基于OpenCV的dnn模块使用YOLOv3进行目标检测
0、说明:
测试的opencv版本为opencv3.4.5
电脑cup:intel 4代i5(4200U)
1、YOLO介绍:
YOLO详解(知乎)
2、下载yolov3的配置文件:
wget https://github.com/pjreddie/darknet/blob/master/data/coco.names?raw=true -O ./coco.names
wget https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg?raw=true -O ./yolov3.cfg
wget https://pjreddie.com/media/files/yolov3.weights
3、C++代码:
#include
#include
#include
#include
#include
#include
#include
// Remove the bounding boxes with low confidence using non-maxima suppression
void postprocess(cv::Mat& frame, std::vector& outs);
// Get the names of the output layers
std::vector getOutputsNames(const cv::dnn::Net& net);
// Draw the predicted bounding box
void drawPred(int classId, float conf, int left, int top, int right, int bottom, cv::Mat& frame);
// Initialize the parameters
float confThreshold = 0.5; // Confidence threshold
float nmsThreshold = 0.4; // Non-maximum suppression threshold
int inpWidth = 416; // Width of network's input image
int inpHeight = 416; // Height of network's input image
std::vector classes;
int main(int argc, char** argv)
{
// Load names of classes
std::string classesFile = "/home/alan/Desktop/yolov3/coco.names";
std::ifstream classNamesFile(classesFile.c_str());
if (classNamesFile.is_open())
{
std::string className = "";
while (std::getline(classNamesFile, className))
classes.push_back(className);
}
else{
std::cout<<"can not open classNamesFile"<> frame;
//show frame
cv::imshow("frame",frame);
// Create a 4D blob from a frame.
cv::Mat blob;
cv::dnn::blobFromImage(frame, blob, 1/255.0, cv::Size(inpWidth, inpHeight), cv::Scalar(0,0,0), true, false);
//Sets the input to the network
net.setInput(blob);
// Runs the forward pass to get output of the output layers
std::vector outs;
net.forward(outs, getOutputsNames(net));
// Remove the bounding boxes with low confidence
postprocess(frame, outs);
// Put efficiency information. The function getPerfProfile returns the
// overall time for inference(t) and the timings for each of the layers(in layersTimes)
std::vector layersTimes;
double freq = cv::getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
std::string label = cv::format("Inference time for a frame : %.2f ms", t);
cv::putText(frame, label, cv::Point(0, 15), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 255));
// Write the frame with the detection boxes
cv::Mat detectedFrame;
frame.convertTo(detectedFrame, CV_8U);
//show detectedFrame
cv::imshow("detectedFrame",detectedFrame);
}
cap.release();
std::cout<<"Esc..."< getOutputsNames(const cv::dnn::Net& net)
{
static std::vector names;
if (names.empty())
{
//Get the indices of the output layers, i.e. the layers with unconnected outputs
std::vector outLayers = net.getUnconnectedOutLayers();
//get the names of all the layers in the network
std::vector layersNames = net.getLayerNames();
// Get the names of the output layers in names
names.resize(outLayers.size());
for (size_t i = 0; i < outLayers.size(); ++i)
names[i] = layersNames[outLayers[i] - 1];
}
return names;
}
// Remove the bounding boxes with low confidence using non-maxima suppression
void postprocess(cv::Mat& frame, std::vector& outs)
{
std::vector classIds;
std::vector confidences;
std::vector boxes;
for (size_t i = 0; i < outs.size(); ++i)
{
// Scan through all the bounding boxes output from the network and keep only the
// ones with high confidence scores. Assign the box's class label as the class
// with the highest score for the box.
float* data = (float*)outs[i].data;
for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols)
{
cv::Mat scores = outs[i].row(j).colRange(5, outs[i].cols);
cv::Point classIdPoint;
double confidence;
// Get the value and location of the maximum score
cv::minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
if (confidence > confThreshold)
{
int centerX = (int)(data[0] * frame.cols);
int centerY = (int)(data[1] * frame.rows);
int width = (int)(data[2] * frame.cols);
int height = (int)(data[3] * frame.rows);
int left = centerX - width / 2;
int top = centerY - height / 2;
classIds.push_back(classIdPoint.x);
confidences.push_back((float)confidence);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
}
// Perform non maximum suppression to eliminate redundant overlapping boxes with
// lower confidences
std::vector indices;
cv::dnn::NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
for (size_t i = 0; i < indices.size(); ++i)
{
int idx = indices[i];
cv::Rect box = boxes[idx];
drawPred(classIds[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame);
}
}
// Draw the predicted bounding box
void drawPred(int classId, float conf, int left, int top, int right, int bottom, cv::Mat& frame)
{
//Draw a rectangle displaying the bounding box
cv::rectangle(frame, cv::Point(left, top), cv::Point(right, bottom), cv::Scalar(0, 0, 255));
//Get the label for the class name and its confidence
std::string label = cv::format("%.2f", conf);
if (!classes.empty())
{
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ":" + label;
}
else
{
std::cout<<"classes is empty..."<
4、解析:
(1)cv::dnn::blobFromImage函数解析:
函数原型:
CV_EXPORTS_W Mat blobFromImage(InputArray image, double scalefactor=1.0, const Size& size = Size(),
const Scalar& mean = Scalar(), bool swapRB=true, bool crop=true);
参数解析:
第一个参数,image,表示输入的图像,可以是opencv的mat数据类型。
第二个参数,scalefactor,这个参数很重要的,如果训练时,是归一化到0-1之间,那么这个参数就应该为0.00390625f (1/256),否则为1.0
第三个参数,size,应该与训练时的输入图像尺寸保持一致。
第四个参数,mean,这个主要在caffe中用到,caffe中经常会用到训练数据的均值。tf中貌似没有用到均值文件。
第五个参数,swapRB,是否交换图像第1个通道和最后一个通道的顺序。
第六个参数,crop,输入图像大小与size不符的时候,如果为true,就是裁剪图像,如果为false,就是等比例放缩图像。
(2)cv::dnn::Net::forward函数解析:
forward的函数原型有4个,分别提供了不同的功能:
- 第一个
cv::dnn::Net::forward(const String & outputName = String())
这个函数只需要提供layer的name即可;函数返回一个Mat变量,返回值是指输入的layername首次出现的输出。
默认输出整个网络的运行结果。
- 第二个
void cv::dnn::Net::forward(OutputArrayOfArrays outputBlobs,
const String & outputName = String())
该函数的返回值是void,通过OutputArrayOfArrays类型提供计算结果,类型为blob。这个outputName依然是layer的name,outputBlobs不是首次layer的输出了,而是layername指定的layer的全部输出;多次出现,就提供多个输出。
- 第三个
void cv::dnn::Net::forward(OutputArrayOfArrays outputBlobs,
const std::vector & outBlobNames)
该函数返回值为void,outBlobNames是需要提供输出的layer的name,类型为vector,也就是说可以提供多个layer的那么;它会将每个layer的首次计算输出放入outputBlobs。
- 第四个
void cv::dnn::Net::forward(std::vector> & outputBlobs,
const std::vector & outBlobNames)
该函数的功能是最强大的,返回值为void;输入outBlobNames是vector类型,outputBlobs是vector
(3)网络前向传播后的输出格式解析:
Mat outs是一个输入图像经过网络前向传播后输出的85*845矩阵,其定义如下图所示:
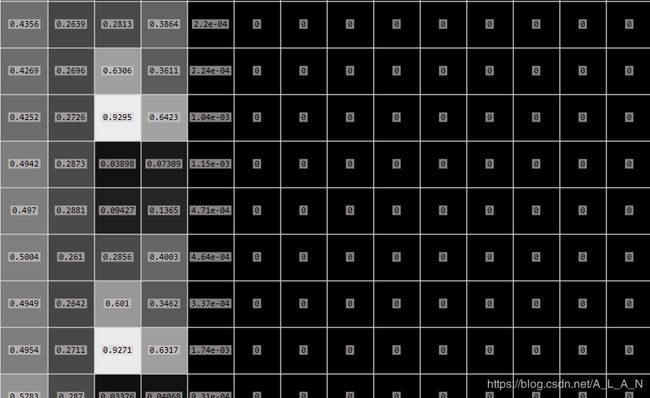
行向量解析:前面4个元素是用来标记目标在图像上的位置的(被归一化了),第5个元素是置信概率,值域为[0-1](用来与阈值作比较决定是否标记目标),后面80个为基于COCO数据集的80分类的标记权重,最大的为输出分类。
列向量解析:为什么是845个?因为YOLO会把图像分成13*13的网格,每个网格预测5个BOX(所以就是13*13*5=845),每个BOX就是一个行向量。
5、结果:

参考:
Deep Learning based Object Detection using YOLOv3 with OpenCV ( Python / C++ )
YOLOv3在OpenCV4.0.0/OpenCV3.4.2上的C++ demo实现