吴恩达机器学习总结:第十四 大型机器学习(大纲摘要及课后作业)
为了更好的学习,充分复习自己学习的知识,总结课内重要知识点,每次完成作业后都会更博。
英文非官方笔记
总结
1.大数据集的学习
(1)长处及缺陷
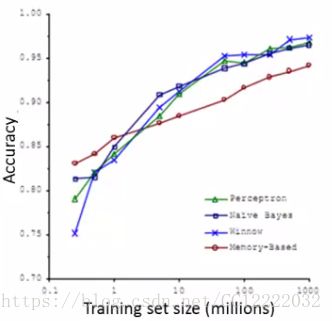
a.获得高性能的最佳方法之一是采用低偏置算法并对大量数据进行训练
b.我们看到只要提供大量数据的算法,它们的表现都非常相似
c.但是,使用大型数据集进行学习会带来其自身的计算问题
(2)这种大规模总结的计算成本,我们将考虑更有效的方法
a. 使用不同的方法
b. 优化以避免总和
2.随机梯度下降
(1)对于许多学习算法,我们通过提出优化目标(成本函数)并使用算法来最小化该成本函数来推导出它们
a.当你有一个大的数据集,梯度下降变得非常昂贵
b.因此,在这里我们将定义一种不同的方式来优化大数据集,这将允许我们扩展算法
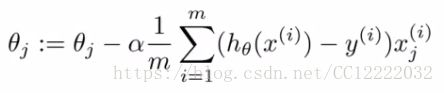
(2)假如你训练一个带梯度下降的线性回归模型
a.假设
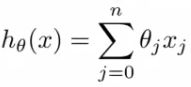
b.代价函数
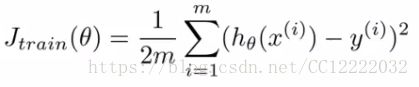
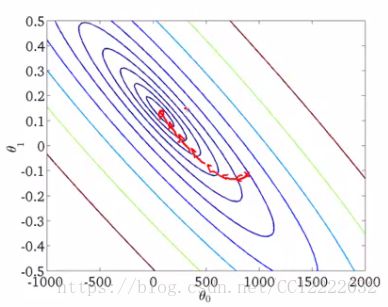
c.如果我们绘制两个参数与成本函数的关系,我们可以得到类似的结果
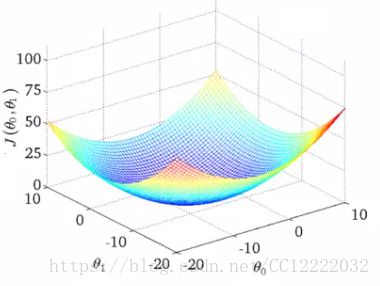
d.看起来像这个碗形表面
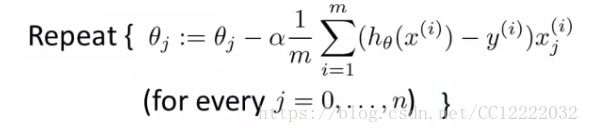
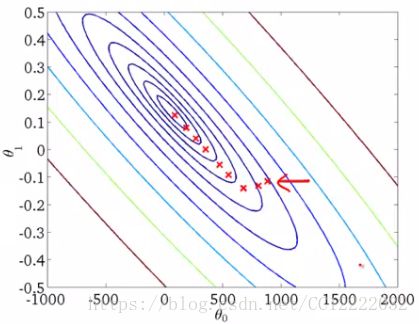
(3)虽然到目前为止我们只是将其称为梯度下降,但这种梯度下降称为批梯度下降
a.这仅仅意味着我们在同一时间看所有的例子
b.并不适用与大数据集
c.需要很长时间收敛
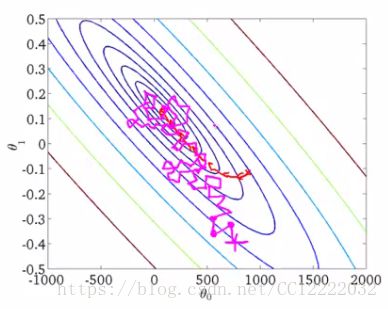
(4)随机梯度下降
a.定义代价函数
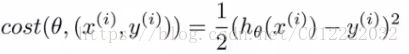
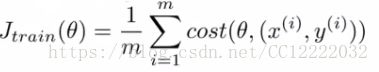
b.通过这个线性回归的稍微修改(但是等价的)视图,我们可以写出随机梯度下降的工作方式
c.随机洗牌

d.算法本体

(5)批梯度下降和随机梯度下降对比
3.最小批梯度下降
(1)一种比随机梯度下降更快的算法
(2)三种梯度下降比较
a.批梯度下降:每次迭代用m个样本数据
b.随机梯度下降:每次迭代用1个样本数据
c.最小批梯度下降:每次迭代用b个样本数据(b=2-100)
(3)算法
a.与批量梯度下降相比,这使我们能够以更高效的方式获取数据
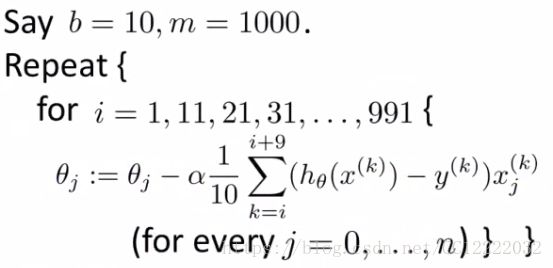
(4)最小批梯度下降VS随机梯度下降
a.最小批量允许有一个矢量化的实现
b.最小批量手段实施更有效率
c.最小批量可以部分并行计算
d.最小批量缺点是参数b的优化(但是是值得的)
e.随机梯度下降和分批梯度下降只是批梯度下降的具体形式
f.对于最小批量梯度下降,b在1到m之间,您可以尝试优化它!
4.随机梯度下降收敛
(1)代价函数
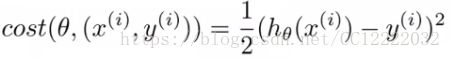
(2)画图
a.普通绘图
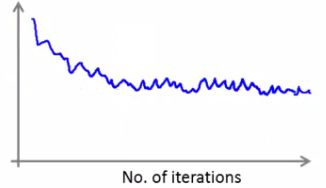
b.用很小的学习率
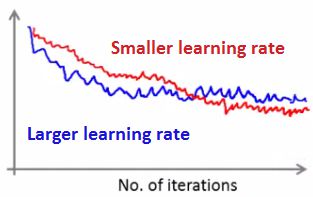
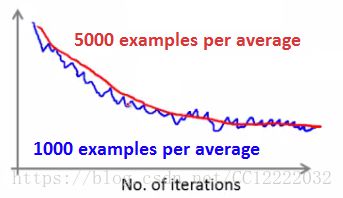
c.如果平均超过1000个示例和5000个示例,则可能会获得更平滑的曲线
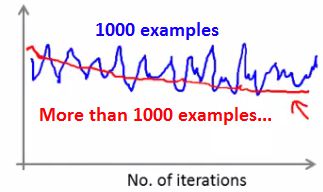
d.较大平均值的这种缺点意味着您得到的反馈较少
(3)学习率
a.我们看到随着随机梯度下降,我们得到这个在最小值附近徘徊
b.在大多数实施中,学习率不变(如果想收敛到最低限度,可以逐渐减少学习率)
c.这样做的经典方法是按如下方式计算α(α = const1/(iterationNumber + const2))
d.您还需要确定const1和const2
e.但如果你调好参数,你可以得到这样的东西
5.在线学习
(1)示例-送货服务
a.用户来告诉你来源和目的地
b.ni 提供运输包装的一定金额(10美元至50美元)
c.根据你提供的价格,有时用户使用你的服务(y = 1),有时他们不会(y = 0)
d.建立一个算法来优化我们为用户提供的价格(捕获和锻炼)
(2)最优化价格
a.p(y = 1|x; θ)
b.用类似的东西来构建这个模型(逻辑回归或者神经网络)
(3)有一个连续运行的网站,在线学习算法可以做这样的事情
a.用户来了,可表示为(x,y),x表示特征向量,包括价格,产地,目的地,y表示选择使用我们的服务或不
b.该算法仅使用(x,y)对来更新θ
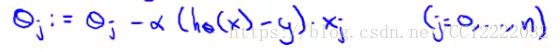
c.我们每次获得新的数据时都会更新所有的θ参数
(4)如果你有一个拥有大量数据流的主要网站,那么这种算法非常合理
(5)如果您的用户数量较少,则可以保存其数据,然后在数据集上运行常规算法。在线算法可以适应不断变化的用户偏好
a.随着时间的推移,用户可能会变得更加敏感
b.算法适应并学习到这一点
c.所以你的系统是动态的
6.映射减少和数据并行
(1)映射减少例子
a.批梯度下降(m很大时计算就会很昂贵)
![]()
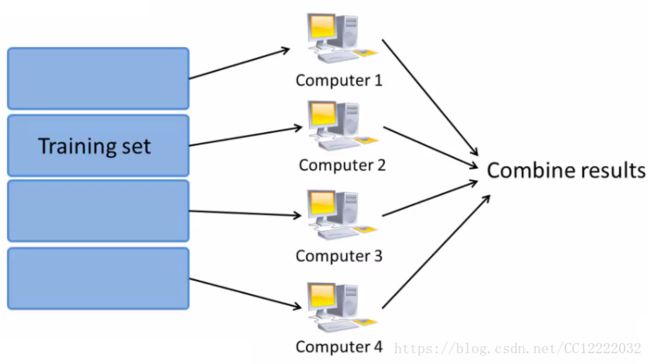
b.将训练集分成几个部分(这里分成4部分)
c.机器1:只是用m/4个(m这里为400)总和

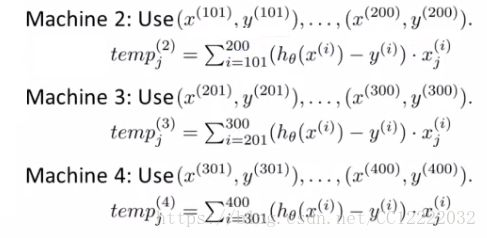
d.每台机器完成1/4的工作,得到四个临时值(发送到主服务器,然后放在一起更新)

e.结构
(2)另外一个例子
a.用逻辑回归的最优化算法

b.梯度下降
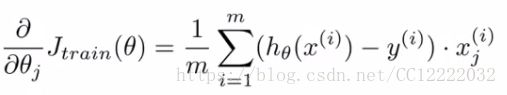
c.因此,通过这些结果向中央服务器发送临时数据以处理所有事情
d.更广泛地说,通过采用计算总和的算法,您可以通过并行化将它们扩展到非常大的数据集
e.考虑到映射减少的优势在于无需担心网络问题(这一切都在同一台机器内部)