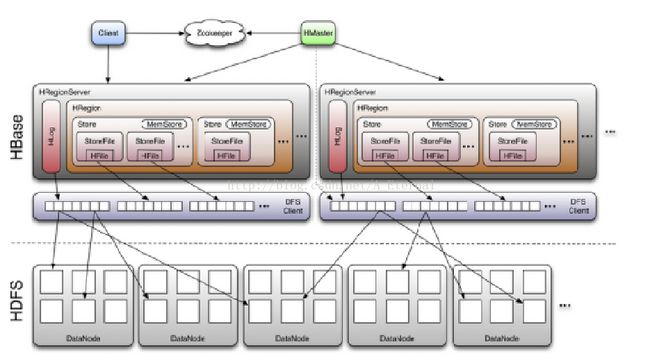
Hbase结构
HBase下载
HBase官网
http://hbase.apache.org/
HBase下载页面
http://mirror.bit.edu.cn/apache/hbase/stable/
我们的课程中使用Hbase的最新稳定(stable)版,即hbase-1.1.2-bin.tar.gz。
HBase安装和基本使用
安装前的规划
集群中机器名:master、slave1、slave2
单机方式安装
注意:单机方式安装时若安装所在的机器上有已经启动的zookeeper,要将其关闭,因为HBase内部会启动一个单机版的zookeeper,一般两者都使用2181端口,可能会造成端口冲突。
Ø 配置JAVA_HOME
进入到Hbase的安装路径下的conf目录,在hbase-env.sh文件中配置JAVA_HOME信息(即打开JAVA_HOME那一行的注释,并且根据本机真实的JAVA_HOME来进行配置,可使用which java命令快速查询java所安装的位置)
export JAVA_HOME=/opt/jdk/
Ø 配置被hbase-site.xml文件
进入到Hbase的安装路径下的conf目录,在hbase-site.xml文件中配置相关信息
添加如下配置项:
上述两个配置项中,hbase.rootdir指的是HBase用来存放数据的目录,这个目录不需要自己创建,HBase会帮助我们进行配置。如果你自己创建了这个目录,HBase会尝试将其做一个迁移,这可能不是你想要的结果。hbase.zookeeper.property.dataDir是用来存放HBase自己管理的zookeeper的属性数据信息的目录
至此,Hbase的单机安装配置就完毕了。
Hbase shell基本使用
启动HBase
(单机方式为了演示方便,我们就不在/etc/profile中配置HBase的Home了)
单机模式无需启动即可直接进入到HBase的shell,方式为:进入到Hbase的安装目录,执行如下命令:
# ./bin/start-hbase.sh
启动后可通过jps查看其进程,如下图所示,单机版启动后只有一个HMaster进程。

连接HBase
(单机方式为了演示方便,我们就不在/etc/profile中配置HBase的Home了)
进入到HBase的shell,方式为:进入到Hbase的安装目录,执行如下命令:
# ./bin/hbase shell
查看帮助信息
在HBase shell中使用help命令
hbase(main):001:0>help
执行一些命令
Ø 创建表(需要创建表名和列族)
hbase(main):001:0> create 'test', 'cf'
Ø 列出表信息
hbase(main):001:0>list 'test'
Ø 往表中添加数据
hbase(main):001:0>put 'test', 'row1', 'cf:a', 'value1'
hbase(main):002:0>put 'test', 'row2', 'cf:b', 'value2'
hbase(main):003:0>put 'test', 'row3', 'cf:c', 'value3'
Ø 扫描全表数据
hbase(main):001:0> scan 'test'
Ø 获取某行数据
hbase(main):003:0>get 'test', 'row1'
Ø 禁用表(在删除表之前要现将其禁用)
hbase(main):001:0>disable 'test'
Ø 启用表
hbase(main):001:0>enable 'test'
Ø 删除表
hbase(main):001:0>drop 'test'
退出HBase
在HBase shell中使用quit命令
hbase(main):001:0>quit
伪分布方式安装
伪分布式方式安装时,HBase的每个守护程序(HMaster,HRegionServer,和Zookeeper)都将作为一个单独的进程运行在同一台机器上,并且会将数据的存储方式由Linux本地文件系统更换为HDFS分布式文件系统,这意味着需要有一个可用的hadoop集群。
如果刚进行单机方式的安装,我们需要将HBase关闭,伪分布式安装会指定一个新的目录来存放HBase中的数据,所以刚才创建的表等数据将会丢失。
Ø 配置JAVA_HOME
进入到Hbase的安装路径下的conf目录,在hbase-env.sh文件中配置JAVA_HOME信息(即打开JAVA_HOME那一行的注释,并且根据本机真实的JAVA_HOME来进行配置,可使用which java命令快速查询java所安装的位置)
export JAVA_HOME=/opt/jdk
Ø 配置被hbase-site.xml文件
进入到Hbase的安装路径下的conf目录,在hbase-site.xml文件中配置相关信息
添加如下信息,以保证使用伪分布方式:
将单机模式中存储数据的地址由Linux本地文件系统地址改为HDFS地址
—
注意,这里添加的是HDFS的fs.defaultFS 配置项的值,这个值跟HDFS是否开启HA有关系
-->
这个目录不需要自己创建,HBase会帮助我们进行配置。如果你自己创建了这个目录,HBase会尝试将其做一个迁移,这可能不是你想要的结果。
保留存储zookeeper的配置
全分布式安装配置
Ø 首先保证已有一个独立的zookeeper集群,并设置hbase不自己管理zookeeper(我们现在使用的版本中默认就是如此,可以不进行配置)
Ø 在$HBASE_HOME/conf/hbase-env.sh中配置如下信息(若已有HBASE_MANAGES_ZK,将其改为false即可):
export HBASE_MANAGES_ZK=false
export JAVA_HOME=/usr/jdk1.8.0_60
Ø 在$HBASE_HOME/conf/regionservers中配置需要作为Hbase regin的机器名称,跟hadoop配置文件中的slaves文件类似,本例中配置信息如下
Hadoop01
Hadoop02
Hadoop03
Ø 在$HBASE_HOME/conf/hbase-site.xml文件中配置如下信息:
这个目录不需要自己创建,HBase会帮助我们进行配置。如果你自己创建了这个目录,HBase会尝试将其做一个迁移,这可能不是你想要的结果。
Ø 给hbase添加HADOOP_HOME信息
由于HDFS做了高可用,所以需要告知HBASE HADOOP_HOME
就算在/etc/profile中已经配置了HADOOP_HOME,也还需要必须在hbase-env.sh文件中添加HADOOP_HOME信息:
export HADOOP_HOME=/home/bigdata/hadoop
Ø 整体拷贝Hbase配置文件到regionservers中配置的其他机器上
做好上述配置后,跟hadoop类似,需要将其拷贝到在reginservers中配置的其他机器上。
完全分布方式的启动和关闭
全分布方式(集群方式)的HBase因为依赖hadoop和zookeeper,所以在启动HBase的时候,需要先保证这两者已经启动起来了再来启动HBase。
简便检测方法,使用jps命令检测各个组件的进程即可。
启动HBase服务
以下命令的执行前提是已经在系统中配置好了HBASE_HOME.
在master机器上执行如下命令(因为其上配置了从master到各个slave的ssh免密码登录):
# sh start-hbase.sh
启动后可通过jps命令查看HBase的进程信息:
Ø 普通的RegionServer
Ø Hbase的master
HquorumPeer进程证明Hbase内部的Zookeeper已启动
QuorumPeerMain进程证明外部的Zookeeper已启动
一般都启动外部的、独立的Zookeeper
进入HBase shell
# hbase shell
退出HBase shell
hbase(main):001:0> quit
关闭HBase服务
# sh stop-hbase.sh
Hbase webUI
默认地址为:http://master:16010/
注意:0.9x极以前的版本中,webUI地址的默认端口为60010。
建议使用Chrome浏览器观看,IE有兼容问题。


Hbase的经典使用场景

HBase基本概念
逻辑概念
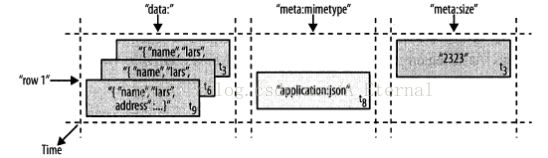
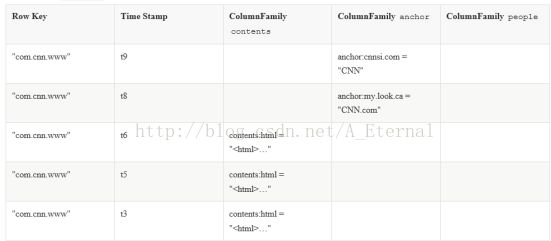
如下图所示,是一个HBase的典型表,HBase中通过多个条件(经常称之为坐标)来定位表中的数据:
表
HBase表由多行组成。

行
一行在HBase由行键和一个或多个列的值组成。如下图所示:
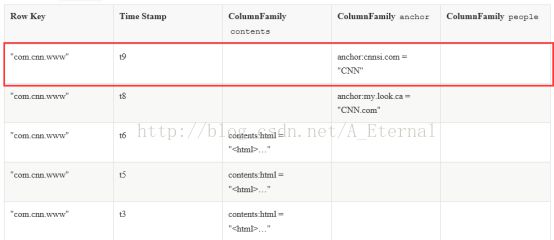
行按字母顺序排序的行键存储,行健类似关系型数据库中的ID列。如下图所示:

出于这个原因,行键的设计是非常重要的。目的是存储数据的方式接近彼此相关的行。常见的行键模式是一个网站域名。如果您的域名是行键,您应该将它们翻转后存储,(例如:org.apache.www, org.apache.mail, org.apache.jira)。这种方式,所有的Apache表中的域相互靠近,而不是基于子区域的第一个字母展开。
列

列是表中的最基本元素,HBase的列包含一个列族和一个列限定符,列属于一个列族,列族属于一个行。列中的内容不需要指定类型,这也是与关系型数据不同的地方,也是HBase被称之为无类型的数据库的原因。HBase的列与关系型数据库不同,在于其含有版本的概念,一个列的数据可以有多个历史版本,体现形式就是时间戳。