感知机模型(perceptron)
文章目录
- 感知机(perceptron)
- 线性可分数据集
- 原始形式
- 统计学习方法三要素
- 学习流程
- 对偶形式
- 原理
- 学习流程
感知机(perceptron)
感知机模型属于二分类线性分类模型,属于判别模型和非概率模型。用一句话描述这个模型,就是找到一个超平面,把线性可分数据集分到超平面两侧。
线性可分数据集
存在某个超平面可以将数据集的正实例点和负的实例点完全正确的划分到超平面的两侧,这样的数据集称作线性可分数据集,否则是非线性可分数据集。感知机要求数据集是线性可分的。
原始形式
统计学习方法三要素
模型: y = s i g n ( ω T x + b ) y=sign(\omega ^{T}x+b) y=sign(ωTx+b)
策略: L ( ω , b ) = ∑ i ∈ m − y i ( ω T x i + b ) L(\omega,b)=\sum\limits_{i \in m}-y_{i}(\omega ^{T}x_{i}+b) L(ω,b)=i∈m∑−yi(ωTxi+b),m是误分类的数据集
学习:SGD
∂ L ∂ ω = ∑ i ∈ m − y i x i , ∂ L ∂ b = ∑ i ∈ m − y i \frac{\partial L}{\partial \omega}=\sum\limits_{i \in m}-y_{i}x_{i}, ~~~~~~\frac{\partial L}{\partial b}=\sum\limits_{i \in m}-y_{i} ∂ω∂L=i∈m∑−yixi, ∂b∂L=i∈m∑−yi
所以参数的更新过程为( η 为 学 习 率 \eta为学习率 η为学习率)
ω = ω − η ∂ L ∂ ω = ω + ∑ i ∈ m η y i x i \omega=\omega-\eta \frac{\partial L}{\partial \omega}=\omega+\sum\limits_{i \in m}\eta y_{i}x_{i} ω=ω−η∂ω∂L=ω+i∈m∑ηyixi
b = b − η ∂ L ∂ b = b + ∑ i ∈ m η y i b=b-\eta \frac{\partial L}{\partial b}=b+\sum\limits_{i \in m}\eta y_{i} b=b−η∂b∂L=b+i∈m∑ηyi
由于学习方法是随机梯度下降法,所以每次找到一个误分类的 ( x i , y i ) (x_{i},y_{i}) (xi,yi)即可。
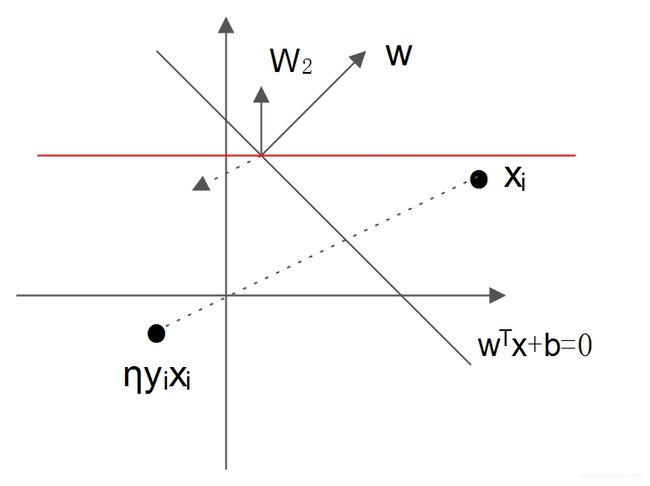
学习算法直观上可以看成,当被选择的实例点位于超平面错误的一侧,则调整 ω 与 b \omega与b ω与b,使得超平面向该误分类点一侧移动,减小该误分类点到超平面的距离,直至所有超平面都被正确分类。结合下图简单解释一下,假设目前的决策函数位置在 ω T x + b = 0 \omega^{T}x+b=0 ωTx+b=0处, x i x_{i} xi被误分类,由于其在 ω \omega ω指向一侧,所以目标函数把其分类为正(关于超平面知识看我写的SVM里面的超平面部分知识),实际 y i = − 1 y_{i}=-1 yi=−1,由于 η > 0 \eta>0 η>0, η y i x i \eta y_{i}x_{i} ηyixi是图上关于 x i x_{i} xi原点对称点的放缩,假设就在图上表示的点, ω \omega ω加上 η y i x i \eta y_{i}x_{i} ηyixi后, ω \omega ω方向变成 ω 2 \omega_{2} ω2方向, ω 2 \omega_{2} ω2表示的直线假设是图上红线表示的点,可见决策超平面在向着 x i x_{i} xi能被正确分类的方向转动。
值得一提的是,在构造感知机的损失函数时,最自然的选择是误分类点的总数,这样的话损失函数长这样 L ( ω , b ) = ∑ i ∈ m − y i s i g n ( ω T x i + b ) L(\omega, b)=\sum\limits_{i \in m}-y_{i}sign(\omega^{T}x_{i}+b) L(ω,b)=i∈m∑−yisign(ωTxi+b),这样的损失函数不是连续可导函数,所以损失函数选择为误分类点到超平面的总距离(在SVM中可知,这种距离称作函数距离),其对应绝对值损失函数。
由于学习算法可以采用不同的初值或选取不同的误分类点,最终的感知机模型可能不同。
学习流程
输入:训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) … ( x n , y n ) } , η ( 0 < η ≤ 1 ) , y i ∈ { − 1 , 1 } T=\{(x_{1},y_{1}),(x_{2},y_{2}),(x_{3},y_{3})\dots (x_{n},y_{n})\},\eta(0<\eta \leq 1),y_{i}\in \{-1,1\} T={(x1,y1),(x2,y2),(x3,y3)…(xn,yn)},η(0<η≤1),yi∈{−1,1}。
输出: ω , b \omega, b ω,b;决策函数 y = s i g n ( w T x + b ) y=sign(w^{T}x+b) y=sign(wTx+b)
执行流程:
- 初始化参数 ω 与 b \omega与b ω与b,一般初始化为0。
- 从训练集中找出一个点 ( x i , y i ) (x_{i},y{_i}) (xi,yi)。
- 如果该点是误分类的点,利用 ( x i , y i ) (x_{i},y{_i}) (xi,yi)与公式 ω = ω + η y i x i , b = b + η y i \omega = \omega + \eta y_{i}x_{i},b=b+\eta y_{i} ω=ω+ηyixi,b=b+ηyi更新参数 ω 与 b \omega与b ω与b。
- 重复执行2-3步骤,直到没有误分类的点。
伪代码:
def train(T,n): #T为数据集,n为步长
初始化w与b,一般w=0,b=0
do:
i = 0
do:
i += 1
y = sign(wT·xi+b)
while(yi·y<0 or i>len(T))
if i <= len(T):
w = w+nxiyi
b = b+nyi
while(i>len(T))
return w,b
对偶形式
原理
从 最 终 结 果 考 虑 ω 与 b 的 更 新 , 表 示 如 下 : 从最终结果考虑\omega与b的更新,表示如下: 从最终结果考虑ω与b的更新,表示如下:
ω = ω 初 始 化 + ∑ i = 1 n η n i y i x i = ω 初 始 化 + ∑ i = 1 n α i y i x i , n i 表 示 第 i 条 记 录 用 于 更 新 ω 与 b 次 数 。 \omega =\omega_{初始化}+\sum\limits_{i=1}^{n}\eta n_{i}y_{i}x_{i}=\omega_{初始化}+\sum\limits_{i=1}^{n}\alpha_{i}y_{i}x_{i},\\n_{i}表示第i条记录用于更新\omega与b次数。 ω=ω初始化+i=1∑nηniyixi=ω初始化+i=1∑nαiyixi,ni表示第i条记录用于更新ω与b次数。
b = b 初 始 化 + ∑ i = 1 n η n i y i = b 初 始 化 + ∑ i = 1 n α i y i , n i 表 示 第 i 条 记 录 用 于 更 新 ω 与 b 次 数 。 b=b_{初始化}+\sum\limits_{i=1}^{n}\eta n_{i}y_{i}=b_{初始化}+\sum\limits_{i=1}^{n}\alpha_{i}y_{i},n_{i}表示第i条记录用于更新\omega与b次数。 b=b初始化+i=1∑nηniyi=b初始化+i=1∑nαiyi,ni表示第i条记录用于更新ω与b次数。
决 策 函 数 可 以 变 成 y = s i g n ( ω T x + b ) = s i g n ( ∑ i = 1 n α i y i x i x + b ) , α i = η n i , n i 表 示 第 i 条 记 录 被 用 于 更 新 模 型 的 次 数 , 这 里 要 求 ω 与 b 为 零 初 始 化 。 决策函数可以变成y=sign(\omega^{T}x+b)=sign(\sum\limits_{i=1}^{n}\alpha_{i}y_{i}x_{i}x+b),\alpha_{i}=\eta n_{i},\\n_{i}表示第i条记录被用于更新模型的次数,这里要求\omega 与b为零初始化。 决策函数可以变成y=sign(ωTx+b)=sign(i=1∑nαiyixix+b),αi=ηni,ni表示第i条记录被用于更新模型的次数,这里要求ω与b为零初始化。
这 样 我 们 就 把 更 新 ω 与 b 变 为 更 新 α 与 b 。 这样我们就把更新\omega与b变为更新\alpha与b。 这样我们就把更新ω与b变为更新α与b。
学习流程
输入:训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) … ( x n , y n ) } , η ( 0 < η ≤ 1 ) , y j ∈ { − 1 , 1 } T=\{(x_{1},y_{1}),(x_{2},y_{2}),(x_{3},y_{3})\dots (x_{n},y_{n})\},\eta(0<\eta \leq 1),y_{j}\in \{-1,1\} T={(x1,y1),(x2,y2),(x3,y3)…(xn,yn)},η(0<η≤1),yj∈{−1,1}。
输出: α j , b \alpha_{j}, b αj,b;决策函数 y = s i g n ( ∑ j = 1 n α j y j x j x + b ) y=sign(\sum\limits_{j=1}^{n}\alpha_{j}y_{j}x_{j}x+b) y=sign(j=1∑nαjyjxjx+b)
执行流程
1. 初 始 化 α j = 0 , j = 1 … n , b = 0 。 初始化\alpha_{j}=0,j=1\dots n,b=0。 初始化αj=0,j=1…n,b=0。
2. 从 训 练 集 中 选 择 一 个 点 ( x i , y i ) 。 从训练集中选择一个点(x_{i},y_{i})。 从训练集中选择一个点(xi,yi)。
3. 如 果 该 点 是 误 分 类 的 点 , 则 更 新 α i = α i + η , b = b + η y i , 可 见 b 的 更 新 同 原 始 形 式 一 样 。 如果该点是误分类的点,则更新\alpha_{i}=\alpha_{i}+\eta,b=b+\eta y_{i},\\可见b的更新同原始形式一样。 如果该点是误分类的点,则更新αi=αi+η,b=b+ηyi,可见b的更新同原始形式一样。
4. 重 复 2 − 3 直 到 没 有 点 被 误 分 类 重复2-3直到没有点被误分类 重复2−3直到没有点被误分类。
由于在判定一个点是否是误分类的点时,会频繁用到内积 < x i , x j > <x_{i},x_{j}> <xi,xj>,所以可以构建一个矩阵保存内积结果,这个矩阵叫做Gram矩阵。
参考书籍:《统计学习方法》