三元表达式&列表解析&生成器表达式
-
- 三元表达式
- 列表解析
- 生成器表达式
三元表达式
在作简单的判断时,三元表达式能简化代码:
def max(x, y):
if x > y:
return x
else:
return y
# 这个函数可以简化为如下形式:
def max_new(x,y):
return x if x > y else y格式:x if 条件 else y 如果条件成立,返回x, 否则返回y
列表解析
列表解析也是三元表达式,方便我们从一个序列生成另一个序列。
基本格式如下:
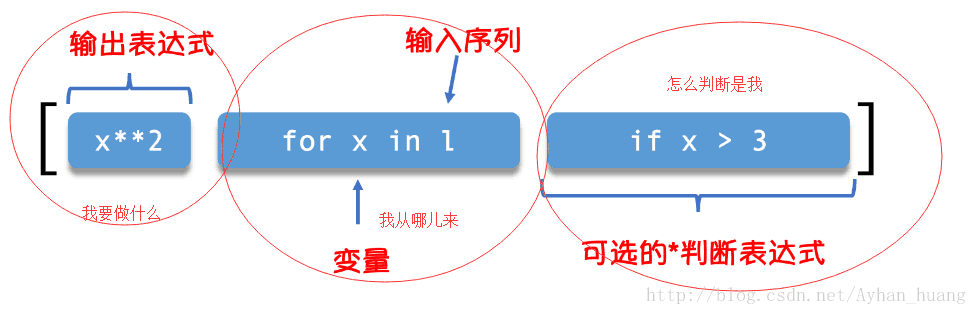
举几个栗子:
s = 'hello'
l =[x.upper() for x in s]
print(l) # 打印结果如下:
['H', 'E', 'L', 'L', 'O']
list = [1,3,59,45,60]
l_new = [x for x in list if x > 50]
print(l_new) # 打印结果如下:
[59, 60]在具体应用时,应该先写出上图中的基本结构,有时输出表达式可以写的很复杂,输入序列也可以嵌套,if判断中也可以嵌套 for i in 比如下面这个栗子:
# 文件a.txt内容
# apple 10 3
# tesla 100000 1
# mac 3000 2
# lenovo 30000 3
# chicken 10 3
# 要求使用列表解析,从文件a.txt中取出每一行,做成下述格式
# [{‘name’:'apple','price':10,'count':3},{...},{...},...]
file = r'D:\Pythonworks\homework\170616函数列表解析\a.txt'
with open(file,encoding='utf-8')as f:
print([{'name': line.strip().split(' ')[0],\
'price':line.strip().split(' ')[1], \
'count': line.strip().split(' ')[2]}for line in f
])
# 分析题目可以发现,输出表达式是字典元素,输入序列是文件的一行,那先把基本的形式写出来:
# [{'name':X, 'price': X, 'count': X} for line in f]
# 然后再从line中分解出X
# 方法二:
with open(file,encoding='utf-8')as f:
print([{'name':i[0],'price':i[1],'count':i[2]}for i in [line.strip().split(' ') for line in f]])
# 1 strip()是去掉字符串前后的空格和换行符。字符串内的空格也是字符!
# 2 with open() as f: 语句的自动关闭文件功能,是指出了with的缩进,就关闭。
# 3 上面这个嵌套了两个列表解析。最后一个列表,是最终列表的输入序列。生成器表达式
同列表解析一样,只需要把 [] 换成 () 就可以得到一个生成器。