Python网络爬虫与信息提取(三)bs4入门
Python的requests库可以帮助我们获取到大量的信息,而如果想对这些信息进行提取与分析,则经常使用beautifulsoup这个用来解析HTML和XML格式的功能库。
beautifulsoup库的安装和requests的流方法一样,可直接在cmd中输入pip install beautifulsoup4来安装,安装完成后可直接在IDLE中输入import bs4来验证是否安装成功。
接下来我们以python123.io中一个专为bs4库设计的网页为例来体验下bs4库的基础操作。

其中prettify()方法可以在各节点之间加入换行符已使打印出来的解析文本可读性更高:

可以看到,想使用bs4来解析网页信息时,我们需要将待解析的网页的html信息传入BeautifulSoup这个类中,再将我们想使用的解析器作为第二个参数传入类中,然后我们可以通过prettify这个方法来将解析后的网页打印出来。
bs4中除了可以使用html.parser这个解析器之外,还可以使用lxml的HTML与XML解析器以及html5lib的解析器,使用之前只需安装对应的解析器的库即可。
由此可见BeautifulSoup的主要用途是对HTML和XML的“标签树”进行解析、遍历和维护,只要给它提供的文本为标签类型,它都能对其进行解析,可以简单的将BeautifulSoup类当成一个HTML文档的全部内容。
BeautifulSoup类的基本元素与HTML和XML的语法格式是一一对应的,下面将以此为基础对这个类中的元素进行介绍。
| 基本元素 | 说明 |
| Tag | 标签,最基本的信息组织单元,分别用<>和标明开头和结尾 |
| Name | 标签的名字, ... 的名字是'p',格式: |
| Attributes | 标签的属性,字典形式组织,格式: |
| NavigableString | 标签内非属性字符串,<>...中字符串,格式: |
| Comment | b标签内字符串的注释部分,一种特殊的Comment类型 |
我们仍以刚才的soup为例:
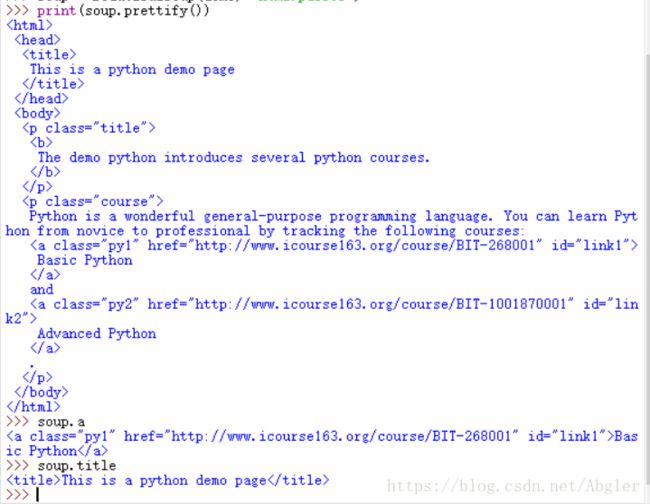
我们可以用soup.tag来返回对应的tag里的内容,当文档中存在多个tag时默认只返回第一个tag,


同理我们可以用相应的方法获取标签的名字及属性,又因为属性返回的是一个字典值,所以我们可以将对字典操作的方法直接用于操作属性值,其他元素的使用方法也如此。
其中要特别注意BeautifulSoup对HTML中的注释返回的值并没有标明,所以直观上无法区分哪些是注释哪些是文本中的字符串,所以在实际分析时可以通过type方法来对两者加以区分。
