将word2Vec应用在推荐系统
翻译自文章:http://mccormickml.com/2018/06/15/applying-word2vec-to-recommenders-and-advertising/
过去几年中word2vec模型不仅仅应用在自然语言任务,而且也逐渐地应用在推荐系统和广告上。
word2vec背后的关键原则:一个词的含义可以从它的上下文语境中推断出来 。 更抽象的,文本实际上只是一个单词序列,一个单词的含义可以从这个单词之前和之后的几个单词中提取出来。
研究人员发现,在线用户活动的时间序列和从上下文推断单词的含义一致:当用户浏览并与之交互时,可以从用户前后交互的内容推断出一条抽象内容。 因此,ML团队可以应用词向量模型来学习产品,内容和广告等内容的向量表示。
“来自网络搜索、电子商务和市场领域的研究人员已经意识到,就像人们可以通过将句子中的一系列单词视为上下文来训练词向量一样,我们也可以将用户行为序列视为上下文,来训练出用户行为向量。”--Mihajlo Grbovic, Airbnb
So What?
word2vec(或者其他词向量模型)相比过去的方法能提供更好的单词的向量表示,使得NLP发生重大的变革。就像词向量变革了NLP一样,item嵌入(item这里的信息的含义可以非常广泛,比如咨询、电影和商品等,下文中统称为item)也变革了推荐系统模型。
用户活动难以通过更直接的方式捕获的抽象特征。 例如,您如何编码Airbnb列表的“架构,风格和感觉”等品质?事实证明,word2vec方法在提取这些隐藏的信息方面是成功的,并且能够在这些抽象维度上对item进行比较,搜索和分类,为更智能、更好的推荐系统提供了可能。 在商业上,雅虎在将这种技术应用到他们的广告中时,点击率提高了9%,而AirBNB在其类似列表轮播上的点击率提升了21%,该产品推动了99%的预订以及搜索排名。
Four Production Examples
每个电子商务,社交媒体或内容共享网站都有这种用户活动,因此这种方法具有非常广泛的适用性。 下面介绍已经投入生产的这种技术的四个公开的案例:
- Spotify和Anghami的音乐推荐
- Airbnb的列表推荐
- Yahoo Mail中的产品推荐
- 将广告与Yahoo Search上的搜索查询相匹配。
Music Recommendations
Erik Bernhardsson在Spotify期间开发了近邻图书馆“Annoy”,他在一次访谈和一篇博客中提到Spotify尝试了这种技术。 然而,我读过这项技术的最丰富的讨论来自Anghami的Ramzi Karam,Anghami是中东地区流行的音乐流媒体服务公司。
在他的文章中,Ramzi解释了如何使用用户的收听歌曲队列来学习歌曲向量,就像使用文本中的一串单词来学习词向量一样。 假设用户倾向于按顺序收听类似的曲目。
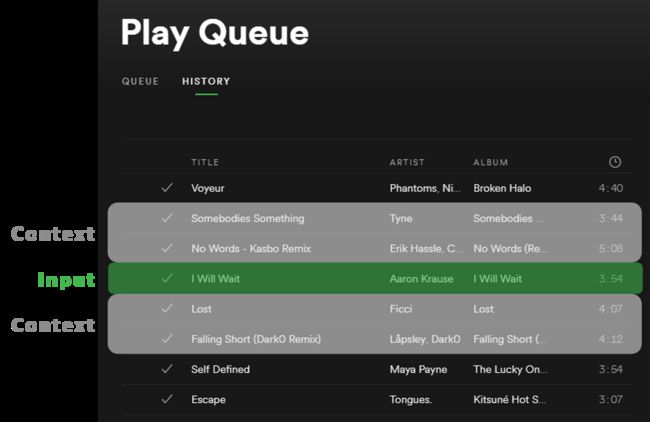
拉姆齐说,Anghami每月歌曲播放超过7亿首。 每首歌曲就像是文本数据集中的单个单词,因此Anghami的收听数据在规模上与谷歌用来训练他们发布的word2vec模型的数十亿字的Google新闻数据集相当。
Ramzi还分享了一些关于如何使用这些歌曲向量的技巧。 一是通过将用户喜欢收听的歌曲的向量取平均来为用户创建一种“音乐品味”向量。 然后,该“品味向量”可以成为用来相似性搜索,以找到与用户的“品味向量”相似的歌曲。 这篇文章包含一个很好的动画来说明它是如何工作的。
Listing Recommendations at Airbnb
关于这个主题的另一篇来自Airbnb的Mihajlo Grbovic。
想象一下,你正在寻找一个去巴黎度假时租用的公寓。 当您浏览房屋时,您可能会调查一些在设施和设计品味等方面符合您偏好的房源。这里,将用户点击数据视为用户的活动数据,特别是用户查看的序列。 通过对此数据应用word2vec方法,Airbnb能够学习其列表的向量表示。
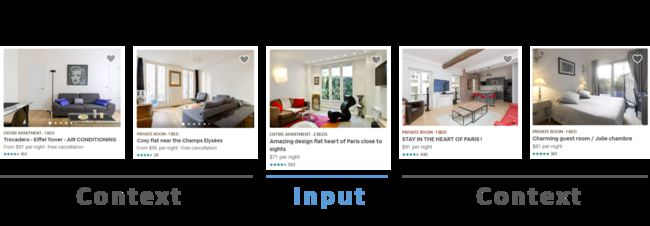
Airbnb对一般方法做了一些有趣的改进,以便将其应用到他们的网站。
word2vec训练算法的一个重要部分是,对于我们训练的每个单词,我们选择随机少数单词(不在该单词的上下文中)作为负样本。 Airbnb发现,为了学习可以区分巴黎境内房屋(而不仅仅是区分巴黎房屋和纽约房屋),重要的是从巴黎内部抽取负面样本。
Grbovic还解释了他们对冷启动问题的解决方案(如何学习没有用户活动数据的新房屋的向量) - 他们简单地将地理上最接近的房屋的向量平均到新商品以创建初始向量。
这些房屋向量用于识别在其网站上的“类似房屋”面板中显示的房屋,Grbovic说这是他们网站上预订的重要驱动因素。
这不是Grbovic第一次将word2vec模型应用于推荐 - 他在雅虎实验室也参与了接下来的两个例子
Product Recommendations in Yahoo Mail
雅虎发布了一份研究论文,详细说明了他们如何在用户的电子邮件收件箱中使用购买收据来形成购买活动,从而允许他们轮流学习可用于提出产品推荐的产品特征向量。 与此处介绍的其他应用程序一样,值得注意的是,这种方法已经进入了实际的生产系统。
由于在线购物者收到他们购买的电子邮件收据,因此邮件客户端处于一个独特的位置,可以在许多不同的电子商务网站上查看用户购买活动。 尽管如此,即使没有这种优势,雅虎的方法似乎也适用于在线零售商并且对其有潜在的价值。
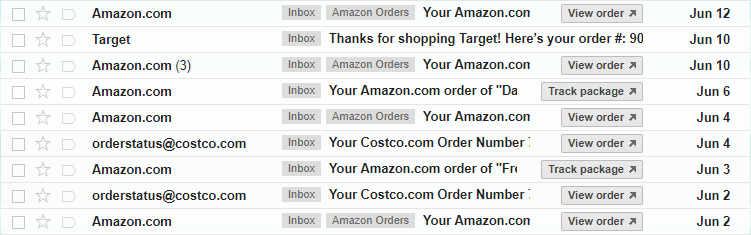
这里,用户活动是从电子邮件收据中提取的产品购买顺序。 word2vec方法能够基于购物者经常按顺序购买相关商品的假设来学习产品向量。例如,也许他们在同一时间购买了许多物品,因为它们在一起(如相机和镜头),或者因为它们都是他们正在进行的项目的一部分,或者因为他们正准备旅行。用户的购买顺序也可以反映购物者品味,购物者喜欢商品A也倾向于喜欢商品B并且有兴趣购买两者。
鉴于我们购买的产品并不总是相关的(这里的相关是可能是指功能或者是用途的相关),这看起来有点奇怪。但请记住,该模型受用户行为统计控制 - 如果两个产品相关,它们将由许多用户一起购买(因此在训练数据中同时出现,并且对模型具有更大影响),同时任何两个不相关的产品将更少地一起购买,并且对模型的影响很小。
雅虎通过一些值得注意的创新增强了word2vec方法。对我来说最有趣的是他们使用聚类来增加他们推荐的多样性。在为数据库中的所有产品学习到产品向量后,他们将这些向量聚类成组。在根据用户刚刚购买的产品为用户提供建议时,他们不建议使用同一群集中的产品。相反,他们确定用户在从当前群集购买后最常购买的其他群集,并且他们推荐来自其他群集的产品。
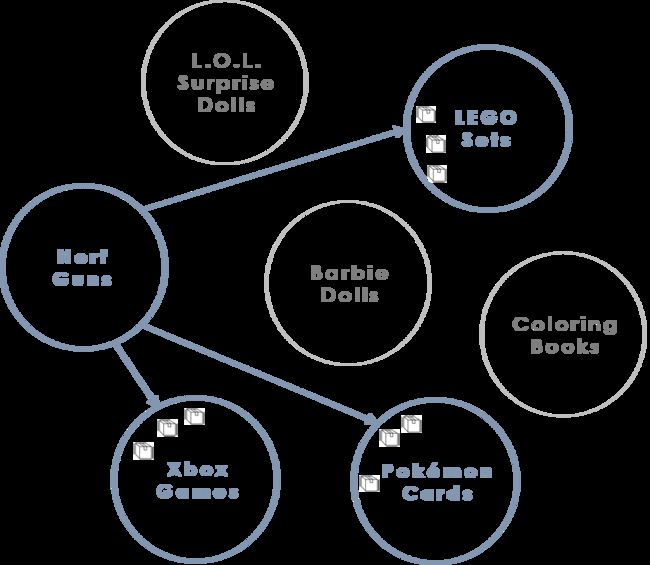
图:从Nerf集群购买产品后,客户最有可能从Xbox,Pokemon或LEGO集群购买产品。 (请注意,本文未提供示例群集内容,因此上述内容完全是伪造的)。
我想这种聚类技术有助于消除推荐相当于产品“同义词”的问题。 也就是说,想象一下,如果系统只推荐你刚购买的同一物品的不同版本 - “你刚买了Energizer AA电池? 查看这些Duracell AA电池!”,这种推荐不是很有帮助。

要在这些群集中选择要推荐的特定产品,在每个群集中,他们会找到与所购买产品最相似的“k”产品,并向用户推荐所有这些产品。 在他们的实验中,他们确定了每天向用户推荐的20种产品。 每次用户与Yahoo Mail客户端交互时,客户端都会以另一个广告的形式显示另一个产品推荐。
该文件还描述了一种称为“装袋”的技术,其中它们为出现在同一购买收据上的产品分配额外的权重。
Matching Ads to Search Queries
在此应用中,目标是为同一“嵌入空间”中搜索查询和广告学习矢量表示,以便可以将给定的搜索查询与可用的广告进行匹配,以便找到最相关的广告显示给用户。
考虑到这个问题带来的艰巨挑战(但他们解决了这些问题并将其付诸实践,这是一个特别引人入胜的应用)。如何同时学习查询和广告的向量?考虑到看似无限多的可能的查询,怎么学习搜索查询的向量?当新查询和新广告每天出现时,您如何应用此功能?
同时为查询和广告学习向量的解决方案非常简单。训练数据由用户“搜索会话”组成,其包括输入的搜索查询,点击的广告以及点击的搜索结果链接。这些用户动作的顺序被视为句子中的单词,并且基于它们的上下文 - 围绕它们倾向于发生的动作来学习每个用户的向量。如果用户在输入特定查询后经常点击特定广告,那么我们将学习广告和查询的类似向量。所有三种类型的操作(输入的搜索,点击的广告,点击的链接)都是模型的单个“词汇表”的一部分,因此模型并不真正区分这些类型。
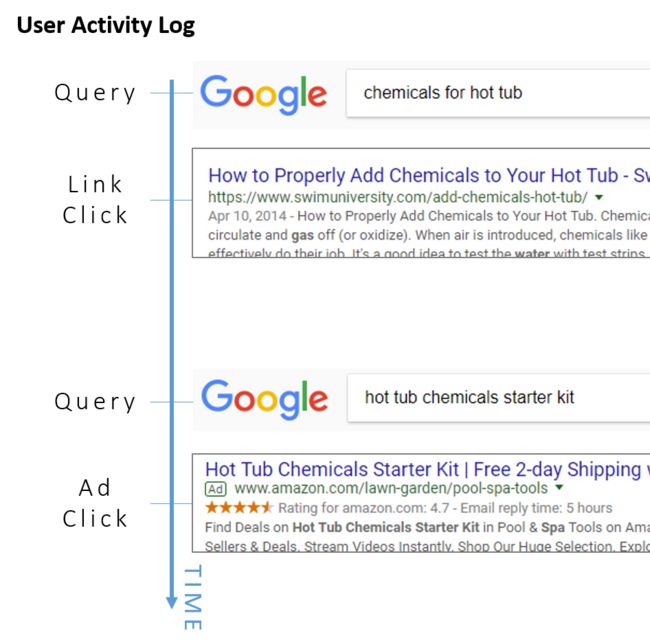
尽管此应用专注于匹配搜索查询和广告,但添加链接点击提供了额外的上下文以形成其他嵌入。 (虽然这不是他们研究论文的主题,但你不得不怀疑他们是否可以使用这些链接嵌入来帮助对搜索结果进行排名......)
这个问题的规模怎么样?当然,有太多个性化的查询,链接和广告可行吗?通过仅保留在训练数据中出现超过10次的词汇表中的条items来解决;他们暗示这会筛选出大部分个性化搜索。尽管如此,剩余的词汇量很大 - 他们的训练集包括“1.262亿个个性查询,4290万个个性广告和1.317亿个个性链接”,总计300.8万个条items。
他们指出,对于300维嵌入,2亿条items需要480GB的RAM,因此在单个服务器上训练此模型是不可能的。相反,他们详细介绍了使这种训练可行的分布式方法。
所以他们已经解决了规模问题,但是每天添加新的搜索查询和广告会不会导致严重的冷启动问题呢?我发现这里的方法细节难以理解,但总体策略似乎是将新材料中的单词与旧材料中的单词匹配,并利用这些现有嵌入为新内容创建初始嵌入。
这种方法投入生产,但显然并非所有广告都是以这种方式选择的 - 他们说他们的方法是“目前提供超过30%的广泛匹配”,其中“广泛匹配”是指尝试将查询与广告匹配关于查询的意图而不是简单的关键字匹配。
Similarity Search
这种基于用户活动数据学习内容向量的方法对于nearist来说是令人兴奋的发展,因为使用这些向量的最常见操作是建立相似性搜索以进行内容推荐。
考虑到大量的矢量化内容和需要进行推荐的大量用户,这种相似性搜索成为一个具有挑战性的工程问题。像Spotify和Facebook这样的公司已经投入了大量精力来开发近似技术,以使这种搜索在大规模上可行,但是准确性成本很高,而且工程工作成本很高。当产品质量建议直接影响收入时,准确性至关重要!
在Nearist,我们相信机器学习团队的努力更好地用于提高矢量表示的质量,而不是大规模地解决相似性搜索,我们的目标是通过最少的工程提供尽可能多的搜索功能。努力。在Nearist.ai了解更多信息。