前言
什么是线性表?
线性表的两大存储结构是什么?
各种存储结构是如何实现存取、插入删除等操作的?
本篇主要解答了这几个问题,感兴趣的话一起来看看吧~
什么是线性表?
线性表 从字面大概能想象出线的样式,那么怎么样才算是一个线性表呢?这里有一个定义:零个或多个数据元素的有限序列称为 线性表(List) 。元素之间是有序的,若有多个元素,则第一个元素无前驱,最后一个元素无后继,其他每个元素只有一个前驱和后继。
线性表的顺序存储结构

线性表的顺序存储示意图

线性表的顺序存储示意图
线性表的 顺序存储结构 是线性表 物理结构 中的一种,指的是用一段地址连续的存储单元依次存储线性表的数据元素。
1、顺序存储需要什么?
描述顺序存储结构需要的三个属性:
- 存储空间的起始位置:数组 data 的存储位置就是存储空间的存储位置;
- 线性表的最大存储容量:数组长度 MaxSize;
- 线性表的当前长度:length.
#define MAXSIZE 20 /* 存储空间的初始分配量 */ typedef int ElemType; /* ElemType 类型视实际而定,这里为 int */ typedef struct { ElemType data[MAXSIZE]; /* 数组存储数据元素,最大值为 MAXSIZE */ int length; } SqList;这里的数组 data 长度与线性表长度有什么区别?
数组长度在创建之初就已经知道了,这个量一般是不变的;
线性表长度是线性表中数据元素的个数,它会随着线性表的插入、删除操作而变化;
任何时刻,线性表长度小于或等于数组长度.
顺序存储结构的插入与删除
1、获取元素
对于线性表的顺序存储结构,如果我们要实现 GetElem 操作,只需将线性表 L 中第 i 个位置的元素值返回即可.
#define OK 1 #define ERROR 0 #define TRUE 1 #define FALSE 0 typedef int Status; /* Status 的值是函数的结果状态,如 OK 等 */ /* 初始条件:顺序线性表 L 已存在,1 <= i <= ListLength(L) */ /* 操作结果:用 e 返回 L 中第 i 个数据元素的值 */ Status GetElem(SqList L; int i, ElemType *e) { if (L.length == 0 || i < 1 || i > L.length) return ERROR; * e = L.data[i - 1]; return OK; }2、插入新元素
如果我们要实现 Listin-sert(*L, i, e),即怎么在线性表 L 中的第 i 个位置插入新元素 e?这里就用到了插入算法。
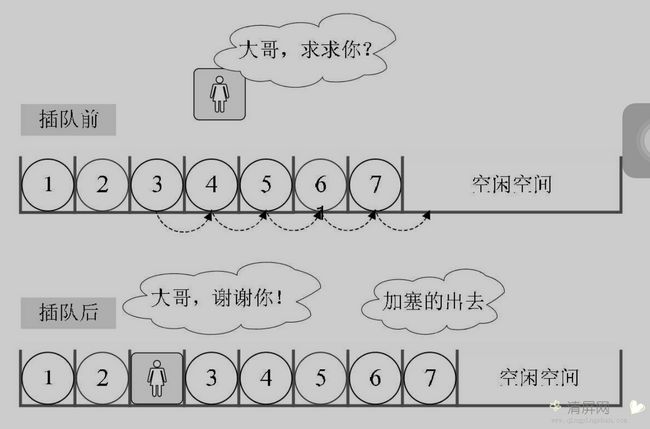
插入算法思路:
- 如果插入位置不合理,抛出异常;
- 如果线性表长度 >= 数组长度,抛出异常或动态增加容量;
- 从最后一个元素开始向前遍历到第 i 个位置,分别将它们都向后移动一个位置;
- 将要插入元素填入位置 i 处,线性表长+1.
/* 初始条件:顺序线性表 L 已存在,1 <= i <= ListLength(L) */ /* 操作结果:在 L 中第 i 个位置之前插入新的数据元素 e,L 长度为加 1 */ Status ListInsert(SqList *L, int i, ElemType e) { int k; /* 顺序线性表已经满 */ if (L->length == MAXSIZE) return ERROR; /* 当i不在范围内时 */ if (i < 1 || i > L-> length + 1) return ERROR; /* 若插入数据位置不在表尾 */ if (i <= L->Length) { /*将要插入位置后数据元素向后移动一位 */ for (k = L->length - 1; k >= i -1; k--) L->data[k + 1] = L->data[k]; } L->data[i - 1] = e; /* 将新元素插入 */ L->length++; return OK; }3、删除元素
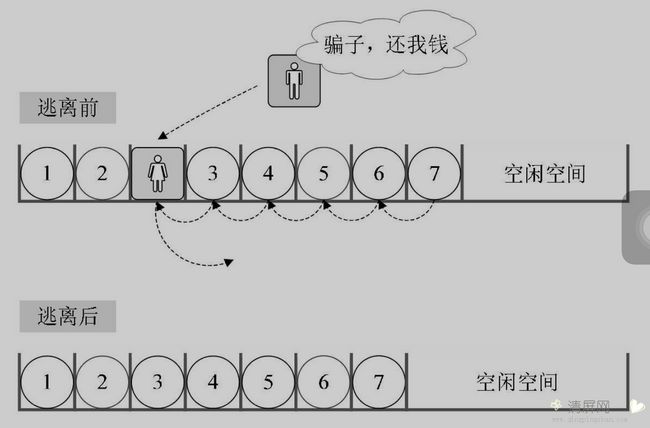
删除算法思路:
- 如果删除位置不合理,抛出异常;
- 取出删除元素;
- 从删除元素位置开始遍历到最后一个元素位置,分别将它们都向前移动一个位置;
- 线性表长 -1.
/* 初始条件:顺序线性表L已存在,1≤i≤ ListLength(L) */ /* 操作结果:删除 L 的第 i 个数据元素,并用 e 返回 其值,L 的长度 -1 */ Status ListDelete(SqList *L, int i, ElemType *e) { int k; if (L->length == 0) return ERROR; if (i < 1 || i > L->length) return ERROR; *e = L->data[i - 1]; /* 如果删除不是最后位置 */ if (i < L->length) { /* 将删除位置后继元素前移 */ for (k = i; k < L->length; k++) L->data[k - 1] = L->data[k]; } L->length--; return OK; }线性表的顺序存储结构时间复杂度
- 在存和取数据元素时,在任何位置,时间复杂度都为 O(1);
- 插入、删除时,(平均)时间复杂度为 O(n).
顺序存储结构优缺点
- 优:可快速存取表中任一位置元素;
- 缺:插入、删除操作需移动大量元素;当线性表长度变化大时,无法确定存储空间容量;存储空间的浪费.
线性表的链式存储结构
在顺序结构中,每个数据元素只需存数据元素的信息就可以了。而链式结构中需要存储两种数据 -- 数据域 、 指针域 ,两部分信息组成的数据元素,称为节点(Node).
数据域 用来存储数据元素信息;
指针域 用来存储直接后继地址.

1、头结点
头结点 的数据域,可以不存储任何信息,也可以存储如线性表的长度等信息;头结点指针域存储第一个非空结点的地址,若线性表为空表,头结点指针域为 NULL。
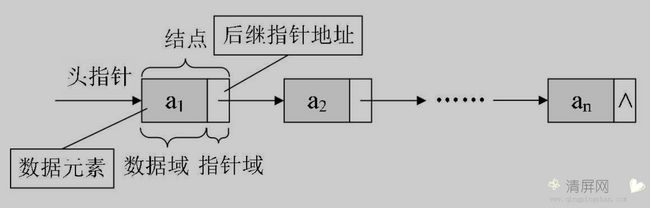
带头结点的单链表
C 语言创建 单链表 :
/* 线性表的单链表存储结构 */ typedef struct Node { ElemType data; struct Node *next; } Node; /* 定义 LinkList */ typedef struct Node *LinkList2、最后一个结点
最后一个结点 指针用 NULL 或 '^' 表示。

假设 p 是指向线性表第 i 个元素的 指针 ,则该 结点 a(i) 的数据域我们可以用p->data 来表示, p->data 的值是一个数据元素,结点 a(i) 的指针域可以用p->next 来表示, p->next 的值是一个指针。如果 p->data = a(i) ,那么p->next->data = a(i+1)

p->data, p->next->data
单链表
1、单链表的读取
获取单链表第 i 个数据的算法思路:
- 声明一个
指针 p指向链表第一个结点,初始化 j从 1 开始; - 当
jp的指针向后移动,不断指向下一结点,j累加 1; - 若到链表末尾
p为空,则说明第 i 个结点不存在; - 否则查找成功,返回
结点 p的数据。
实现算法代码:
/* 初始条件:顺序线性表 L 已存在,1 ≤ i ≤ ListLength(L) */ /* 操作结果:用 e 返回 L 中第 i 个数据元素的值 */ Status GetElem(LinkList L, int i, ElemType *e) { int j; LinkList p; p = L->next; j = 1; while(p && j < i) { p = p->next; ++j; } /* 第 i 个结点不存在 */ if(!p || j > i) return ERROR; *e = p->data; return OK; }
上面代码很容易理解,从头找到第 i 个结点为止。查找的时间复杂度为 O(n)。
2、单链表的插入和删除
2.1、单链表插入结点
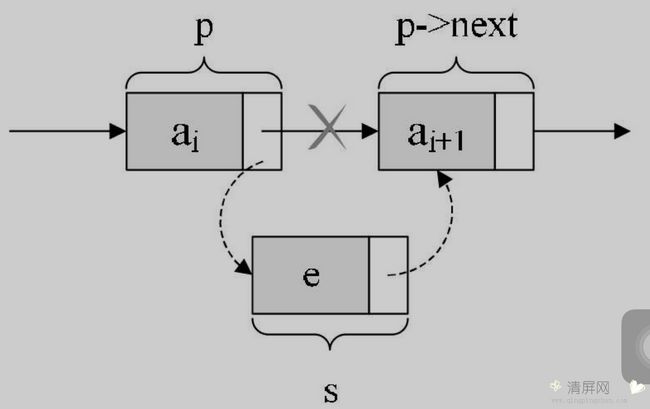 插入结点
插入结点
实现思路如下:
s->next = p->next;
p->next = s;
单链表插入结点 算法实现代码如下:
/* 初始条件:顺序线性表 L 已存在,1 ≤ i ≤ ListLength(L) */ /* 操作结果:在 L 中第 i 个结点位置之前插入新结点 e,L长度+1 */ Status ListInsert(LinkList *L, int i, ElemType e) { int j; LinkList p, s; p = *L; j = 1; /* 寻找第 i - 1 个结点 */ while(p && j < i) { p = p->next; ++j; } /* 第 i 个结点不存在 */ if(!p || j > i) return ERROR; /* 生成新结点(C 标准函数) */ s = (LinkList)malloc(sizeof(Node)); s->data = e; s->next = p->next; p->next = s; return OK; }
s = (LinkList)malloc(sizeof(Node)); 这里用到了 C 语言的 malloc标准函数,实质上就是拿出一块空的内存,用来存放新的 结点 s 。
2.2、单链表删除结点
 删除结点
删除结点
实现思路如下:
q = p->next;
p->next = q ->next;
单链表删除结点 算法实现代码如下:
/* 初始条件:顺序线性表 L 已存在,1 ≤ i ≤ ListLength(L) */ /* 操作结果:删除 L 的第 i 个结点,并用 e 返回其值,L 的长度 -1 */ Status ListDelete(LinkList *L, int i, ElemType *e) { int j; LinkList p, q; p = *L; j = 1; while(p->next && j < i) { p = p->next; ++j; } if(!(p->next) || j > i) return ERROE; q = p->next; p->next = q->next; *e = q->data; free(q); return OK; }
free(q); 这里用到了 C 语言的标准函数 free,作用是释放一个结点的内存。
在我们不知道第 i 个结点的指针位置时,假设我们从 i 位置,插入 n 个结点。顺序存储结构的时间复杂度为 O(n^2) ,链式存储结构的时间复杂度为 O(n) 。显然单链表数据结构插入和删除操作,比顺序存储结构效率要高。
3、单链表的整表创建
首先创建一个空的单链表,然后插入一个个新结点,新结点插入一般用两种方式 --头插法 、 尾插法 。
头插法 :每次新结点都插在第一的位置;尾插法 :每次新结点都插在终端结点的后面。
头插法算法实现代码:
/* 随机产生 n 个元素的值,建立表头结点的单链线性表 L(头插法) */ void CreatListHead(LinkList *L, int n) { LinkList p; int i; /* 初始化随机种子数 */ srand(time(0)); *L = (LinkList)malloc(sizeof(Node)); /* 创建一个带头结点的单链表 */ (*L)->next = NULL; for(i = 0; i < n; i++) { p = (LinkList)malloc(sizeof(Node)); /* 随机生成 100 以内的数 */ p->data = rand() % 100 + 1; p->next = (*L)->next; (*L)->next = p; } }
算法实现过程根据示意图很容易理解。上面代码中用到了 srand(time(0)) ,这里的目的是初始化一个随机数种子。实质上就是后面每次 rand() 时,不同时刻可以拿到不同的数,这个数就是 1970.1.1 至今的秒数。这样就能确保每次我们拿到的都是不同的数字。
尾插法算法实现代码:
/* 随机产生 n 个元素的值,建立带表头结点的单链表 L(尾插法) */ void CreatListTail(LinkList *L, int n) { LinkList p, r; int i; srand(time(0)); *L = (LinkList)malloc(sizeof(Node)); r = *L; for(i = 0; i < n; i++) { p = (Node *)malloc(sizeof(Node)); p->data = rand() % 100 + 1; r->next = p; r = p; } r->next = NULL; }
了解头插法后看尾插法应该很容易理解了。
4、单链表的整表删除
算法实现代码如下:
/* 初始条件:单链表 L 已存在 */ /* 操作结果:将 L 重置为空表 */ Status ClearList(LinkList *L) { LinkList p, q; p = (*L)->next; while(p) { q = p->next; free(p); p = q; } (*L)->next = NULL; return OK; }
4、单链表结构与顺序结构对比
- 若线性表需要频繁查找,很少进行插入删除操作,宜采用
顺序存储结构 。若需要频繁插入删除,宜采用 单链表结构 。如游戏开发中,对于用户注册的个人信息,注册时插入数据后绝大多数只是读取,可以考虑用顺序存储结构;而游戏中玩家的武器装备列表,随着玩家的游戏进度,可能会随时增加或删除,单链表结构更合适。这里是简单类比,实际考虑的会更多。
- 当线性表中的元素个数变化较大或者不确定元素个数,最好用
单链表结构 ,这样不需要考虑存储空间大小问题。如果知道线性表大致长度(像一年 12 月,一周 7 天...),这时 顺序存储结构 效率会高很多。
静态链表
对于C 语言,它具有指针能力,使得它可以方便地操作内存中的地址和数据;对于 Objective - C 之类面向对象的语言,因为他们有对象引用机制,间接实现了指针的一些作用;但对于一些早期的编程高级语言(Basic 等),它们没有指针,按前面的方法链表结构就无法实现了。但方法总是会有的,就诞生了静态链表。
1、什么是静态链表?
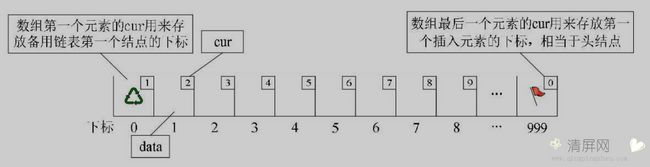 静态链表
静态链表
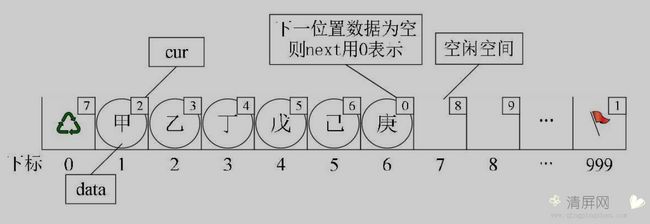 静态链表
静态链表
首先我们让数组的元素都是由两个数据域组成, data 和 cur 。也就是说,数组的每一个下标都对应一个 data 和一个 cur 。
数据域 data 用来存放数据元素,也就是通常我们要处理的数据;而游标 cur 相当于单链表中的 next 指针,存放该元素的后继在数组中的下标。我们把这种用数组描述的链表叫做 静态链表 。
数组的第一个元素,即下标为 0 的元素的 cur 就存放备用链表的第一个结点的下标;而数组的最后一个元素的 cur 则存放第一个有数值的元素的下标,相当于单链表的头节点作用,当整个链表为空时,则为 0 ,表示无指向。
初始化代码如下:
/* 线性表的静态链表存储结构 */ #define MAXSIZE 1000 typedef struct { ElemType data; int cur; } StaticLinkList[MAXSIZE]; /* 将一维数组space中各分量链成一备用链表, */ /* space[0].cur为头指针,"0"表示空指针 */ Status InitList(StaticLinkList space) { int i; for (i = 0; i < MAXSIZE - 1; i++) space[i].cur = i + 1; /* 目前静态链表为空,最后一个元素的cur为0 */ space[MAXSIZE - 1].cur = 0; return OK; }
2、静态链表的插入操作
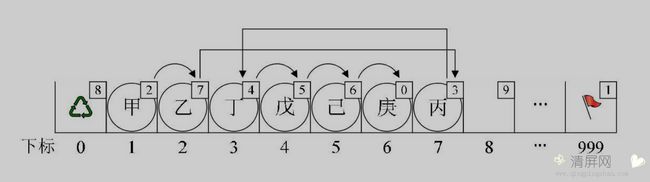
静态链表的插入操作
在动态链表中,结点的申请和释放分别借用 malloc() 和 free() 两个函数来实现。在静态链表中,操作的是数组,不存在像动态链表的结点申请和释放问题,所以我们需要自己实现这两个函数,才可以做插入和删除的操作。
为辨明数组中哪些分量未被使用,将所有未被使用过的及已被删除的分量用游标链成一个备用的链表,每当进行插入时,便可以从备用链表上取得第一个结点作为待插入的新结点。如下代码:
/* 若备用空间链表非空,则返回分配的结点下标,否则返回0 */ int Malloc_SLL(StaticLinkList space) { /* 当前数组第一个元素的cur存的值,就是要返回的第一个备用空闲的下标 */ int i = space[0].cur; /* 由于要拿出一个分量来使用了,所以我们就得把它的下一个分量用来做备用 */ if (space[0].cur) space[0].cur = space[i].cur; return i; } /* 在L中第i个元素之前插入新的数据元素e */ Status ListInsert(StaticLinkList L, int i, ElemType e) { int j, k, l; /* 注意 k 是最后一个元素的下标 */ k = MAX_SIZE - 1; if (i < 1 || i > ListLength(L) + 1) return ERROR; /* 获得空闲分量的下标 */ j = Malloc_SSL(L); if (j) { /* 将数据赋值给此分量的 data */ L[j].data = e; /* 找到第i个元素之前的位置 */ for (l = 1; l <= i - 1; l++) k = L[k].cur; /* 把第i个元素之前的cur赋值给新元素的cur */ L[j].cur = L[k].cur; /* 把新元素的下标赋值给第i个元素之前元素的cur */ L[k].cur = j; return OK; } return ERROR; }
3、静态链表的删除操作

静态链表的删除操作
和插入操作原理相同,删除操作代码如下:
/* 删除在 L 中第 i 个数据元素 e */ Status ListDelete(StaticLinkList L, int i) { int j, k; if (i < 1 || i > ListLength(L)) return ERROR; k = MAX_SIZE - 1; for (j = 1; j <= i - 1; j++) k = L[k].cur; j = L[k].cur; L[k].cur = L[j].cur; Free_SSL(L, j); return OK; } /* 将下标为k的空闲结点回收到备用链表 */ void Free_SSL(StaticLinkList space, int k) { /* 把第一个元素 cur 值赋给要删除的分量 cur */ space[k].cur = space[0].cur; /* 把要删除的分量下标赋值给第一个元素的 cur */ space[0].cur = k; } /* 初始条件:静态链表 L 已存在。操作结果:返回 L 中数据元素个数 */ int ListLength(StaticLinkList L) { int j = 0; int i = L[MAXSIZE - 1].cur; while (i) { i = L[i].cur; j++; } return j; }
4、静态链表优缺点
- 优点:在插入删除操作时,只需要修改游标,不需要移动元素;
- 缺点:失去顺序存储结构随机存取的特性,存储需要的表长难以确定。
静态链表给没有指针的高级语言设计了一种实现单链表能力的方法,实际中不一定用到,但这个是思想很赞的。
循环链表
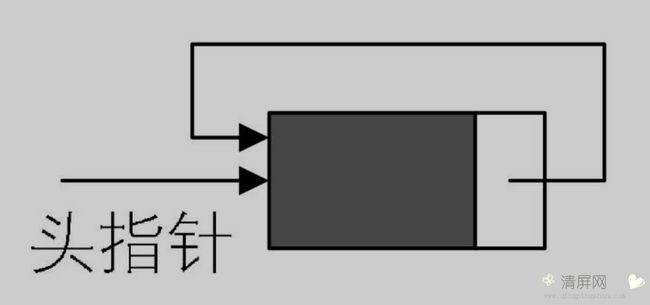 空循环链表
空循环链表
 非空循环链表
非空循环链表
将单链表中 终端结点 的指针由空指针指向 头结点 ,使单链表形成一个环,这种头尾相连的单链表称为 单循环链表 ,简称 循环链表 。
循环链表中,从任何一个结点出发,可以访问到链表的全部结点。
在当循环列表中,访问第一个结点的时间复杂度是 O(1);而访问最后一个结点的时间复杂度是 O(n)。那有没有可能,用 O(1) 时间访问到最后一个节点呢?这里我们改造下循环链表,用指向最后一个结点的尾指针,不用头指针,就可以很方便的查找头结点和尾结点了。
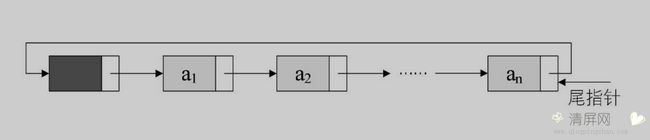 尾指针
尾指针
尾指针有什么方便之处呢?看下下面这两个链表的合并。

合并两循环链表 - 前
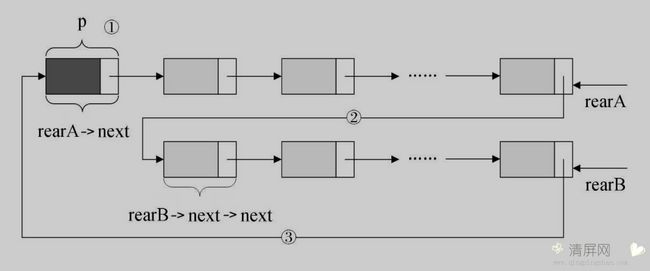
合并两循环链表 - 后
/* 保存A表的头结点,即① */ p = rearA->next; /*将本是指向B表的第一个结点(不是头结点) */ rearA->next = rearB->next->next; /* 赋值给reaA->next,即② */ q = rearB->next; /* 将原A表的头结点赋值给rearB->next,即③ */ rearB->next = p; /* 释放 q */ free(q);
双向链表
双向链表中结点拥有两个指针域,一个指向直接前驱,一个指向直接后继。
/* 线性表的双向链表存储结构 */ typedef struct DulNode { ElemType data; struct DuLNode *prior; /* 直接前驱指针 */ struct DuLNode *next; /* 直接后继指针 */ } DulNode, *DuLinkList;

双向链表的循环带头结点的空链表
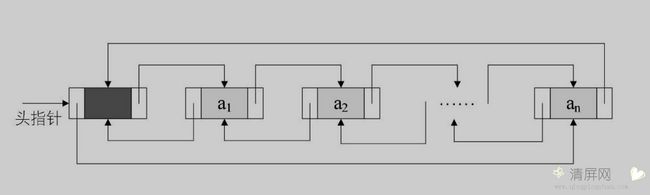
非空的循环的带头结点的双向链表
/* 链表中的某一结点 p */ p->next->prior = p = p->prior->next
假设存储元素 e 的结点 s,要实现将结点 s 插入到结点 p 和 p->next 之间,如下:
 结点插入
结点插入
/* 把p赋值给s的前驱,如图中① */ s->prior = p; /* 把p->next赋值给s的后继,如图中② */ s->next = p->next; /* 把s赋值给p->next的前驱,如图中③ */ p->next->prior = s; /* 把s赋值给p的后继,如图中④ */ p->next = s;
理解了插入操作,删除操作就比较简单了,示意图如下:
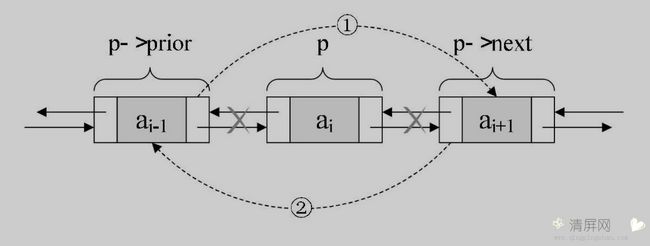 删除结点 p
删除结点 p
/* 把p->next赋值给p->prior的后继,如图中① */ p->prior->next = p->next; /* 把p->prior赋值给p->next的前驱,如图中② */ p->next->prior = p->prior; /* 释放结点 */ free(p);