CART算法解读
目录
算法解读
实例对比
过程总结
python实战
数据处理
画图
预测验证
参数解释
数据挖掘十大算法之一
1、算法解读
CART分类树用的是另外一个指标 – 基尼指数. 假设一共有K个类,样本属于第k类的概率是pk,则概率分布的基尼指数定义为:

基尼系数类似于熵,选择最佳划分的度量通常是根据划分后子女结点不纯性的程度。不纯的程度越低,类分布就越倾斜。例如,类分布为(0, 1)的结点具有零不纯性,而均衡分布(0.5,0.5)的结点具有最高的不纯性。
对于二分类问题,如果样本点属于第一类的概率为p,则概率分布的基尼系数为
Gini(p)=2p(1-p)
对于给定的样本集合D,其基尼系数为:

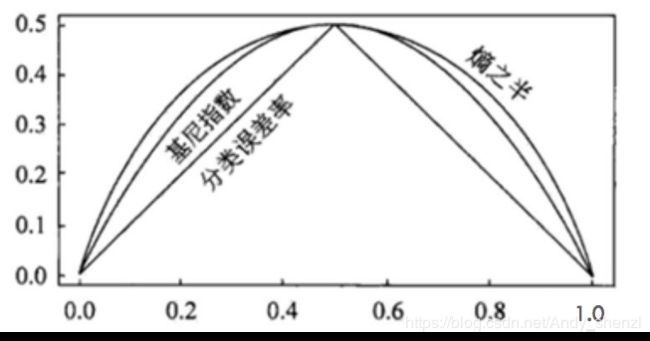
CART分类时,使用基尼指数(Gini)来选择最好的数据分割的特征,gini描述的是纯度,与信息熵的含义相似。CART中每一次迭代都会降低GINI系数。下图显示信息熵增益的一半,Gini指数,分类误差率三种评价指标非常接近。
实例对比
可以与C4.5进行对比

Gini(是否打球)=2*(5/14)*(9/14)=0.459
对离散值如{x,y,x},则在该属性上的划分有三种情况({{x,y},{z}},{{x,z},y},{{y,z},x}),空集和全集的划分除外
对于Outlook:有三个属性,进行二分类取值时,有三种分类可能
1、{sunny}|{overcast,rainy}
2、{overcast}|{sunny, rainy}
3、{rainy}|{overcast, sunny}
1、{sunny}|{overcast, rainy}
Δ{Outlook}=0.459–5/14*(2*(2/5)*(3/5))-9/14*(2*(2/9)*(7/9)) = 0.065
2、{overcast}|{sunny, rainy}
Δ{Outlook}=0.459–4/14*(2*(4/4)*(0/4))-10/14*(2*(5/10)*(5/10)) = 0.102
3、{rainy}|{overcast, sunny}
Δ{Outlook}=0.459–5/14*(2*(3/5)*(2/5))-9/14*(2*(3/9)*(6/9))=0.002
对比计算结果,根据Outlook属性来划分根节点时取Gini系数增益最大的分组作为划分结果,也就是:{overcast}|{sunny, rainy}
过程总结
1.设结点的训练数据集为D,计算现有特征对该数据集的Gini系数。此时,对每一个特征A,对其可能取的每个值a,根据样本点对A=a的测试为“是”或“否”将D分割成D1和D2两部分,计算A=a时的Gini系数。
2.在所有可能的特征A以及它们所有可能的切分点a中,选择Gini系数最小的特征及其对应的切分点作为最优特征与最优切分点。依最优特征与最优切分点,从现结点生成两个子结点,将训练数据集依特征分配到两个子结点中去。
3.对两个子结点递归地调用步骤l~2,直至满足停止条件。
4.生成CART决策树。
python实战
import pandas as pd
df = pd.read_csv("tree.csv")
df.head()
数据还是上面的案例

数据处理
df.loc[df["outlook"] == "sunny", "outlook"] = 0
df.loc[df["outlook"] == "overcast", "outlook"] = 1
df.loc[df["outlook"] == "rainy", "outlook"] = 2
df.loc[df["temperature"] == "hot", "temperature"] = 0
df.loc[df["temperature"] == "mild", "temperature"] = 1
df.loc[df["temperature"] == "cool", "temperature"] = 2
df.loc[df["humidity"] == "high", "humidity"] = 0
df.loc[df["humidity"] == "normal", "humidity"] = 1
df.loc[df["windy"] =="N", "windy"] = 0
df.loc[df["windy"] =="Y", "windy"] = 1
y=df["play"]
col=df.columns.tolist()
x_col=col[0:4]
x=df[x_col]
from sklearn import tree
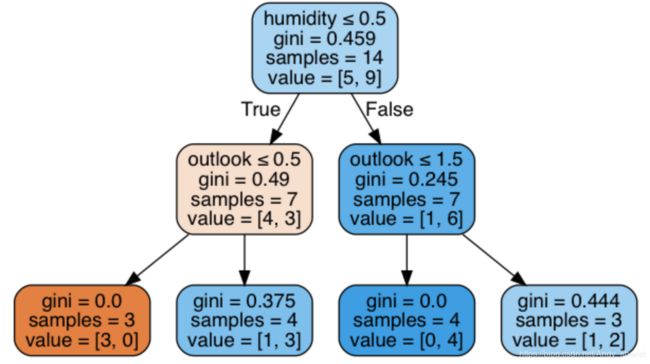
clf = tree.DecisionTreeClassifier(max_depth = 2,criterion='gini').fit(x,y)
clf: DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=2, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter='best')
画图
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=col[0:4],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
预测验证
from sklearn import metrics
expected = y
predicted = clf.predict(x)
# summarize the fit of the model
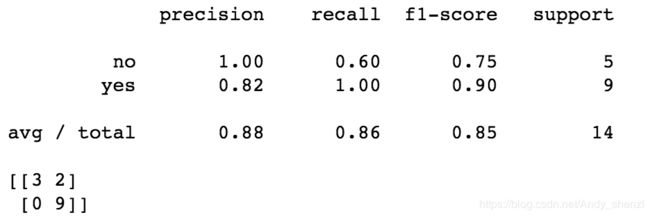
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))
准确率、召回率以及混淆矩阵
参数解释
函数 tree.DecisionTreeClassifier()中的具体参数,在sklearn的官网中有给出,如下:
class sklearn.tree.DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2,min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None,class_weight=None, presort=False)
criterion:string类型,可选(默认为"gini")
衡量分类的质量。支持的标准有"gini"代表的是Gini impurity(不纯度)与"entropy"代表的是information gain(信息增益)。
splitter:string类型,可选(默认为"best")
一种用来在节点中选择分类的策略。支持的策略有"best",选择最好的分类,"random"选择最好的随机分类。
max_features:int,float,string or None 可选(默认为None)
在进行分类时需要考虑的特征数。
1.如果是int,在每次分类是都要考虑max_features个特征。
2.如果是float,那么max_features是一个百分率并且分类时需要考虑的特征数是int(max_features*n_features,其中n_features是训练完成时发特征数)。
3.如果是auto,max_features=sqrt(n_features)
4.如果是sqrt,max_features=sqrt(n_features)
5.如果是log2,max_features=log2(n_features)
6.如果是None,max_features=n_features
注意:至少找到一个样本点有效的被分类时,搜索分类才会停止。
max_depth:int or None,可选(默认为"None")
表示树的最大深度。如果是"None",则节点会一直扩展直到所有的叶子都是纯的或者所有的叶子节点都包含少于min_samples_split个样本点。忽视max_leaf_nodes是不是为None。
min_samples_split:int,float,可选(默认为2)
区分一个内部节点需要的最少的样本数。
1.如果是int,将其最为最小的样本数。
2.如果是float,min_samples_split是一个百分率并且ceil(min_samples_split*n_samples)是每个分类需要的样本数。ceil是取大于或等于指定表达式的最小整数。
min_samples_leaf:int,float,可选(默认为1)
一个叶节点所需要的最小样本数:
1.如果是int,则其为最小样本数
2.如果是float,则它是一个百分率并且ceil(min_samples_leaf*n_samples)是每个节点所需的样本数。
min_weight_fraction_leaf:float,可选(默认为0)
一个叶节点的输入样本所需要的最小的加权分数。
max_leaf_nodes:int,None 可选(默认为None)
在最优方法中使用max_leaf_nodes构建一个树。最好的节点是在杂质相对减少。如果是None则对叶节点的数目没有限制。如果不是None则不考虑max_depth.
class_weight:dict,list of dicts,"Banlanced" or None,可选(默认为None)
表示在表{class_label:weight}中的类的关联权值。如果没有指定,所有类的权值都为1。对于多输出问题,一列字典的顺序可以与一列y的次序相同。
"balanced"模型使用y的值去自动适应权值,并且是以输入数据中类的频率的反比例。如:n_samples/(n_classes*np.bincount(y))。
对于多输出,每列y的权值都会想乘。
如果sample_weight已经指定了,这些权值将于samples以合适的方法相乘。
random_state:int,RandomState instance or None
如果是int,random_state 是随机数字发生器的种子;如果是RandomState,random_state是随机数字发生器,如果是None,随机数字发生器是np.random使用的RandomState instance.
persort:bool,可选(默认为False)
是否预分类数据以加速训练时最好分类的查找。在有大数据集的决策树中,如果设为true可能会减慢训练的过程。当使用一个小数据集或者一个深度受限的决策树中,可以减速训练的过程。
这里面大部分参数选择默认即可。