深度强化学习(三):Policy Gradients
###一、Policy-based RL概述
####1.Policy-based RL起源
在学习Policy Gradiens(PG)之前,我们将强化学习的方法分成两类进行考虑:
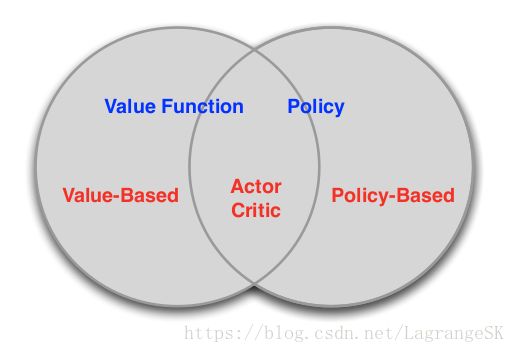
- 一类是value-based方法,需要计算价值函数(value function),根据自己认为的高价值选择行为(action)的方法,如Q Learning, sara, Deep Q Network(DQN)
- 另一类是policy-based方法,不需要计算value function,直接计算出随机策略的方法,如PG。
- 图中第三类方法结合了上述两者,此不详述。
在深度强化学习DQN中我们提到将深度学习和强化学习结合起来,用network近似了Q函数,从而泛化强化学习方法,使之可以更广泛的应用。DQN属于一种基于value-based方法的泛化,这类方法通常采用一个Function Approximator (FA)来近似value function,然后根据计算出的value function 在动作空间内选择action。他们通常存在以下问题:
- 这类方法通常会获得一个确定的策略(deterministic policy),但很多问题中的最优策略是随机策略(stochastic policy)。(如石头剪刀布游戏,如果确定的策略对应着总出石头,随机策略对应随机出石头、剪刀或布,那么随机策略更容易获胜)
- value function 的微小变化对策略的影响很大,可能直接决定了这个action是否被选取
- **在连续或高维度动作空间不适用。**因为这类算法的本质是连续化了value function,但动作空间仍然是离散的。对于连续动作空间问题,虽然可以将动作空间离散化处理,但离散间距的选取不易确定。过大的离散间距会导致算法取不到最优action,会在这附近徘徊,过小的离散间距会使得action的维度增大,会和高维度动作空间一样导致维度灾难,影响算法的速度。
那么我们很自然的联想到,既然Policy是关于状态量 s 和动作量a 的函数,是否可以直接用FA近似Policy?答案是肯定的,这就是Policy-based RL。
**Policy-based RL克服了上述问题,使得RL可以用于连续或高维度动作空间,且可以生成stochastic policy。**那么我们来看看他是如何做到的吧!
####2.Policy-based RL
这里引用Karpathy大神关于PG的小例子来说明Policy-based RL的工作过程。假设用Policy-based RL来玩 ATARI game (Pong!)游戏:让Policy-based RL操作一个拍子,维持不让小球掉下去的游戏。此处的state是每一帧的像素矩阵,action为(up or down), reward 为+1 (接球成功)和 -1 (没有接住球)。

那么可以分析其工作流程如下:

构造了一个策略神经网络(Policy Network),网络输入为像素矩阵(state), 输出为an action probability distribution π ( s ) \pi(s) π(s),此处为拍子向上运动(up) 的概率分布。实际的执行过程中,我们可以按照这个 distribution 来选择动作,或者 直接选择概率最大的那个 action。通过更新神经网络参数,增加表现好(取胜)的action出现的可能性,减小表现差(失败)的action出现的可能性。
那么如何判断生成的Policy π ( s ) \pi(s) π(s)是好是坏呢?
我们定义一个reward的期望值 J ( θ ) J(\theta) J(θ), 来表示所得策略的奖励,其中 θ \theta θ为泛化函数FA的参数,不同的 J ( θ ) J(\theta) J(θ)定义如下:

这样我们就量化了Policy的测评指标,可以看出Policy-based RL的本质是一个优化问题,需要最大化 J ( θ ) J(\theta) J(θ),但是直接确定 J ( θ ) J(\theta) J(θ)与 θ \theta θ的关系比较困难,可是我们可以让 J ( θ ) J(\theta) J(θ)朝着增大的方向前进。
有一种优化方法叫梯度下降法(Gradient descent)可以解决该问题,采用梯度下降法(Gradient descent)的Policy-based RL称之为Policy Grandients,下面我们详细叙述他的工作原理。
###二、Policy Gradients
####1、梯度下降法
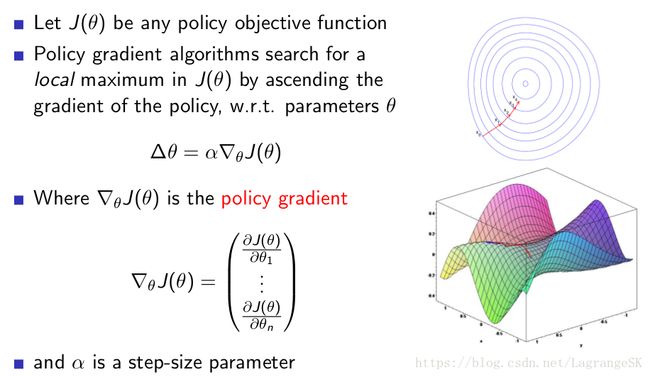
梯度下降算法背后的原理:目标函数 J ( θ ) J(\theta) J(θ) 关于参数 θ \theta θ 的梯度 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ) 是目标函数上升最快的方向。对于最小化优化问题,只需要将参数 θ \theta θ 沿着梯度相反的方向前进一个步长,就可以实现目标函数的下降。这个步长又称为学习速率 α \alpha α 。参数更新公式如下:
θ ← θ + Δ θ \theta \leftarrow \theta + \Delta\theta θ←θ+Δθ
其中 Δ θ \Delta\theta Δθ表达如下图所示:
####2.PG定理
那么问题的关键就转移到了如何求 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ),此处我们引入PG第一定理:
对任意马尔科夫过程,任意形式的 J ( θ ) J(\theta) J(θ)满足以下公式:
∂ J ( θ ) ∂ θ = ∑ s d π ( s ) ∑ a ∂ π ( s , a ) ∂ θ Q π ( s , a ) \frac{\partial J(\theta)}{\partial \theta}=\sum_{s}{d^{\pi}(s)}\sum_{a} \frac{\partial \pi (s, a)}{\partial \theta} Q^{\pi}(s, a) ∂θ∂J(θ)=∑sdπ(s)∑a∂θ∂π(s,a)Qπ(s,a)
由于:

将其带入第一定理可得:
∇ θ J ( θ ) = ∑ s d π ( s ) ∑ a π θ ( s , a ) ∇ θ l o g π θ ( s , a ) Q π ( s , a ) \nabla_\theta J(\theta)=\sum_{s}{d^{\pi}(s)}\sum_{a}\pi_\theta(s,a)\nabla_\theta log\pi_\theta(s,a) Q^{\pi}(s, a) ∇θJ(θ)=∑sdπ(s)∑aπθ(s,a)∇θlogπθ(s,a)Qπ(s,a)

####3.Monte-Carlo PG
本文讨论的PG算法为Monte-Carlo PG算法,即回合更新的PG算法,有如下假设:
- 采用随机梯度下降来更新网络参数
- 使用PG定理
- 使用一个回合(episode)的reward之和 v t v_t vt 代替 Q π ( s , a ) Q^{\pi}(s, a) Qπ(s,a)
那么可以得到算法的伪代码如下:

###四、扩展
前面说到直接确定 J ( θ ) J(\theta) J(θ)与 θ \theta θ的关系比较困难,但是在tensorflow中实现神经网络的参数更新是通过loss来的,因此如果在tensorflow中实现PG代码,我们有必要构造一个价值函数,指引着action概率的变化。
在强化学习中,通常我们判断动作好坏的依据为reward或一系列reward之和result。那么我们可以按照以下方向改变某个action出现的概率:
如果某一个action得到的reward多,那么我们就增大他出现的概率,反之减小他出现的概率。
当然,用reward来评判动作的好坏是不准确的,甚至用result来评判也是不准确的。毕竟任何一个reward,result的产生都依赖一系列的动作。但是这并不妨碍我们这样思考:
如果能够构造一个好的action评判指标,来判断一个动作的好与坏,那么我们就可以通过改变动作的出现概率来优化策略!
假设这个action的评判标准为 f ( s , a ) f(s,a) f(s,a),那么如何用他构造一个loss function 呢?
涉及神经网络参数更新,可以类比监督学习,首先需要明确强化学习与监督学习的区别与联系:1.不同于监督学习,强化学习的数据集没有标签,那么可以将此时采样的action作为一个伪标签,即假设这个行为是正确的。2.由于没有标签,所以这个action 不一定是正确的,因此可以通引入上文中提到的 f ( s , a ) f(s,a) f(s,a)来指导这个action的概率变化,表达形式如下:
J ( θ ) = ∑ l o g π θ ( s , a ) f ( s , a ) J(\theta) = \sum log\pi_\theta(s,a)f(s,a) J(θ)=∑logπθ(s,a)f(s,a)
其中, l o g π θ ( s , a ) log\pi_\theta(s,a) logπθ(s,a) 为对数概率分布。
和上文推导对比,发现微分一下就是上文结果。上文中,用 Q π ( s , a ) Q^{\pi}(s, a) Qπ(s,a)具体化了 f ( s , a ) f(s,a) f(s,a)。
###五、算法总结

Karpathy大神的PG说明
Policy gradient methods for reinforcement learning with function approximation.
David Silver 的 PG 课件
https://blog.csdn.net/amds123/article/details/70242042