Python实现SVM使用案例
最近一直在看文本挖掘这块儿,看了许多机器学习相关的资料,在这里做个笔记分享给大家,有供自己日后学习浏览。码字不易,喜欢请点赞!!!

这篇推文主要介绍Python实现SVM的案例,后期会更新加强版。
这里主要讲的是使用Python的Sklearn包实现SVM样本分类,而不包括SVM的理论推导,我在看SVM的理论的时候看了很多网上的博客,有很多都写的不错,这里推荐,July写的支持向量机通俗导论(理解SVM的三层境界),而且作者将其制作成了pdf版本,可以下载下来观看。这篇博客是July12年开始写的,并且一直更新完善,所以到现在真的是通俗易懂。这里附上网址:https://blog.csdn.net/v_july_v/article/details/7624837
理论部分这篇博客真的够!!!
Sklearn是Python专门用于机器学习的包,安装方法网上有很多,这里也不介绍了,有问题可以随时进交流群询问。

这里就开始一步步讲解,在实践过程中的具体步骤。
一般来说机器学习的实践流程包括:导入数据->数据标准化->模型选择->模型的训练测试->保存模型
首先,导入数据这块,你如果使用自己的数据集的话,可以用numpy或者pandas导入。本文这里直接使用Sklearn自带的经典的iris鸢尾花数据集。
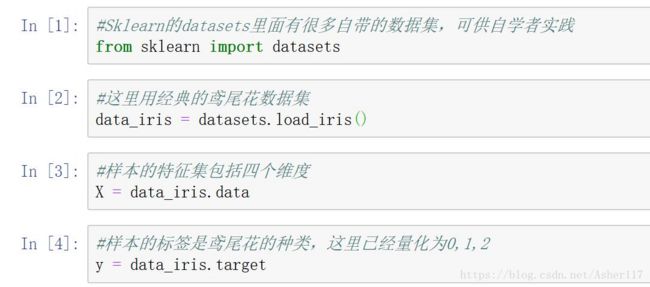
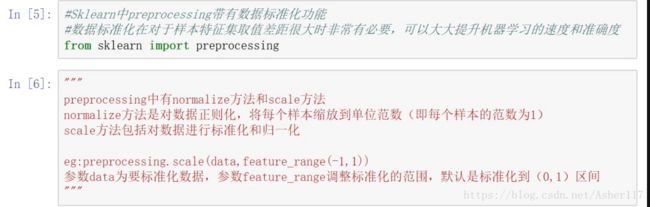
导入数据之后,对数据进行标准化处理(由于这里采用的是自带的鸢尾花数据集,已经不需要标准化就能很好的预测了,使用自己的样本时,这步非常重要)。
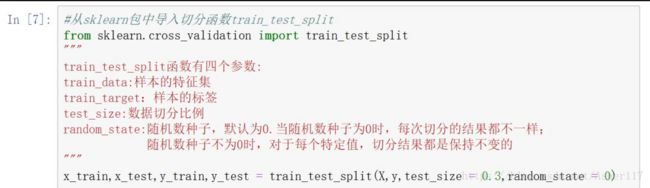
在对数据标准化处理之后,这里对用分类的数据进行切分,分为训练集和样本集。
模型选择:Sklearn中已经实现了所有基本的机器学习方法,包括:

本文选用的模型为支持向量机(SVM的参数很多,主要是设置惩罚参数C,后期的加强版会介绍,这里使用默认参数C=1):

使用模型进行训练和测试,然后输出测试后的精度:

可以看到只有第二行第一个有错误,其他都是准确的。
保存模型:在训练出满意的模型之后,可已经模型保存,以便下次使用,Python中保存模型的方法有两种,第一种是pickle包,第二种是Sklearn中的joblib方法,官方文档推荐的是使用joblib方法,因为该方法使用了多进程,速度更快,这里也就展示joblib方法。

可以看到简单的两个语句就实现了模型的保存与再调用。
简简单单12行代码你就完成了机器学习的实践,是不是很sixsixsxi!!!
ps:对于Sklearn的基本使用方法就这些了,后期会分享进阶版,包括但不限于模型的函数主要参数的设置以及交叉验证。