【paper】ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
本文发表于ECCV 2018 Workshop。主要针对SRGAN做的一个改进,在网络结构、对抗损失以及感知损失上分别进行了改动,在效果上有一定的提升。
0. 概述
基于生成对抗网络的图像超分辨率模型SRGAN能够生成更多的纹理细节。然而,它恢复出来的纹理往往不够自然,也常伴随着一些噪声。
为了进一步增强图像超分辨率的视觉效果,本文深入研究并改进了SRGAN的三个关键部分——网络结构、对抗损失函数和感知损失函数,提出了一个增强的ESRGAN模型。具体地,本文引入了一个新网络结构单元RRDB (Residual-in-Resudal Dense Block);借鉴了相对生成对抗网络(relativistic GAN)让判别器预测相对的真实度而不是绝对的值;还使用了激活前的具有更强监督信息的特征表达来约束感知损失函数。
得益于以上的改进,本文提出的ESRGAN模型能够恢复更加真实自然的纹理,取得比之前的SRGAN模型更好的视觉效果。ESRGAN模型同时在ECCV2018的PIRM-SR比赛中获得了最好的感知评分,取得了第一名。
接下来就按照上述思路,从问题的背景,做出的改进细节,以及效果进行总结,会结合代码(文章源码pytorch版本)进行具体理解。
1. Motivation
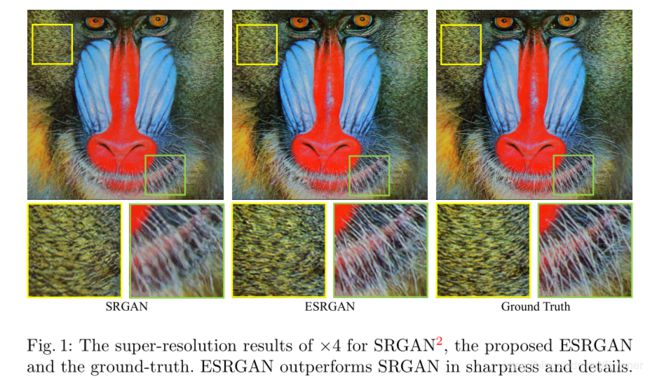
超分辨率问题是指从单个低分辨率图像中恢复高分辨率图像。在早期超分辨率领域,SRCNN的提出是一项创举,随后各种网络架构设计和训练策略不断提出来提高SR的性能,尤其是峰值信噪比值(Peak Signal Noise Ratio, PSNR),但这些面向PSNR的方法往往会输出过度平滑的结果,而没有足够的高频细节,因为PSNR指标从根本上不同于人类观察者的主观评价。
几种感知驱动方法已经被提出来改善SR结果的视觉质量。例如,提出感知损失来优化特征空间中的超分辨率模型而不是像素空间。生成的对抗性网络被引入SR,以鼓励网络支持看起来更像自然图像的解决方案。进一步整合语义图像先验以改善恢复的纹理细节。
其中,超分辨率生成对抗网络(SRGAN)是一项开创性的工作,能够在单一图像超分辨率中生成逼真的纹理。其基本模型使用残差块构建,并使用GAN框架中的感知损耗进行优化。通过所有这些技术,SRGAN显着提高了重建的整体视觉质量,而不是面向PSNR的方法。但通过上图可以看到,放大的图像中出现了比较明显的伪影现象。因而,提出了我们的ESRGAN。ESRGAN在锐度和细节方面都优于SRGAN。
2、Proposed Methods
2.1 网络结构
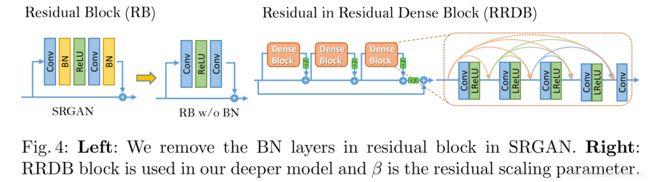
在SRGAN中,其使用的是残差块,为了提高图像质量,我们在网络结构上做了两点改动:(1)删除所有的BN层。(2)将原来的残差模块改成了 Residual-in-Residual Dense Block (RRDB)。
接下来,进行一下说明:
BN层:BN层在训练时,对批数据中使用均值和方差对特征进行规范化,在测试时使用所以训练数据的均值和方差。当训练数据和测试数据相差较大时,BN层会引入伪影,以及限制了泛化能力。尤其当网络加深时,伪影会更加严重。而且BN层会导致平滑,不利于产生局部信息,因而在GAN中很少使用。去掉BN层可以提高模型的泛化能力,减少计算复杂度和内存占用。
RRDB:RRDB采用比SRGAN原始残差块更深层和更复杂的结构。残差学习用于不同的层,另外在主要路径中使用了密集块,其中网络容量因为密集连接变得更高。
RRDB模块大大加深了网络,因而作者也使用了一些技巧来训练深层网络:1.对残差信息进行scaling(β),即将残差信息乘以一个0到1之间的数,用于防止不稳定;2.更小的初始化,作者发现当初始化参数的方差变小时,残差结构更容易进行训练。
下面是generator 源码部分:
基础conv_block,无BN:
def conv_block(in_nc, out_nc, kernel_size, stride=1, dilation=1, groups=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='CNA'):
'''
Conv layer with padding, normalization, activation
mode: CNA --> Conv -> Norm -> Act
NAC --> Norm -> Act --> Conv (Identity Mappings in Deep Residual Networks, ECCV16)
'''
assert mode in ['CNA', 'NAC', 'CNAC'], 'Wong conv mode [{:s}]'.format(mode)
padding = get_valid_padding(kernel_size, dilation)
p = pad(pad_type, padding) if pad_type and pad_type != 'zero' else None
padding = padding if pad_type == 'zero' else 0
c = nn.Conv2d(in_nc, out_nc, kernel_size=kernel_size, stride=stride, padding=padding, \
dilation=dilation, bias=bias, groups=groups)
a = act(act_type) if act_type else None
if 'CNA' in mode:
n = norm(norm_type, out_nc) if norm_type else None
return sequential(p, c, n, a)
elif mode == 'NAC':
if norm_type is None and act_type is not None:
a = act(act_type, inplace=False)
# Important!
# input----ReLU(inplace)----Conv--+----output
# |________________________|
# inplace ReLU will modify the input, therefore wrong output
n = norm(norm_type, in_nc) if norm_type else None
return sequential(n, a, p, c)
residual dense block:
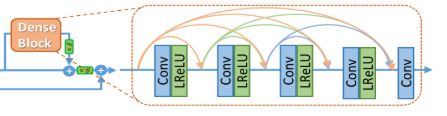
class ResidualDenseBlock_5C(nn.Module):
'''
Residual Dense Block
style: 5 convs
The core module of paper: (Residual Dense Network for Image Super-Resolution, CVPR 18)
'''
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CNA'):
super(ResidualDenseBlock_5C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 = conv_block(nc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv2 = conv_block(nc+gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv3 = conv_block(nc+2*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
self.conv4 = conv_block(nc+3*gc, gc, kernel_size, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=act_type, mode=mode)
if mode == 'CNA':
last_act = None
else:
last_act = act_type
self.conv5 = conv_block(nc+4*gc, nc, 3, stride, bias=bias, pad_type=pad_type, \
norm_type=norm_type, act_type=last_act, mode=mode)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(torch.cat((x, x1), 1))
x3 = self.conv3(torch.cat((x, x1, x2), 1))
x4 = self.conv4(torch.cat((x, x1, x2, x3), 1))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
return x5.mul(0.2) + x
RRDB模块:
class RRDB(nn.Module):
'''
Residual in Residual Dense Block
(ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks)
'''
def __init__(self, nc, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=None, act_type='leakyrelu', mode='CNA'):
super(RRDB, self).__init__()
self.RDB1 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
self.RDB2 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
self.RDB3 = ResidualDenseBlock_5C(nc, kernel_size, gc, stride, bias, pad_type, \
norm_type, act_type, mode)
def forward(self, x):
out = self.RDB1(x)
out = self.RDB2(out)
out = self.RDB3(out)
return out.mul(0.2) + x
整体 Generator 网络结构(可以结合图):

class RRDBNet(nn.Module):
def __init__(self, in_nc, out_nc, nf, nb, gc=32, upscale=4, norm_type=None, \
act_type='leakyrelu', mode='CNA', upsample_mode='upconv'):
super(RRDBNet, self).__init__()
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
fea_conv = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type=None)
rb_blocks = [B.RRDB(nf, kernel_size=3, gc=32, stride=1, bias=True, pad_type='zero', \
norm_type=norm_type, act_type=act_type, mode='CNA') for _ in range(nb)]
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)
if upsample_mode == 'upconv':
upsample_block = B.upconv_blcok
elif upsample_mode == 'pixelshuffle':
upsample_block = B.pixelshuffle_block
else:
raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
if upscale == 3:
upsampler = upsample_block(nf, nf, 3, act_type=act_type)
else:
upsampler = [upsample_block(nf, nf, act_type=act_type) for _ in range(n_upscale)]
HR_conv0 = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=act_type)
HR_conv1 = B.conv_block(nf, out_nc, kernel_size=3, norm_type=None, act_type=None)
self.model = B.sequential(fea_conv, B.ShortcutBlock(B.sequential(*rb_blocks, LR_conv)),\
*upsampler, HR_conv0, HR_conv1)
def forward(self, x):
x = self.model(x)
return x
2.2 Relativistic Discriminator
判别器 D 使用的网络是 VGG 网络,SRGAN中的判别器D用于估计输入到判别器中的图像是真实且自然图像的概率,而Relativistic判别器则尝试估计真实图像相对来说比fake图像更逼真的概率。

网络结构上,D还是VGG网络。有几种不同的选择128 or 96.
class Discriminator_VGG_128_SN(nn.Module):
def __init__(self):
super(Discriminator_VGG_128_SN, self).__init__()
# features
# hxw, c
# 128, 64
self.lrelu = nn.LeakyReLU(0.2, True)
self.conv0 = SN.spectral_norm(nn.Conv2d(3, 64, 3, 1, 1))
self.conv1 = SN.spectral_norm(nn.Conv2d(64, 64, 4, 2, 1))
# 64, 64
self.conv2 = SN.spectral_norm(nn.Conv2d(64, 128, 3, 1, 1))
self.conv3 = SN.spectral_norm(nn.Conv2d(128, 128, 4, 2, 1))
# 32, 128
self.conv4 = SN.spectral_norm(nn.Conv2d(128, 256, 3, 1, 1))
self.conv5 = SN.spectral_norm(nn.Conv2d(256, 256, 4, 2, 1))
# 16, 256
self.conv6 = SN.spectral_norm(nn.Conv2d(256, 512, 3, 1, 1))
self.conv7 = SN.spectral_norm(nn.Conv2d(512, 512, 4, 2, 1))
# 8, 512
self.conv8 = SN.spectral_norm(nn.Conv2d(512, 512, 3, 1, 1))
self.conv9 = SN.spectral_norm(nn.Conv2d(512, 512, 4, 2, 1))
# 4, 512
# classifier
self.linear0 = SN.spectral_norm(nn.Linear(512 * 4 * 4, 100))
self.linear1 = SN.spectral_norm(nn.Linear(100, 1))
def forward(self, x):
x = self.lrelu(self.conv0(x))
x = self.lrelu(self.conv1(x))
x = self.lrelu(self.conv2(x))
x = self.lrelu(self.conv3(x))
x = self.lrelu(self.conv4(x))
x = self.lrelu(self.conv5(x))
x = self.lrelu(self.conv6(x))
x = self.lrelu(self.conv7(x))
x = self.lrelu(self.conv8(x))
x = self.lrelu(self.conv9(x))
x = x.view(x.size(0), -1)
x = self.lrelu(self.linear0(x))
x = self.linear1(x)
return x
作者把标准的判别器换成Relativistic average Discriminator(RaD),所以判别器的损失函数定义为:
![]()
self.optimizer_D.zero_grad()
l_d_total = 0
pred_d_real = self.netD(self.var_ref)
pred_d_fake = self.netD(self.fake_H.detach()) # detach to avoid BP to G
l_d_real = self.cri_gan(pred_d_real - torch.mean(pred_d_fake), True)
l_d_fake = self.cri_gan(pred_d_fake - torch.mean(pred_d_real), False)
l_d_total = (l_d_real + l_d_fake) / 2
对应的生成器的对抗损失函数为:
![]()
pred_g_fake = self.netD(self.fake_H)
pred_d_real = self.netD(self.var_ref).detach()
l_g_gan = self.l_gan_w * (self.cri_gan(pred_d_real - torch.mean(pred_g_fake), False)
+ self.cri_gan(pred_g_fake - torch.mean(pred_d_real), True)) / 2
l_g_total += l_g_gan
求均值的操作是通过对mini-batch中的所有数据求平均得到的,xf是原始低分辨图像经过生成器以后的图像。对抗损失包含了xr和xf,所以这个生成器受益于对抗训练中的生成数据和实际数据的梯度,这种调整会使得网络学习到更尖锐的边缘和更细节的纹理。
2.3 感知损失
文章使用了更有效的感知损失,使用激活前的特征而不是激活后的特征。使用一个VGG16网络。感知域的损失当前是定义在一个预训练的深度网络的激活层,这一层中两个激活了的特征的距离会被最小化。在这里,文章使用的特征是激活前的特征,这样会克服两个缺点。第一,激活后的特征是非常稀疏的,特别是在很深的网络中。这种稀疏的激活提供的监督效果是很弱的,会造成性能低下。
例如下图。激活图像'狒狒'之前和之后的代表性特征图。 随着网络的深入,激活后的大多数功能变为非活动状态,而激活前的功能包含更多信息。
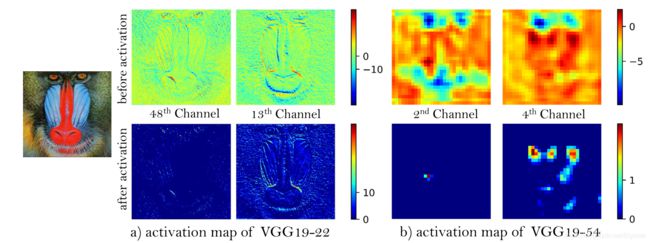
第二,使用激活后的特征会导致重建图像与GT的亮度不一致。
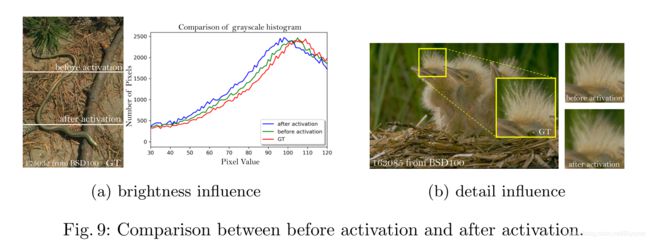
这两个问题,都可以在上图中体现。我们使用一个VGG(已经预训练)来提取特征。该网络不需要训练,仅作为特征提取器,并且按照前述,去掉最后一层激活层。
class MINCNet(nn.Module):
def __init__(self):
super(MINCNet, self).__init__()
self.ReLU = nn.ReLU(True)
self.conv11 = nn.Conv2d(3, 64, 3, 1, 1)
self.conv12 = nn.Conv2d(64, 64, 3, 1, 1)
self.maxpool1 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv21 = nn.Conv2d(64, 128, 3, 1, 1)
self.conv22 = nn.Conv2d(128, 128, 3, 1, 1)
self.maxpool2 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv31 = nn.Conv2d(128, 256, 3, 1, 1)
self.conv32 = nn.Conv2d(256, 256, 3, 1, 1)
self.conv33 = nn.Conv2d(256, 256, 3, 1, 1)
self.maxpool3 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv41 = nn.Conv2d(256, 512, 3, 1, 1)
self.conv42 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv43 = nn.Conv2d(512, 512, 3, 1, 1)
self.maxpool4 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv51 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv52 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv53 = nn.Conv2d(512, 512, 3, 1, 1)
def forward(self, x):
out = self.ReLU(self.conv11(x))
out = self.ReLU(self.conv12(out))
out = self.maxpool1(out)
out = self.ReLU(self.conv21(out))
out = self.ReLU(self.conv22(out))
out = self.maxpool2(out)
out = self.ReLU(self.conv31(out))
out = self.ReLU(self.conv32(out))
out = self.ReLU(self.conv33(out))
out = self.maxpool3(out)
out = self.ReLU(self.conv41(out))
out = self.ReLU(self.conv42(out))
out = self.ReLU(self.conv43(out))
out = self.maxpool4(out)
out = self.ReLU(self.conv51(out))
out = self.ReLU(self.conv52(out))
out = self.conv53(out)
return out
# Assume input range is [0, 1]
class MINCFeatureExtractor(nn.Module):
def __init__(self, feature_layer=34, use_bn=False, use_input_norm=True, \
device=torch.device('cpu')):
super(MINCFeatureExtractor, self).__init__()
self.features = MINCNet()
self.features.load_state_dict(
torch.load('../experiments/pretrained_models/VGG16minc_53.pth'), strict=True)
self.features.eval()
# No need to BP to variable
for k, v in self.features.named_parameters():
v.requires_grad = False
def forward(self, x):
output = self.features(x)
return output
那我们的做法,将生成器完整的损失表示为:
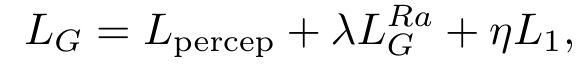
其中![]() 是评估恢复图像
是评估恢复图像![]() 和真实图像
和真实图像![]() 之间的1-范数距离内容损失,
之间的1-范数距离内容损失,![]() 、
、![]() 是平衡不同损失项的系数。
是平衡不同损失项的系数。
# G feature loss
if train_opt['feature_weight'] > 0:
l_fea_type = train_opt['feature_criterion']
if l_fea_type == 'l1':
self.cri_fea = nn.L1Loss().to(self.device)
elif l_fea_type == 'l2':
self.cri_fea = nn.MSELoss().to(self.device)
else:
raise NotImplementedError('Loss type [{:s}] not recognized.'.format(l_fea_type))
self.l_fea_w = train_opt['feature_weight']
else:
logger.info('Remove feature loss.')
self.cri_fea = None
if self.cri_fea: # load VGG perceptual loss
self.netF = networks.define_F(opt, use_bn=False).to(self.device)
2.4 Network Interpolation
为了平衡感知质量和 PSNR 等评价值,作者提出了一个灵活且有效的方法——网络插值。具体而言,作者首先基于 PSNR 方法训练的得到的网络 G_PSNR,然后再用基于 GAN 的网络 G_GAN 进行 finetune。然后,对这两个网络相应的网络参数进行插值得到一个插值后的网络 G_INTERP:
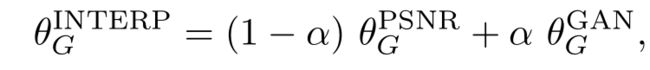
3、Results
结果图如下,每个部分的作用比较好的展示:
