FCN语义分割训练自己的数据(依据VOC2012数据集格式)
chapter 4 应用FCN训练自己的数据(以voc2012为模板)
step0.参考数据集需求
可用于FCN的完全VOC格式的数据组织结构模式:
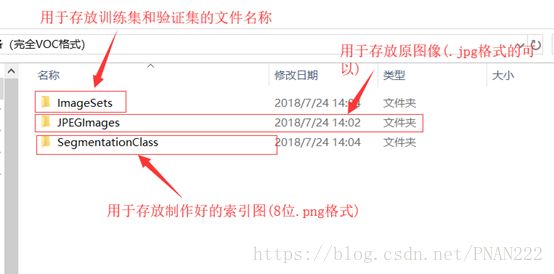
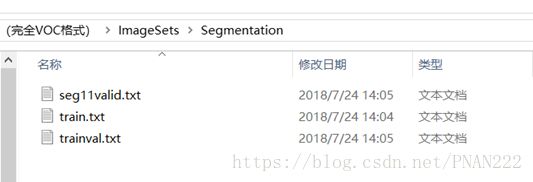
训练集和验证集可以按照8-2的方式进行安排。
VOC2012数据集共包含21个类别,其中包括背景类,则共包含20类事物。
step1.制作自己的数据
应用一个简化的方法,并不把像素级的labels做成.mat的形式,反倒是借助于索引图的格式,直接在载入图片的时候把颜色值作为标签载入,并把制作好的索引图当成labels。
制作过程:
制作自己的FCN数据流程:
- 应用labelme软件(安装使用过程参见安装文档)对图像数据进行标注,标注完毕后会生成.json文件。
- 针对.json文件,在终端输入指令:labelme_json_to_dataset 路径/文件名.json 即可生成dataset文件夹。
- 为文件夹下的label.png(目前开起来是全黑色)进行分配颜色(若类别数没有超过21类,则该步骤不需要操作)。
- 应用python的skimage库进行颜色填充,得到24位的着色后的RGB三通道图像,重命名为2018_000001.png(label)。
- //(已注释掉20190704)应用matlab将着色后的label(src/2018_000001.png)图像转为8位灰度图像,即可用label(dst/2018_000001.png)。
- (订正第5条20190704)应用matlab将着色后的label(src/2018_000001.png)RGB三通道图像转为8位彩色索引图像,即可用label(dst/2018_000001.png)。
a.jpg ---> a.json ---> a_json(dataset文件夹,其中包括:img.png(原图), label.png(标签图), label_viz.png(标签可视化后的图像), label_names.txt, info.yaml) ---> src/2018_000001.png(24) ---> dst/2018_000001.png(8)
小工具:制作mask语义级标签的工具labelme,开源代码链接为:https://github.com/wkentaro/labelme
(关于标注标签的拓展,https://blog.csdn.net/chaipp0607/article/details/79036312另附一个bounding box的工具,开源代码链接为:https://github.com/tzutalin/labelImg)
由于标注工作需要专家来进行标注,所以label最好是在window上能进行安装,并给非计算机领域的专家来使用,具体安装和使用说明可以参考如下代码,如需详细安装过程,可在下方留言或者私信。
conda create --name=labelme python=3.6
conda activate labelme
pip install pyqt5
conda install pillow=4.0.0
pip install labelme
首先,颜色填充代码如下,colorlabel.py文件可以在此处下载:https://github.com/hitzoro/FCN-ColorLabel
import colorlabel
import PIL.Image
import os
import numpy as np
from skimage import io,data,color
rootdir = 'D:/temppic/piczhongyaohuichuan/005zzy/'
dstpath = 'D:/temppic/piczhongyaohuichuan/005zzy/label24'
list = os.listdir(rootdir)
count = 114
for i in range(0,len(list)):
path = os.path.join(rootdir,list[i])
if(os.path.isdir(path) and 'json' in path):
img = PIL.Image.open(path+'/label.png')
#img.show()
#img = PIL.Image.open('D:/temppic/piczhongyaohuichuan/004ywz/42a_json/label.png')
label = np.array(img)
dst = colorlabel.label2rgb(label, bg_label=0, bg_color=(0, 0, 0))
# final = PIL.Image.fromarray(np.uint8(dst * 255))
# final.show()
# final.save('000001.png')
io.imsave(path+'/2018_'+str(count).zfill(6)+'.png', dst)
io.imsave(dstpath + '/2018_' + str(count).zfill(6) + '.png', dst)
count += 1
将填充后的label.png转为灰度图24位位图转8位位图,代码如下:
dirs=dir('src005zzy/*.png');
for n=1:numel(dirs)
strname=strcat('src005zzy/',dirs(n).name);
img=imread(strname);
[x,map]=rgb2ind(img,256);
newname=strcat('dst/',dirs(n).name);
imwrite(x,map,newname,'png');
endstep2.把制作好的数据集整合到指定目录下,附赠几个给文件重命名和制作txt文档的代码:
文件重命名:
# coding=utf-8
import os
path1 = 'D:/temppic/piczhongyaohuichuan/005zzy/datayuanyuan'
path2 = 'D:/temppic/piczhongyaohuichuan/005zzy/datayuan'
count = 114
for file in os.listdir(path1):
os.rename(os.path.join(path1, file), os.path.join(path2, "2018_"+str(count).zfill(6) + ".jpg"))
count += 1制作txt文档:
file_path = 'D:\temppic\data\full-VOC\JPEGImages\';% 图像文件夹路径
img_path_list = dir(strcat(file_path,'*.jpg'));%获取该文件夹中所有jpg格式的图像
img_num = length(img_path_list);%获取图像总数量
fid1=fopen('D:\temppic\data\full-VOC\ImageSets\Segmentation\trainval.txt','w');
fid2=fopen('D:\temppic\data\full-VOC\ImageSets\Segmentation\train.txt','w');
fid3=fopen('D:\temppic\data\full-VOC\ImageSets\Segmentation\seg11valid.txt','w');
if img_num > 0 %有满足条件的图像
for j = 1:img_num %逐一读取图像
image_name = img_path_list(j).name(1:end-4);% 图像名
%image = imread(strcat(file_path,image_name,'.jpg'));
fprintf(fid1,'%s\n',image_name);% 显示正在处理的图像名
%图像处理过程 省略
%imshow(image)
end
fclose(fid1);
for j = 1:round(img_num*0.8) %逐一读取图像 %因为是要按照8-2的方式来分训练集和验证集
image_name = img_path_list(j).name(1:end-4);% 图像名
%image = imread(strcat(file_path,image_name,'.jpg'));
fprintf(fid2,'%s\n',image_name);% 显示正在处理的图像名
%图像处理过程 省略
%imshow(image)
end
fclose(fid2);
for j = round(img_num*0.8)+1:img_num %逐一读取图像
image_name = img_path_list(j).name(1:end-4);% 图像名
%image = imread(strcat(file_path,image_name,'.jpg'));
fprintf(fid3,'%s\n',image_name);% 显示正在处理的图像名
%图像处理过程 省略
%imshow(image)
end
fclose(fid3);
end
step3. 按照上一章的运行步骤,把文件替换后即可以实现训练
如下图所示训练结果,因为数据集太小,结果不是很好,交并比只有0.534,还有待改善。
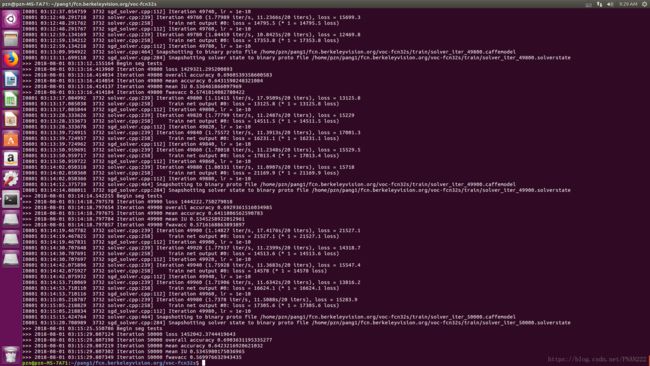
step4. 应用训练好的model,进行网络正向传播,得到结果
infer.py可参考:
import sys
sys.path.append('/home/pzn/caffe/python')
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import caffe
import vis
# the demo image is "2007_000129" from PASCAL VOC
# load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('../demo/teethyuan/47a.JPG')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1))
# load net
# net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST)
net = caffe.Net('../voc-fcn32s/deploy.prototxt', '../voc-fcn32s/train/solver_iter_50000.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score'].data[0].argmax(axis=0)
'''
#plt.imshow(out,cmap='gray');
plt.imshow(out)
#plt.show()
plt.axis('off')
plt.savefig('../demo/outputteeth/11a_op.png')
'''
# visualize segmentation in PASCAL VOC colors
voc_palette = vis.make_palette(3)
out_im = Image.fromarray(vis.color_seg(out, voc_palette))
out_im.save('../demo/outputteeth/47a_op.png')
masked_im = Image.fromarray(vis.vis_seg(im, out, voc_palette))
masked_im.save('../demo/outputteeth/47a_visualization.jpg')
'''
# visualize segmentation in PASCAL VOC colors
voc_palette = vis.make_palette(21)
out_im = Image.fromarray(vis.color_seg(out, voc_palette))
out_im.save('demo/output.png')
masked_im = Image.fromarray(vis.vis_seg(im, out, voc_palette))
masked_im.save('demo/visualization.jpg')
'''
'''
2012_000003
2012_000004
2012_000007
2012_000010
2012_000014
2012_000015
2012_000016
2012_000019
2012_000025
2012_000027
2009_002012
2011_002012
coast_bea1
coast_n286045
coast_nat1091
coast_natu975
forest_natc52
mountain_n213081
mountain_nat426
opencountry_land660
street_par151
street_urb885
tallbuilding_art1004
'''附加一个labelme批量生成json文件(从.json变为jsonset)的代码:
修改文件路径为:D:\Users\Pangzhennan\Anaconda3\envs\labelme\Lib\site-packages\labelme\cli
下的json_to_dataset.py文件。
源文件代码为:
import argparse
import base64
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
data = json.load(open(json_file))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(json_file), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png'))
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()修改为:
# -*- coding: utf-8 -*-
import argparse
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
import base64
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
# 该段代码在此处无意义
'''
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
'''
list = os.listdir(json_file)
for i in range(0, len(list)):
path = os.path.join(json_file, list[i])
if os.path.isfile(path):
data = json.load(open(path))
img = utils.img_b64_to_array(data['imageData'])
lbl, lbl_names = utils.labelme_shapes_to_label(img.shape, data['shapes'])
captions = ['%d: %s' % (l, name) for l, name in enumerate(lbl_names)]
lbl_viz = utils.draw_label(lbl, img, captions)
out_dir = osp.basename(list[i]).replace('.', '_')
out_dir = osp.join(osp.dirname(list[i]), out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
PIL.Image.fromarray(lbl).save(osp.join(out_dir, 'label.png'))
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in lbl_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=lbl_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
批量运行labelme中.json文件生成jsonset的dos命令代码:
labelme_json_to_dataset D:\temppic\piczhongyaohuichuan\009lc\json
特别注意,要在运行时保证运行所在路径为保存jsonset的路径,否则生成的jsonset文件会被保存到默认路径下。
Chapter 5 绘制loss曲线