一、Storm集成HDFS
1.1 项目结构
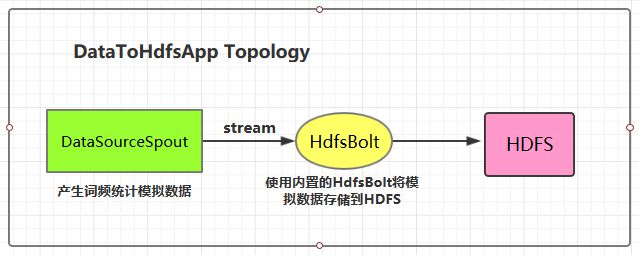
本用例源码下载地址:storm-hdfs-integration
1.2 项目主要依赖
项目主要依赖如下,有两个地方需要注意:
- 这里由于我服务器上安装的是 CDH 版本的 Hadoop,在导入依赖时引入的也是 CDH 版本的依赖,需要使用
hadoop-common、hadoop-client、hadoop-hdfs均需要排除slf4j-log4j12依赖,原因是storm-core中已经有该依赖,不排除的话有 JAR 包冲突的风险;
1.2.2
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
org.apache.storm
storm-core
${storm.version}
org.apache.storm
storm-hdfs
${storm.version}
org.apache.hadoop
hadoop-common
2.6.0-cdh5.15.2
org.slf4j
slf4j-log4j12
org.apache.hadoop
hadoop-client
2.6.0-cdh5.15.2
org.slf4j
slf4j-log4j12
org.apache.hadoop
hadoop-hdfs
2.6.0-cdh5.15.2
org.slf4j
slf4j-log4j12
1.3 DataSourceSpout
/**
* 产生词频样本的数据源
*/
public class DataSourceSpout extends BaseRichSpout {
private List list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
} 产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm1.4 将数据存储到HDFS
这里 HDFS 的地址和数据存储路径均使用了硬编码,在实际开发中可以通过外部传参指定,这样程序更为灵活。
public class DataToHdfsApp {
private static final String DATA_SOURCE_SPOUT = "dataSourceSpout";
private static final String HDFS_BOLT = "hdfsBolt";
public static void main(String[] args) {
// 指定 Hadoop 的用户名 如果不指定,则在 HDFS 创建目录时候有可能抛出无权限的异常 (RemoteException: Permission denied)
System.setProperty("HADOOP_USER_NAME", "root");
// 定义输出字段 (Field) 之间的分隔符
RecordFormat format = new DelimitedRecordFormat()
.withFieldDelimiter("|");
// 同步策略: 每 100 个 tuples 之后就会把数据从缓存刷新到 HDFS 中
SyncPolicy syncPolicy = new CountSyncPolicy(100);
// 文件策略: 每个文件大小上限 1M,超过限定时,创建新文件并继续写入
FileRotationPolicy rotationPolicy = new FileSizeRotationPolicy(1.0f, Units.MB);
// 定义存储路径
FileNameFormat fileNameFormat = new DefaultFileNameFormat()
.withPath("/storm-hdfs/");
// 定义 HdfsBolt
HdfsBolt hdfsBolt = new HdfsBolt()
.withFsUrl("hdfs://hadoop001:8020")
.withFileNameFormat(fileNameFormat)
.withRecordFormat(format)
.withRotationPolicy(rotationPolicy)
.withSyncPolicy(syncPolicy);
// 构建 Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout());
// save to HDFS
builder.setBolt(HDFS_BOLT, hdfsBolt, 1).shuffleGrouping(DATA_SOURCE_SPOUT);
// 如果外部传参 cluster 则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterDataToHdfsApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalDataToHdfsApp",
new Config(), builder.createTopology());
}
}
}1.5 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true运行后,数据会存储到 HDFS 的 /storm-hdfs 目录下。使用以下命令可以查看目录内容:
# 查看目录内容
hadoop fs -ls /storm-hdfs
# 监听文内容变化
hadoop fs -tail -f /strom-hdfs/文件名
二、Storm集成HBase
2.1 项目结构
集成用例: 进行词频统计并将最后的结果存储到 HBase,项目主要结构如下:
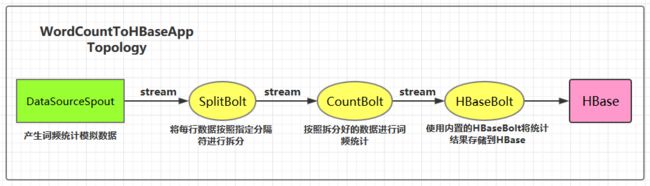
本用例源码下载地址:storm-hbase-integration
2.2 项目主要依赖
1.2.2
org.apache.storm
storm-core
${storm.version}
org.apache.storm
storm-hbase
${storm.version}
2.3 DataSourceSpout
/**
* 产生词频样本的数据源
*/
public class DataSourceSpout extends BaseRichSpout {
private List list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模拟产生数据
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模拟数据
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
} 产生的模拟数据格式如下:
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm2.4 SplitBolt
/**
* 将每行数据按照指定分隔符进行拆分
*/
public class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] words = line.split("\t");
for (String word : words) {
collector.emit(tuple(word, 1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}2.5 CountBolt
/**
* 进行词频统计
*/
public class CountBolt extends BaseRichBolt {
private Map counts = new HashMap<>();
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = counts.get(word);
if (count == null) {
count = 0;
}
count++;
counts.put(word, count);
// 输出
collector.emit(new Values(word, String.valueOf(count)));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
} 2.6 WordCountToHBaseApp
/**
* 进行词频统计 并将统计结果存储到 HBase 中
*/
public class WordCountToHBaseApp {
private static final String DATA_SOURCE_SPOUT = "dataSourceSpout";
private static final String SPLIT_BOLT = "splitBolt";
private static final String COUNT_BOLT = "countBolt";
private static final String HBASE_BOLT = "hbaseBolt";
public static void main(String[] args) {
// storm 的配置
Config config = new Config();
// HBase 的配置
Map hbConf = new HashMap<>();
hbConf.put("hbase.rootdir", "hdfs://hadoop001:8020/hbase");
hbConf.put("hbase.zookeeper.quorum", "hadoop001:2181");
// 将 HBase 的配置传入 Storm 的配置中
config.put("hbase.conf", hbConf);
// 定义流数据与 HBase 中数据的映射
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("word")
.withColumnFields(new Fields("word","count"))
.withColumnFamily("info");
/*
* 给 HBaseBolt 传入表名、数据映射关系、和 HBase 的配置信息
* 表需要预先创建: create 'WordCount','info'
*/
HBaseBolt hbase = new HBaseBolt("WordCount", mapper)
.withConfigKey("hbase.conf");
// 构建 Topology
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(DATA_SOURCE_SPOUT, new DataSourceSpout(),1);
// split
builder.setBolt(SPLIT_BOLT, new SplitBolt(), 1).shuffleGrouping(DATA_SOURCE_SPOUT);
// count
builder.setBolt(COUNT_BOLT, new CountBolt(),1).shuffleGrouping(SPLIT_BOLT);
// save to HBase
builder.setBolt(HBASE_BOLT, hbase, 1).shuffleGrouping(COUNT_BOLT);
// 如果外部传参 cluster 则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("ClusterWordCountToRedisApp", config, builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWordCountToRedisApp",
config, builder.createTopology());
}
}
} 2.7 启动测试
可以用直接使用本地模式运行,也可以打包后提交到服务器集群运行。本仓库提供的源码默认采用 maven-shade-plugin 进行打包,打包命令如下:
# mvn clean package -D maven.test.skip=true运行后,数据会存储到 HBase 的 WordCount 表中。使用以下命令查看表的内容:
hbase > scan 'WordCount'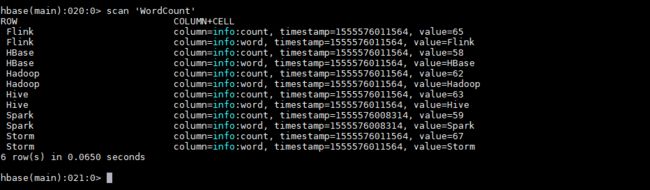
2.8 withCounterFields
在上面的用例中我们是手动编码来实现词频统计,并将最后的结果存储到 HBase 中。其实也可以在构建 SimpleHBaseMapper 的时候通过 withCounterFields 指定 count 字段,被指定的字段会自动进行累加操作,这样也可以实现词频统计。需要注意的是 withCounterFields 指定的字段必须是 Long 类型,不能是 String 类型。
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("word")
.withColumnFields(new Fields("word"))
.withCounterFields(new Fields("count"))
.withColumnFamily("cf");参考资料
- Apache HDFS Integration
- Apache HBase Integration
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南