heartbeat+drdb
Heartbeat
heartbeat (Linux-HA)的工作原理:heartbeat最核心的包括两个部分,心跳监测部分和资源接管部分,心跳监测可以通过网络链路和串口进行,而且支持冗 余链路,它们之间相互发送报文来告诉对方自己当前的状态,如果在指定的时间内未收到对方发送的报文,那么就认为对方失效,这时需启动资源接管模块来接管运 行在对方主机上的资源或者服务。
Heartbeat包括以下几个组件:
heartbeat – 节点间通信校验模块 CRM - 集群资源管理模块
CCM - 维护集群成员的一致性 LRM - 本地资源管理模块
StonithDaemon - 提供节点重启服务 logd - 非阻塞的日志记录
apphbd - 提供应用程序级的看门狗计时器 Recovery Manager - 应用故障恢复
底层结构–包括插件接口、进程间通信等
CTS – 集群测试系统,集群压力测试
这里主要分析的是Heartbeat的集群通信机制,所以这里主要关注的是heartbeat模块。
heartbeat模块由以下几个进程构成: master进程(masterprocess)
FIFO子进程(fifochild) read子进程(readchild) write子进程(writechild)
在heartbeat里每一条通信通道对应于一个write子进程和一个read子进程,假设n是通信通道数,p为heartbeat模块的进程数,则p、n有以下关系:
p=2*n+2
在heartbeat里,master进程把自己的数据或者是客户端发送来的数据,通过IPC发送到write子进程,write子进程把数据发送到网络;同时read子进程从网络读取数据,通过IPC发送到master进程,由master进程处理或者由master进程转发给其客户端处理。
Heartbeat启动的时候,由master进程来启动FIFO子进程、write子进程和read子进程,最后再启动client进程
可靠性: Heartbeat通过插件技术实现了集群间的串口、多播、广播和组播通信,在配置的时候可以根据通信媒介选择采用的通信协议,heartbeat启动的时候检查这些媒介是否存在,如果存在则加载相应的通信模块。Heartbeat采用UDP协议和串口进行通信,它们本身是不可靠的,可靠性必须由上层应用来提供。那么怎样保证消息传递的可靠性呢?Heartbeat通过冗余通信通道和消息重传机制来保证通信的可靠性。Heartbeat检测主通信链路工作状态的同时也检测备用通信链路状态,并把这一状态报告给系统管理员,这样可以大大减少因为多重失效引起的集群故障不能恢复。
现在我们来配置一下heartbeat
系统环境 rhle6.5 selinux 和 iptables 关闭
主机 smartboy1.example.com 172.25.20.11
smartboy2.example.com 172.25.20.12
在smartboy1和2 上同时进行如下操作
下载heartbeat rpm包 heartbeat-3.0.4-2.el6.x86_64.rpm heartbeat-libs-3.0.4-2.el6.x86_64.rpm
heartbeat-devel-3.0.4-2.el6.x86_64.rpm ldirectord-3.9.5-3.1.x86_64.rpm
yum install * -y 安装上述软件包
cd /etc/ha.d/
通过查看readme如下图 我们可以看到

我们需要三个配置文件 ha.cf (主配置文件) haresource(资源配置文件) authkeys(安全认证文件)
rpm -q heartbeat -d 查看这些文件所在位置
cp -p /usr/share/doc/heartbeat-3.0.4/ha.cf /etc/ha.d/
cp -p /usr/share/doc/heartbeat-3.0.4/haresources /etc/ha.d/
cp -p /usr/share/doc/heartbeat-3.0.4/authkeys /etc/ha.d/
编辑ha.cf文件
去掉24行 debugfile 前的#号
去掉29行 logfile 前的#号
去掉48行 keepalive 前的#号
去掉56行 deadtime 前的#号
去掉61行 warntime 前的#号
去掉71行 initdead 前的#号 initdead时间可以根据自己的需求修改,前面的deadtime warntime 也都一样
去掉76行 udport 前的#号 端口可以根据自己需要来修改,但是两台主机必须一致。
去掉80行baud 前的#号
去掉91行bcast eth0 前的#号
211和212行 node节点写两台主机名,哪个在前哪个为主
220行ping 172.25.20.250
253行respawn hacluster /usr/lib64/heartbeat/ipfail 放开
259行apiauth ipfail gid=haclient uid=hacluster 放开
保存退出
编辑haresources文件
最后一行编写
smartboy1.example.com IPaddr::172.25.20.100/24/eth0 httpd
保存退出
编辑authkeys文件
去掉23行auth 1 ,24行1crc #号
启动heartbeat : /etc/init.d/heartbeat start

竟然报错了!WTF!
不慌我们来看看报错信息,它说Bad permission on keyfile [/etc/ha.d/authkeys] 600 recommend
那我们把/etc/ha.d/authkeys 权限修改一下试试
chmod 600 /etc/ha.d/authkeys smartboy2.example.com上也同时修改
重启heartbeat
然后我们smartboy1上 ip addr show

可以看到哪个我们在配置文件里写的vip 172.25.20.100
停掉smartboy1 上的服务 /etc/init.d/heartbeat stop
在另一边ip addr show 我们同样也看到了vip 172.25.20.100
2顺利接管了1的服务
在1上又一次启动heartbate 服务
这个vip 跳回到1
我们再来编写一个apache发布页测试一下
在smartboy1.example.com上
echo ‘
samrtboy1.example.com’ > /var/www/html/index.html
在smartboy2.example.com上
echo ‘
samrtboy2;.example.com’ > /var/www/html/index.html
打开浏览器访问 172.25.20.100

可以看到1上的信息
停掉1上的服务 /etc/init.d/heartbeat stop
刷新网页

可以看到2立即接管了1的服务
再次重启1上的服务
刷新网页跳回到1上
congratulations 成功了
Drbd:
DRBD是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。
DRBD是一种块设备,可以被用于高可用(HA)之中.它类似于一个网络RAID-1功能.当你将数据写入本地文件系统时,数据还将会被发送到网络中另一台主机上.以相同的形式记录在一个文件系统中.
本地(主节点)与远程主机(备节点)的数据可以保证实时同步.当本地系统出现故障时,远程主机上还会
保留有一份相同的数据,可以继续使用.
Drdb主要有三种模式:单主模式 ,复主模式,复制模式。
单主模式是典型的高可用集群方案,
复主模式:需要采用共享cluster文件系统,如GFS和OCFS2。用于需要从2个节点并发访问数据的场合,需要特别配置。(不能采用ext4这种本地文件系统。)
复制模式有协议A、B、C三种:协议A:异步复制协议。本地写成功后立即返回,数据放在发送buffer中,可能丢失。协议B:内存同步(半同步)复制协议。本地写成功并将数据发送到对方后立即返回,如果双机掉电,数据可能丢失。协议C:同步复制协议。本地和对方写成功确认后返回。如果双机掉电或磁盘同时损坏,则数据可能丢失。
Split brain:当网络出现暂时性故障,导致两端都自己提升为Primary。两端再次连通时,可以选择email通知,建议手工处理这种情况。
配置drbd
系统环境:rhel6.5 selinux 和iptables 关闭
主机 smartboy1.example.com 172.25.20.11
smartboy2.example.com 172.25.20.12
官网下载 drbd-8.4.0.tar.gz 软件包 www.drdb.org
yum install gcc flex rpm-build kernel-devel -y 解决依赖性
在smartboy1主机家目录里生成rpmbuild编译所需路径
tar zxf drbd-8.4.0.tar.gz 解包
cp drbd-8.4.0.tar.gz rpmbuild/SOURCES/smartboy1.example.com IPaddr::172.25.20.100/24/eth0 drbddisk::example Filesystem::/dev/drbd1::/var/www/html::ext4 httpd
cd cd drbd-8.4.2
./configure --enable-spec --with-km
rpmbuild -bb drbd.spec 编译生成drbd rpm包
cd rpmbuild/RPMS/x86_64
rpm -ivh *
把生成的rpm包拷贝到另一台主机并安装
rpmbuild -bb drbd-km.spec 编译drbd内核模块
rpm -ivh drbd-km*
把生成的rpm包拷贝到另一台主机并安装
cd /etc/drbd.d/
编辑drbd.res 文件 如下

编辑完拷贝到另一台主机
scp /etc/drbd.d/drbd.res 172.25.20.12:/etc/drbd.d/
在两台主机上执行以下命令
drbdadm create-md example
/etc/init.d/drbd start
在smartboy1上执行
drbdadm primary example --force 将1设为主节点
在两台主机上查看同步状态
cat /proc/drbd
数据同步结束后创建文件系统
mkfs .ext4 /dev/drbd1
挂载
mount /dev/drbd1 /mnt/ (只有主节点可以挂载)
umount /mnt/
将smartboy2.example.com设为主节点:
先把1设为次节点drbdadm secondary example
2设为主节点 drdadm primary example
故障排除:
中断smartboy1.example.com的网络/etc/init.d/network stop
2上再次查看状态 drbd-overview
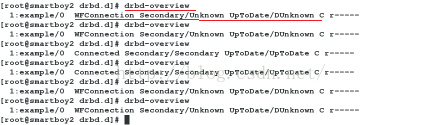
在1上执行drbd-overview
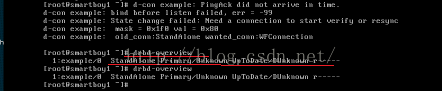
很明显玩坏了
先把1的网络开起来/etc/init.d/network start
再执行drbd-overview

我们在2上执行drbdadm disconnect example断开连接
drbdadm connect --discard-mydata example 舍弃自身数据
在1上drbdadm connect example重新连接一下
drbd-overview 查看正常

编辑/etc/ha.d/haresources文件 编辑最后一行写入:
smartboy1.example.com IPaddr::172.25.20.100/24/eth0 drbddisk::example Filesystem::/dev/drbd1::/var/www/html::ext4 httpd
df 查看/dev/drbd1是否挂载上
/etc/init.d/heartbeat restart 重启hearbeat服务
echo ‘
smartboy.example.com’ > /var/www/html/index.html
打开浏览器访问172.25.20.100
在浏览器上可以看到smartboy.example.com
OK perfect!
Lvs
LVS集群采用IP负载均衡技术和基于内容请求分发技术。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序。为此,在设计时需要考虑系统的透明性、可伸缩集群采用三层结构性、高可用性和易管理性。
集群采用三层结构 负载调度器(loadbalancer)、服务器池(server pool)、共享存储(shared storage)
四种模式:
NAT模式
TUN模式
DR模式
FULLNAT模式
Lvs共十种调度算法:
1.rr:roundrobin轮询
2.wrr:weight 权重以权重之间的比例实现在各主机之间进行调度
3.sh:source hashing 源地址散列,主要实现会话绑定,能够将此前建立的session信息保留了
4.Dh:Destination hashing 目标地址散列,把同一个IP地址的请求,发送给同一个server。
5.lc(Least-Connection):最少连接,最少连接调度算法是把新的连接请求分配到当前连接数最小的服务器
6.wlc(Weighted Least-Connection Scheduling):加权最少连接,加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。
7.sed(Shortest Expected Delay):最短期望延迟
8.nq(never queue):永不排队(改进的sed)
9.LBLC(Locality-Based Least Connection):基于局部性的最少连接
10.LBLCR(Locality-Based Least Connections withReplication):带复制的基于局部性最少链接
虚拟主机:
smartboy1.example.com 172.25.20.11
smartboy2.example.com 172.25.20.12
smartboy3.example.com 172.25.20.13
smartboy4.example.com 172.25.20.14
在smartboy1上
ip addr add 172.25.20.100/24 dev eth0
Ipvsadm -A -t 172.25.20.100:80 -s rr
Ipvsadm -a -t 172.25.20.100:80 -r 172.25.20.13:80 -g
Ipvsadm -a -t 172.25.20.100:80 -r 172.25.20.14:80 -g
/etc/init.d/ipvsadm save
在server3和server4上
ip addr add 172.25.20.100/32 dev eth0
yum install arptables_jf -y
yum install httpd -y
arptables -A IN -d 172.25.20.100 -j DROP
arptables -A OUT -d 172.25.20.100 -j mangle --mangle-ip-s 172.25.20.13 | 172.25.20.14
/etc/init.d/arptables save
编写apache发布目录
vim /var/www/html/index.html
客户端主机 arp -an | grep 172.25.20.100
arp -d 172.25.20.100
在浏览器上访问172.25.20.100即可实现轮循访问
在smartboy1上执行以下操作
ip addr del 172.25.20.100
cp /usr/share/doc/ldirectord-3.9.5/ldirectord.cf /etc/ha.d/
cd /etc/ha.d/
编辑 ldirectord.cf 文件
virtual =172.25.20.100:80
real= 172.25.20.13:80 gate
real=172.25.20.14:80 gate
fallback=127.0.0.1:80 gate #如果两个real server都挂了访问本地
service=http
secheduler=rr #轮询round rubin
protocol=tcp #tcp协议
checktype=negotiate
checkport=80
request=”index.html”
编写haresources 文件
最后一行smartboy1.example.com IPaddr::172.25.20.100/24/eth0 ldirectorddrbddisk::example Filesystem::/dev/drbd1::/var/www/html::ext4 httpd
复制这两个文件到smartboy2上
在1和2两个主机上执行
/etc/init.d/ldirectord start
/etc/init.d/heartbeat start
Ok 一切就绪