钢琴转录论文Onsets and Frames:dual-objective piano transcription
论文|Onsets and frames: dual-objective piano transcription
1.文章出处
发在2018ISMIR,来自Google Brain团队,paper链接
论文笔记放在github上了
2.文章简介
“这篇文章已经把钢琴自动转录未来五年甚至十年的工作都做完了”. 我们用程序Demo转换了一首比较复杂的钢琴曲,听到转录的结果, 于是发出了这样的感叹.
本篇论文主要解决的问题是复音钢琴自动转录,也就是将原始的钢琴演奏音频转换为MIDI表示.
这篇论文的主要方法使用了一个onset检测器和一个framewise检测器,framewise检测器的预测值收到onset检测器值的限制:只有onset检测器同意在帧中有onset的存在,framewise检测器才会预测一个新的音符.作者认为只有同时改善音符的onset和offset才符合人类对音乐的感知.作者还拓展了模型预测velocity值,使得转录的结果听起来更加自然.
在MAPS数据集的转录结果在Note,Frame,以及Note(带offset)的F1 score相较于之前的state-of-the-art都有足足一倍的提升!!
本文还提出了一个新的评价指标:note with offset
3.文章主要方法
3.1 mel-spectrograms参数
229 mel-bins, 2048 FFT Window size, 16000Hz采样率.将该频谱结果作为CNN的输入.
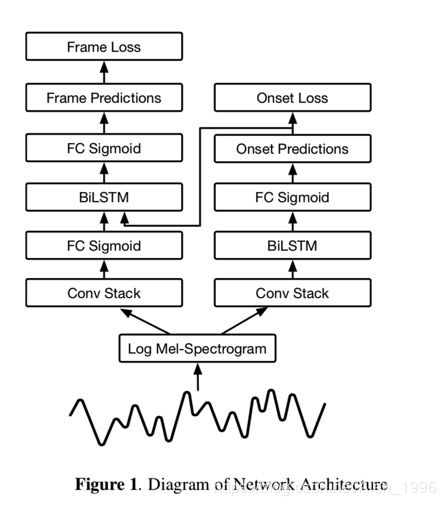
3.2 onset detector
卷积层的输出作为128 units双向LSTM的输入,LSTM后接一个88 维输出的全连接层,88维的输出表示88个钢琴key的onset概率.
3.3 framewise detector
这个检测器的构成略有不同,首先是卷积层,接一个88维输出的全连接层,这个88维的输出向量会和onset detection端的对88个钢琴key的onset预测向量concatenate成一个176维向量,再过一个88维输出的全连接层.
3.4 Loss
总的loss是由onset端和note端两个cross-entrophy组成.
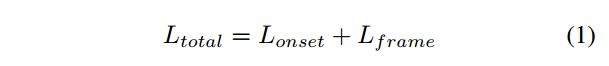
p m i n p_{min} pmin和 p m a x p_{max} pmax表示MIDI的音高范围,T代表样本中有帧的数目, I o n s e t ( p , t ) I_{onset}(p,t) Ionset(p,t) 是一个标志值,当在帧t和音高p处有一个真实的onset时,它的值为1. P o n s e t ( p , t ) P_{onset}(p,t) Ponset(p,t)表示模型在帧t和音高p处预测概率表示,CE代表交叉熵.
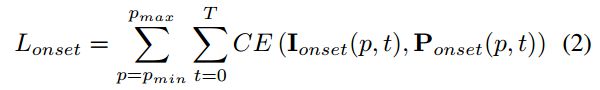
作者在这里定义了note端frame loss: 当在帧t如果音高p有真实标注值时, I f r a m e ( p , t ) I_{frame}(p,t) Iframe(p,t)是1, P f r a m e ( p , t ) P_{frame}(p,t) Pframe(p,t)则是代表模型预测的帧t处音高p被激活的概率.
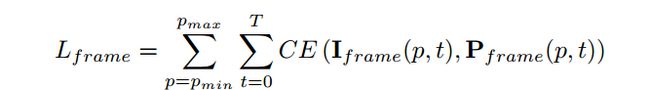
值得注意的是,作者为了激励模型对音符起始端的预测准确率,对上面的frame loss加了一个额外的权值.我们记上面的frame loss为 L f r a m e ′ ( l , p ) L'_{frame}(l,p) Lframe′(l,p),假设一个音符的onset在帧 t 1 t_{1} t1处,在帧 t 2 t_{2} t2处完成onset,在 t 3 t_{3} t3处结束音符,如果我们给权值向量在音符的初始帧处赋予更高的权值,那么激励模型更加准确的预测音符的起始端.也就能够保留piece中最重要的musical events.
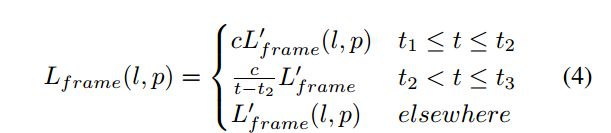
这里c=5.0,作者做了coarse hyperparameter得到的.
作者将模型继续拓展,增加了一个模型预测每一个onset的velocities,这个模型和其他两个模型相同且包含了同样的卷积层,但是这个模型和其他两个没有联系.
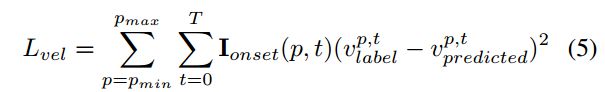
在上述实验中velocity的标签被归一化到了[0,1]间,是一个piece中所有的vecolity都被除以了这个piece中最大的velocity,将归一化后的velocity转换回来使用以下映射.
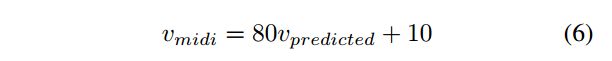
作者发现在帧上和pitch上做对velocity的评价指标在之前的研究是一片空白,为此作者提出了新的note-level上的precision,recall,F1 scores.
直接对velocity评价不易,因为不像pitch和帧,velocity没有绝对的意义.比如说两个转录都包含了同一个确定的velocity,如果这两个velocity由某个常数因子偏移或者缩放了,导致每个音符的velocity完全不同,但是这两个转录系统仍然是非常等价的.
为此作者做了以下处理:先将转录中的真实velocity全部归一化到[0,1],将所有音符根据音高,onset和offset匹配好,为这些匹配好的音符加上真实的velocity和模型估计的velocity,然后做一个线性回归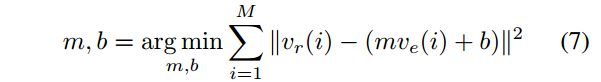
其中M是匹配的个数,估计出m和b之后,使用这两个参数估计新的 v e v_{e} ve
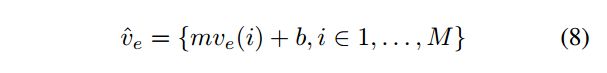
最后定一个阈值 τ \tau τ=0.1,选取 ∣ v e ^ ( i ) − v r ( i ) ∣ < τ \begin{array}{l}\left|\widehat{v_e}(i)-v_r(i)\right|<\tau\\\end{array} ∣ve (i)−vr(i)∣<τ,这样就消除了偏移或者缩放的问题.
选取符合条件的匹配,重新计算precision,recall,F1 score.
4.实验结果
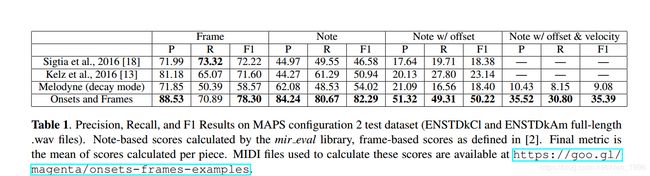
可以看到Onsets and Frames算法在四类评价指标上在之前的state-of-the-art相比都取得了巨大的提升,甚至在某些指标上取得了100%的提升.
值得一提的是,这篇文章发在2018年ISMIR上,大约四月截稿,在2018年10月截稿的2019年一篇ICASSP论文"Deep Polyphonic ADSR Piano Note Transcription",来自奥地利的研究者又在MAPS数据集上刷新了state-of-the-art谷歌brain的人并不服输,还是这篇论文的作者们在2019年ICLR上的一篇论文"Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset"又在ICASSP这篇文章上结果上大幅刷新state-of-the-art.有趣的是.这篇文章是2018.10.29提交到arxiv上的,而2019icassp正好是10.29截止.好险,要是再晚一两个月.说不定那篇文章就中不了了.由此也可以看出这个钢琴转录的课题普通课题组绝对不要碰了,浪费时间.
2019.7.3补充
在最近的一篇论文|Enabling Factorized Piano music Modeling And Generation With The Maestro dataset。performance又大幅得到提升,主要原因得益于新的数据集音符标注和音频小于3ms。
Onset and Frames模型改动
- 加入了offset detection head, 受到论文Deep Polyphonic ADSR Piano Note Transcription的启发,offset head直接喂给frame detector,但是在解码的时候没有直接使用,offset head定义成每个音符的最后32ms
- 双向LSTM,从128增加到256个units, 卷积层的卷积核个数从32/32/64 增加到48/48/96 , 全连接层从512 增加到768
- 停止梯度从frame network端流向onset端
- 将mel 频谱转换成HTC 频率
- 作者在训练的首使用了数据增强,比如使用半音pitch shift,压缩,加入噪音等,数据增强的方式使得这个模型在MAPS数据集上有效果提升,但是在Maestro数据集上验证的结果则是由轻微地变差