hadoop2.7第一个python实例(超详细)
没有任何基础,第一次跑hadoop实例,遇到不少问题,记录下来以便自查和帮助同样情况的hadoop学习者。
参考博客:https://www.cnblogs.com/end/archive/2012/08/13/2636175.html
集群组成:VMwawre14.1+CentOS6.5+hadoop2.7, 3个虚拟机节点,分别为master、slave1,slave2
hadoop安装目录:/opt/hadoop
例子:模仿 WordCount 并使用Python来实现,例子通过读取文本文件来统计出单词的出现次数。结果也以文本形式输出,每一行包含一个单词和单词出现的次数,两者中间使用制表符来想间隔。
本文章主要讲跑通例子的操作,原理看上面的参考博客。
一、下载文本文件
- The Outline of Science, Vol. 1 (of 4) by J. Arthur Thomson
- The Notebooks of Leonardo Da Vinci
- Ulysses by James Joyce
从以上三个网址中复制三本书出来,粘贴到windows上新建的txt中,另存为Science.txt、Notebooks.txt、Ulysses.txt,记得在另存为的窗口中,右下角选择utf-8编码,最后将此三本书复制到集群中的master虚拟机中,临时保存目录为:/tmp/gutenberg
[CAI@master ~]$ ls -l /tmp/gutenberg
total 3524
-rwxrw-rw- 1 CAI CAI 1396148 Sep 16 11:42 Notebooks.txt
-rwxrw-rw- 1 CAI CAI 661810 Sep 16 11:42 Science.txt
-rwxrw-rw- 1 CAI CAI 1548179 Sep 16 11:42 Ulysses.txt
二、windows文件转linux文件
从windows中直接拷贝文件到linux,由于两个系统的换行符表示不一样,所以会有识别问题。比如从windows中编写一个demo.py文件,虽然加了在文件首行输入#!/usr/bin/env python,以便在linux上跑,但是执行时会出现No such file or directory,其实是找不到python命令文件,原因是:
windows文件格式是DOS,而非UNIX格式。Windows格式下,换行符是CRLT,使得demo.py第一行变成了#!/usr/bin/env python\015(CR的ascaii 15)
使用Linux VIM检查文件格式:":set ff 或者:set fileformate"
使用Linux VIM转换文件格式:“:set ff=unix或者:set fileformate=unix”
使用Windows UltraEdit做文件格式转换:“file->Conversions->DOS->UNIX”
也就是说从windows中拷贝到linux的文件,用vim打开该文件,在命令行模式下面输入‘:set ff’则可以查看到格式为dos, 用命令“:set ff=unix”就可以改为unix。
用以上方法将Science.txt、Notebooks.txt、Ulysses.txt三本书的格式改为unix。以后拷贝进来的windows文件都可进行此操作。
三、编写python文件
由于不太熟悉linux的vim编辑,所以在windows上编写mapper.py、reducer.py可执行文件.
mapper.py:
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print '%s\\t%s' % (word, 1)
reducer.py:
#!/usr/bin/env python
from operator import itemgetter
import sys
word2count = {}
for line in sys.stdin:
line = line.strip()
word, count = line.split('\\t', 1)
try:
count = int(count)
word2count[word] = word2count.get(word, 0) + count
except ValueError:
pass
sorted_word2count = sorted(word2count.items(), key=itemgetter(0))
for word, count in sorted_word2count:
print '%s\\t%s'% (word, count)
将此两个文件复制黏贴到集群master虚拟机上,目录为/home/CAI/Downloads/
对此两文件进行上面的第二步操作,将windows文件转为linux文件
给以上两个文件赋予可执行权限:
chmod +x /home/CAI/Downloads/mapper.py
chmod +x /home/CAI/Downloads/reducer.py
四、测试代码
在运行MapReduce job测试前尝试手工测试mapper.py 和 reducer.py脚本,以免得不到任何返回结果
[CAI@master ~]$ echo "foo foo quux labs foo bar quux" | /home/CAI/Downloads/mapper.py
foo 1
foo 1
quux 1
labs 1
foo 1
bar 1
quux 1
[CAI@master ~]$ echo "foo foo quux labs foo bar quux" | /home/CAI/Downloads/mapper.py | /home/CAI/Downloads/reducer.py
bar 1
foo 3
labs 1
quux 2
五、复制文本数据到HDFS
1、首先创建hdfs目录,可以在master虚拟机上任何地方。注意创建目录和查看目录都需要用hadoop自有的命令,而非linux的 命令;另外在执行/opt/hadoop/bin/hadoop fs -mkdir /new_dir创建new_dir目录时出错了。从报错中发现是版本的原因,2.x以前的版本这个命令,2.x之后的版本命令改成了:/opt/hadoop/bin/hdfs dfs -mkdir -p /new_dir。
本人创建hdfs目录的命令如下:
[CAI@master ~]$ /opt/hadoop/bin/hdfs dfs -mkdir -p /usr/hadoop
注意:[CAI@master hadoop]$ /opt/hadoop/bin/hdfs dfs -rm -r -f /usr/hadoop 可以删除目录
查看刚刚创建的目录,此处用ls /usr是查看不到hadoop目录的,必须要用hadoop自己的命令查看:
[CAI@master ~]$ /opt/hadoop/bin/hdfs dfs -ls /usr/hadoop
18/09/16 15:00:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - CAI supergroup 0 2018-09-16 14:58 /usr/hadoop
查询结果如上蓝色字体部分,上面红色字体部分为警告,解决上述警告的参考博客为:
https://blog.csdn.net/jack85986370/article/details/51902871
注意解决上述警告问题需要在所有节点都操作一遍,别只给master纠正,slave1和slave2也要纠正(集群配置更改要时刻记得 所有节点)。
2、将含三本书的/tmp/gutenberg目录复制到刚刚创建的hdfs目录中:
[CAI@master ~]$ /opt/hadoop/bin/hdfs dfs -copyFromLocal /tmp/gutenberg /usr/hadoop/gutenberg
查看复制效果:
[CAI@master ~]$ /opt/hadoop/bin/hdfs dfs -ls /usr/hadoop/gutenberg
Found 3 items
-rw-r--r-- 2 CAI supergroup 1396148 2018-09-16 15:07 /usr/hadoop/gutenberg/Notebooks.txt
-rw-r--r-- 2 CAI supergroup 661810 2018-09-16 15:07 /usr/hadoop/gutenberg/Science.txt
-rw-r--r-- 2 CAI supergroup 1548179 2018-09-16 15:07 /usr/hadoop/gutenberg/Ulysses.txt
六、执行MapReduce job
1、在hadoop安装目录下(省的写绝对路径),执行命令:
![]()
注意:以上命令中最后的输出目录gutenberg-output不能已存在(上一次执行若出错,这个文件夹就会已存在),若存在了会报错,得先删除该存在的目录:[CAI@master hadoop]$ ./bin/hdfs dfs -rm -r -f /usr/hadoop/gutenberg-output
即便没碰到上面问题,还是有错误,可看到其中一条日志如下:
java.io.IOException: Cannot run program "/home/CAI/Downloads/mapper.py": error=2, No such file or directory
因为mapper.py经过第四大步测试,是可以成功执行的,经过命令java --version可以看到正常输出java版本,暂时没考虑java问题。后来再度看上面的错误,是找不到文件mapper.py,突然想到经过上面第三大步骤,虽然master上有文件mapper.py和reducer.py,但是两个数据节点却没有,于是将此两文件拷贝到两数据节点的/home/CAI/Downloads/目录中,再次执行,成功!
记住:可执行文件一定要拷贝到所有节点上去!
执行过程中的部分日志如下图所示:

在master节点,打开火狐浏览器,登录http://192.168.137.130:8088/,可以看到如下图:
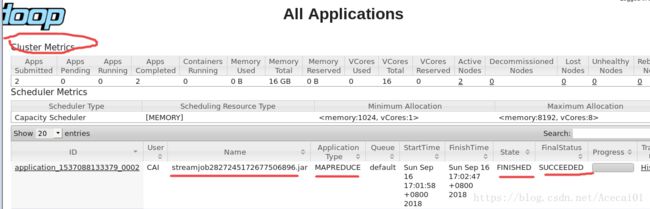
检查结果是否输出并存储在HDFS目录下的gutenberg-output中:
[CAI@master hadoop]$ ./bin/hdfs dfs -ls /usr/hadoop/gutenberg-output
Found 2 items
-rw-r--r-- 2 CAI supergroup 0 2018-09-16 17:02 /usr/hadoop/gutenberg-output/_SUCCESS
-rw-r--r-- 2 CAI supergroup 878875 2018-09-16 17:02 /usr/hadoop/gutenberg-output/part-00000
查看输出结果的前15行:
[CAI@master hadoop]$ ./bin/hdfs dfs -cat /usr/hadoop/gutenberg-output/part-00000 | head -15
"(Lo)cra" 1
"1490 1
"1498," 1
"35" 1
"40," 1
"A 2
"AS-IS". 1
"A_ 1
"Absoluti 1
"Aesopi" 1
"Alack! 1
"Alack!" 1
"Alla 1
"Allegorical 1
"Alpha 1
注意输出,上面结果的(")符号不是Hadoop插入的。
操作完毕!