区块链在中国(2):PBFT算法
上一张我们从分布式系统的角度简单叙述了一下 IBM HyperLedger fabric 的一些基本概念、架构和协议信息。其中最为核心的部分就是共识算法(consensus plugin),fabric推荐并实现的就是PBFT这一经典算法。
BFT算法
Client会发送一系列请求给各个replicas节点来执行相应的操作,BFT算法保证所有正常的replicas节点执行相同序列的操作。因为所有的replicas节点都是deterministic,而且初始状态都相同,根据状态机原理(state machine replication),这些replicas会产生相同的结果状态。当Client收到f+1个replicas节点返回的结果时,如果这些结果都一样,因为BFT算法确保了最多有f个replicas出现问题,所以至少有一个replicas是正确的,那么Client收到的这些结果都是正确的。
但是state machine replication的难点在于确保正常replicas节点都以相同的序列执行同样的一些请求,尤其是如何来面对拜占庭故障。PBFT会融合primary-backup [Alsberg and Day 1976] 和 quorum replication
[Gifford 1979]两种技术来序列化请求。
primary-backup
这个机制下有一个叫view的概念,在一个view里,一个replica会是主节点(primary),其余的replicas都叫备份节点(backups)。主节点负责将来自Client的请求给排好序,然后按序发送给备份节点们。但是主节点可能会是faulty的:它可能会给不同的请求编上相同的序号,或者不去分配序号,或者让相邻的序号不连续。备份节点应当有职责来主动检查这些序号的合法性,并能通过timeout机制检测到主节点是否已经宕掉。当出现这些异常情况时,这些备份节点就会触发view change协议来选举出新的主节点。
The algorithm ensures that request sequence numbers are dense, that is, no sequence numbers are skipped but when there are view changes some sequence numbers may be assigned to null requests whose execution is a no-op.
quorums
quorums有两个重要的属性:
- Intersection: 任意两个quorums至少有一个共同的并且正确的replica
- Availability: 总是存在一个没有faulty replicas的quorum
如果一个replica把信息写给一个quorum,并让该quorum来存储信息,在收到每一个quorum中的成员的确认反馈后,那么我们可以认为该replica的信息已经被可靠的保存在了这个分布式系统中。这是强的约束,当然还有一个weak certificates:就是至少f+1个节点来共同存取信息,这样至少有一个正确的replica存到了这份信息。
我们先来约定一些符合:
R是所有replicas的集合,每一个replica用一个整数来表示,依次为
{ 0, …, |R - 1 }
简单起见,我们定义
|R = 3f + 1
f 是最大可容忍的faulty节点
另外我们将一个view中的primary节点定义为replica p,
p = v mod |R
v 是view的编号,从0开始一直连续下去,这样可以理解为从replica 0 到 replica |R -1 依次当primary节点,当每一次view change发生时。
我们定义一个quorum为至少包含2f+1个replicas的集合。
The Client
一个Client会将请求
⟨REQUEST,o,t,c⟩ 其中o表示具体的操作,t表示timestamp,给每一个请求加上时间戳,这样后来的请求会有高于前面的时间戳
replicas会接收请求,如果他们验证了条请求,就会将它写入到自己的log中。在共识算法保证下每个replica完成对该请求的执行后直接将回复返回给client:
⟨REPLY,v,t,c,i,r⟩ v是当前的view序号,t就是对应请求的时间戳,i是replica节点的编号,r是执行结果
我们上面提到过weak certificate,在这里,client也会等待这个weak certificate:即有f+1个replicas回复,并且它们的回复拥有相同的 t 和 r,由于至多有f个faulty replicas,所以确保了回复是合法的。我们叫这个weak certificate为 reply certificate。
每一个replica会与每一个处于active状态的client共享一份秘钥。秘钥所占据空间较少,加上会限制active client的数量,所以不必担心以后出现的扩展性问题。
Normal Case Operation
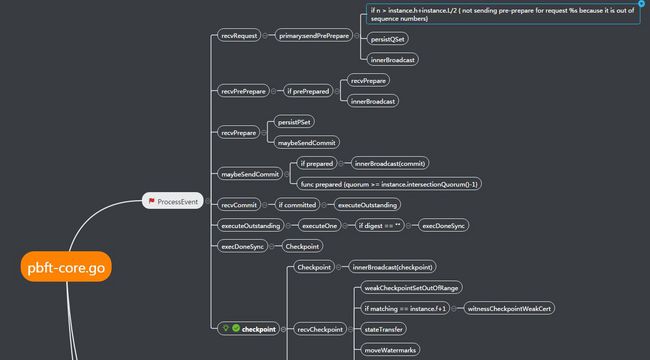
我们采用三阶段协议来广播请求给replicas:pre-prepare, prepare, commit。
pre-prepare阶段和prepare阶段用来把在同一个view里发送的请求给确定下序列,就是排好序,让各个replicas节点都认可这个序列,照序执行,当然里面可能会有拜占庭节点恶意操作,我们接下来会举出这种情况,以及三阶段协议是如何来处理这样的情况。
假设如图所示,目前我们有四个节点组成的分布式网络,replica 0担当主节点。
我们要提前清楚,在这个网络里,
1. 有可能四个节点都是乖节点(正确的、合法的)
2. 主节点是坏节点,其余三个备份节点是乖节点
3. 主节点是乖节点,三个备份节点里有一个是坏节点,其余是乖节点
不论上述三种情况哪一种出现,三阶段协议都能保证这个分布式网络健康、合法的运行。不会给坏节点可乘之机,从而避免破坏的出现。
prepare阶段和commit阶段用来确保那些已经达到commit状态的请求即使在发生view change后在新的view里依然保持原有的序列不变,比如一开始在view 0中,共有req 0, req 1, req2三个请求依次进入了commit阶段,假设没有坏节点,那么这四个replicas即将要依次执行者三条请求并返回给Client。但这时主节点问题导致view change的发生,view 0 变成 view 1,在新的view里,原本的req 0, req1, req2三条请求的序列被保留,作数。那些处于pre-prepare和prepare阶段的请求在view change发生后,在新的view里都将被遗弃,不作数。
pre-prepare阶段
主节点收到来自Client的一条请求并分配了一个编号给这个请求,然后主节点会广播一条PRE-PREPARE信息给备份节点,这个PRE-PREPARE信息包含该请求的编号、所在的view和自身的一个digest。直到该信息送达到每一个备份节点,接下来就看收到信息的备份节点们同不同意主节点分配给该请求的这个编号n,即是否accept这条PRE-PREPARE信息,如果一个备份节点accept了这条PRE-PREPARE,它就会进入下面的prepare阶段。
什么情况下备份节点会拒绝(not accept) PRE-PREPARE信息:当该备份节点之前已经接收到了一条在同一view下并且编号也是n,但是digest不同的PRE-PREPARE信息时,就会拒绝。
prepare阶段
一个备份节点进入到自己的prepare阶段后,开始将一条PREPARE信息广播给主节点和其它两个备份节点,直到PREPARE信息都抵达那三个节点。与此同时,该备份节点也会分别收到来自其它两个备份节点的PREPARE信息。该备份节点将综合这些PREPARE信息做出自己对编号n的最终裁决(这时进行的判断是在防止主节点是拜占庭节点的情况)。当这个备份节点开始综合比较来自其它两个备份节点的PREPARE信息和自身的PREPARE信息时,如果该备份节点发现其它两个节点都同意主节点分配的编号,又看了一下自己,自己也同意主节点的分配,a quorum certificate with the PRE-PREPARE and 2 f matching PREPARE messages for sequence number n, view v, and request m,如果一个replica达到了英文所说的条件,比如就是上面的斜体字描述的一种情况,那么我们就说该请求在这个replica上的状态是prepared,该replica就拥有了一个证书叫prepared certificate。那我们是不是就可以说至此排序工作已经完成,全网节点都达成了一个一致的请求序列呢,每一个replica开始照着这个序列执行吧。这是有漏洞的,设想一下,在t1时刻只有replica 1把请求m(编号为n)带到了prepared状态,其他两个备份节点replica 2, replica 3还没有来得及收集完来自其它节点的PREPARE信息进行判断,那么这时发生了view change进入到了一个新的view中,replica 1还认为给m分配的编号n已经得到了一个quorum同意,可以继续納入序列中,或者可以执行了,但对于replica 2来说,它来到了新的view中,它失去了对请求m的判断,甚至在上个view中它还有收集全其他节点发出的PREPARE信息,所以对于replica 2来说,给请求m分配的编号n将不作数,同理replica 3也是。那么replica 1一个人认为作数不足以让全网都认同,所以再新的view中,请求m的编号n将作废,需要重新发起提案。所以就有了下面的commit阶段。
- 需要注意的是,该备份节点会将自己收到的PRE-PREPARE和发送的PREPARE信息记录到自己的log中。
- 该备份节点发出PREPARE信息表示该节点同意主节点在view v中将编号n分配给请求m,不发即表示不同意。
- 如果一个replica对请求m发出了PRE-PREPARE和PREPARE信息,那么我们就说该请求m在这个replica节点上处于pre-prepared状态。
commit阶段
紧接着prepare阶段,当一个replica节点发现有一个quorum同意编号分配时,它就会广播一条COMMIT信息给其它所有节点告诉他们它有一个prepared certificate了。与此同时它也会陆续收到来自其它节点的COMMIT信息,如果它收到了2f+1条COMMIT(包括自身的一条,这些来自不同节点的COMMIT携带相同的编号n和view v),我们就说该节点拥有了一个叫committed certificate的证书,请求在这个节点上达到了committed状态。此时只通过这一个节点,我们就能断定该请求已经在一个quorum中到达了prepared状态,即一个quorum的节点们都同意了编号n的分配。当请求m到达commited状态后,该请求就会被该节点执行。
三阶段介绍完毕。我们想象一种情况,主节点是坏的,它在给请求编号时故意选择了一个很大的编号,以至于超出了序号的范围,所以我们需要设置一个低水位(low water mark)h和高水位(high water mark)H,让主节点分配的编号在h和H之间,不能肆意分配。
Garbage Collection
分布式系统的复杂性在于要考虑到各种各样的意外和蓄意破坏,你要制定出一套有效的法律来约束这个系统里可能发生的一切行为,并没有完美的分布式系统存在。
当replica执行完请求时,需要把之前记录的该请求的信息清除掉。但是不能这样轻易的去清除,其中包含的prepared certificate可能会在后面用得上。所以要有种机智来保证何时可以清除。
其实很简单,每执行完一条请求,该节点会再一次发出广播,就是否可以清除信息在全网达成一致。更好的方案是,我们一连执行了K条请求,在第K条请求执行完时,向全网发起广播,告诉大家它已经将这K条执行完毕,要是大家反馈说这K条我们也执行完毕了,那就可以删除这K条的信息了,接下来再执行K条,完成后再发起一次广播,即每隔K条发起一次全网共识,这个概念叫checkpoint,每隔K条去征求一下大家的意见,要是获得了大多数的认同(a quorum certificate with 2 f + 1 CHECKPOINT messages (including its own)),就形成了一个 stable checkpoint(记录在第K条的编号),我们也说该replica拥有了一个stable certificate就可以删除这K条请求的信息了。
这是理想的情况,实际上当replica i向全网发出checkpoint共识后,其他节点可能并没有那么快也执行完这K条请求,所以replica i不会立即得到响应,它还要继续自己的步伐,那这个checkpoint在它那里就不是stable的。那这个步伐快的replica可能会越来越快,可能会把大家拉的越来越远,这时我们来看一下上面提到的高低水位的作用。对该replica来说,它的低水位h等于它上一个stable checkpoint的编号,高水位H=h+L,L是我们指定的数值,它一般是checkpoint周期K的常数倍(这个常数是比较小的, 比如2倍),这样即使该replica步伐很快,它处理的请求编号达到高水位H后也得停一停自己的脚步,直到它的stable checkpoint发生变化,它才能继续向前。
View Changes
当主节点挂掉后就触发了view change协议。我们需要确保在新的view中如何来延续上一个view最终的状态,比如给这时来的新请求的编号,还有如何处理上一个view还没来得及完全处理好的请求。
Data Structures
所以我们需要记录上一个view里发生什么。
有两个集合P和Q,replica i 的P存着 i 在上一 view 中达到prepared状态的请求的一些信息,有了P,在新的view中,replica i就会明白接下来处于prepared状态的请求不能与上一个view中处于prepared状态的请求的编号相同。Q是记录在上一个view里到达pre-prepared状态的请求的一些信息。
View-Change Messages
我们来看一下Fig 2, 当备份节点 i 怀疑 view v中的主节点出问题(比如是坏节点)后,它会进入 view v+1,并广播一条VIEW-CHANGE信息给所有的replicas,其中包含该replica i最新的stable checkpoint的编号,还有 replica i上存的每一个checkpoint的编号和digest的集合,还有上面所说的该replica的P和Q两个集合。
View-Change-Ack Messages
replicas 会收集VIEW-CHANGE信息并发送ACK确认给 view v+1 中的主节点
。新的主节点收集了VIEW-CHANGE和VIEW-CHANGE-ACK(包含自己的信息),它会将VIEW-CHANGE存在一个集合S中。主节点需要选出一个checkpoint作为新view处理请求的起始状态。它会从checkpoint的集合中选出编号最大(假设编号为h)的checkpoint。接下来,主节点会从h开始依次选取h到h+L(L就是normal case阶段我们提到的设置值)之间的编号n对应的请求在新的view中进行pre-prepare,如果一条请求在上一个view中到达了committed状态,主节点就选取这个请求开始在新的view中进行三阶段。之所以选取committed的请求,是因为上面我们提到增加COMMIT阶段为了across view来考虑的,处于committed状态的请求的编号在新的view中是有效的,可以继续使用。但是如果选取的请求在上一view中并没有被一个quorum给prepare,那它的编号n有可能是不被一个quorum给同意的,我们选择在新的view中作废这样的请求。

fabric-master下有这样几个重要的子目录:
- consensus
- controller
- executor
- helper
- noops
- obcpbft
- consensus.go
- core
- chaincode
- crypto
- db
- discovery
- ledger
- peer
- system_chaincode
- fsm.go
- events
- consumer
- producer
- membersrvc
- peer
- main.go
- core.yaml
- protos
- block.go
- chaincode.pb.go
- events.pb.go
- fabric.pb.go
- transaction.go
我们可以根据这些目录和文件来学习PBFT或者fabric的共识算法。