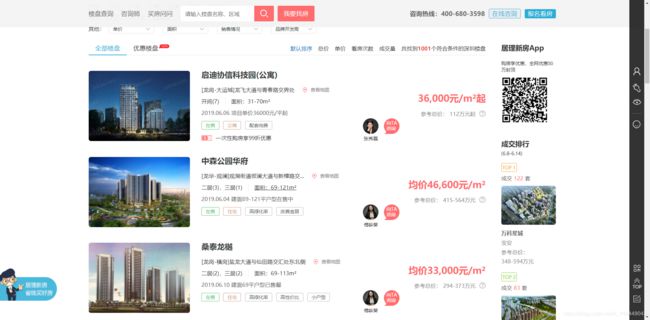
爬取深圳房源销售情况
此次数据来源于居里新房,仅作参考使用,如有侵权,请联系我[email protected],会立即删除
_深圳的房是买不起,可以看看,那就爬取开盘销售情况,仅供参考。_
首先在items.py定义一下所需要爬取的数据名,简单来说就是定义变量
```# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
#定义目标数据的字段
class TCItem(scrapy.Item):
#居理新房所需要用到的参数
name = scrapy.Field() # 小区名
sale = scrapy.Field() # 是否售出
ReferencePrice = scrapy.Field() # 参考单价
ReferToTheTotalPrice = scrapy.Field() # 参考总价
ResidentialAddress = scrapy.Field() # 楼盘地址
OpeningTime = scrapy.Field() # 开盘时间
roomURL = scrapy.Field() # 楼盘所在链接
```
接下来我们需要编写爬虫部分,一个项目可以有多个爬虫,在这里面,先拿到每页的每一个开盘小区的URLl,通过正则匹配到需要抓取的信息,例如开盘时间,参考价格,每拿到一条数据就返回一次,以提高执行效率,提取页码,然后通过拼接构造每一页的URL,翻到末页就结束递归。
```
# -*- coding: utf-8 -*-
import scrapy
import re
#导入自定义的包
from MyScrapy.items import MyscrapyItem
class JulixinfangSpider(scrapy.Spider):
name = 'JuLiXinFang'
allowed_domains = ['sz.julive.com']
page = 10
url = r'https://sz.julive.com/project/s/z'
start_urls = [url + str(page)]
def parse(self, response):
data = response.body.decode('utf-8') # 获取响应内容
header = {
'Accept': 'text / html, application / xhtml + xml, application / xml;q = 0.9, * / *; q = 0.8'
'Accept-Encoding:gzip, deflate, br'
'Accept-Language: en-US, en; q=0.8, zh-Hans-CN; q=0.5, zh-Hans; q=0.3'
'Host: movie.douban.com'
'Referer: https://movie.douban.com/'
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763'
}
data = response.body.decode('utf-8')
# 获取每一页标签
pat = r'
# 提取所需数据
pat_1 = r'(.*?)
'
pat_2 = r'参考总价\s*\s*(.*)'
pat_3 = r'\s*(\d+,.*)/m² '
pat_4 = r'\s*\s*(.*)'
pat_5 = r'''data-sa-point='{"event":"e_click_surrounding_analysis_entry","properties":{"fromModule":"m_basic_info","fromItem":"i_surrounding_analysis_entry","fromItemIndex":"-1","toPage":"p_project_home","toModule":""}}'>(.*?)'''
pat_6 = r'\s*\s*(.*\d+)\s'
pat_x = response.url # 房子所在链接
# 清洗数据
try:
item['name'] = re.findall(pat_1, data_a)[0]
except:
item['name'] = '\t'
print(re.findall(pat_1, data_a))
try:
item['sale'] = re.findall(pat_2, data_a)[0]
except:
try:
item['sale'] = re.findall(r'\s*(.*?)\s*', data_a)[0]
except:
item['sale'] = '\t'
print(item['sale'])
try:
item['ReferencePrice'] = re.findall(pat_3, data_a)[0]
except:
item['ReferencePrice'] = re.findall(r'(.*?)', data_a)[0]
print(re.findall(pat_3, data_a))
try:
item['ReferToTheTotalPrice'] = re.findall(pat_4, data_a)[0]
except:
item['ReferToTheTotalPrice'] = re.findall(r'(.*?)
', data_a)[0]
print(re.findall(pat_4, data_a))
try:
item['ResidentialAddress'] = re.findall(pat_5, data_a)[0]
except:
item['ResidentialAddress'] = re.findall(r'''"p_surrounding_analysis","toModule":""}}'>(.*)''', data_a)[0]
print(re.findall(pat_5, data_a))
try:
item['OpeningTime'] = re.findall(pat_6, data_a)[0]
except:
item['OpeningTime'] = re.findall(r'(.*?)
', data_a)[1]
print(re.findall(pat_6, data_a))
item['roomURL'] = pat_x
# 返回数据
yield item
```
数据的抓取,清洗部分已经写好了,接下来,我们要做的就是保存到数据库,这需要在管道文件pipelines.py中编写代码,以保存到数据库中
```
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
#管道文件,负责item的后期处理或保存
class MyfirstscrapyPipeline(object):
def __init__(self):#定义一些需要初始化的参数
#连接数据库
self.connect = pymysql.Connect(host='localhost',port=3306,user='*****',password='******',db='scrapyspider',charset='utf8')
self.cursor = self.connect.cursor()
#self.file = open('tengxun.csv','a+')
#管道每次接收到item后执行的方法
#return item 必须要有
def process_item(self, item, spider):
#往数据库写入数据
'''
self.cursor.execute(
'insert into julixinfang(小区名,是否售出,参考单价,参考总价,楼盘地址,开盘时间,链接) value (%s,%s,%s,%s,%s,%s,%s)',
(
item['name'],
item['sale'],
item['ReferencePrice'],
item['ReferToTheTotalPrice'],
item['ResidentialAddress'],
item['OpeningTime'],
item['roomURL']
)
)
'''
self.connect.commit()
#当爬取执行完毕时执行的方法
def close_spider(self,spider):
#关闭数据库连接
self.cursor.close()
self.connect.close()
#self.file.close()
```
数据写入完毕,比对下数据
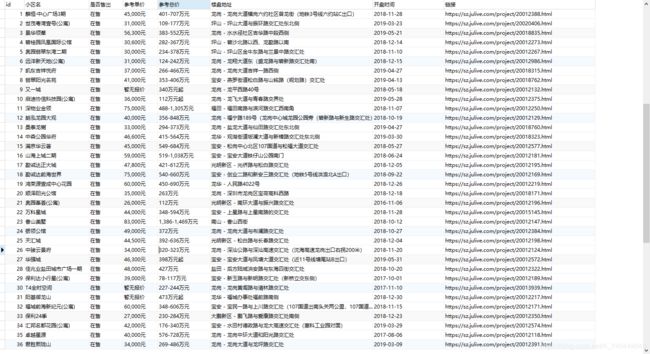
只爬数据,不谈其他,不发表任何意见