YoLo算法分析
1- Yolo算法原理
1.1 简介
论文地址:https://pjreddie.com/publications/
源码地址:https://github.com/pjreddie/darknet
[文末附opencv示例yolo-v2版本示例代码]
Yolo(You Only Look Once)算法将目标检测作为回归问题来进行求解,能够在单个神经网络中直接从原始图像上预测物体位置边界框(bounding boxes)和类别(class probabilities)的输出,是单一的(端到端)End-to-End网络。经典的目标检测算法RCNN/Fast-RCNN框架主要分为two steps:1首先通过选择搜索(Selective Search)来获取候选框(Regions Proposals) 2 其次对获取的所有候选框做分类(Box Classifier)。
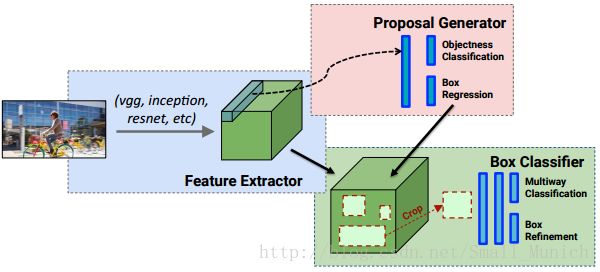

Yolo将目标检测的单独组件集成到单个神经网络中,yolo网络使用整个图像的特征来预测每个边界框,同时它还可以预测整张图像中的所有类别的所有边界框。因此yolo网络能够全面的推断和预测整张图像的所有目标,实现端到端的训练和实时检测。yolo检测系统框架分为three Steps:
1 首先对输入图像的大小调整为448 X 448;
2 图像上进行卷积神经网络计算;
3 通过模型的置信度对所得到检测进行(非极大值抑制)阈值处理。
1.2 统一检测
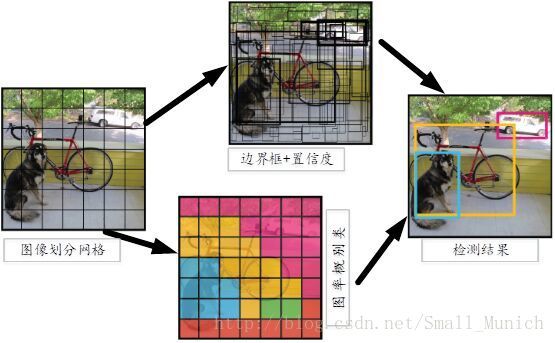
Yolo系统首先将图像分成S X S网格,每个网格单元预测B个候选框,这些边界框的置信度以及C个类别的概率,预测被编码为S X S X (B*5 + C)的张量。
这里我们首先解释一下,yolo为什么经过卷积网络能够检测物体的位置与类别信息:
示例:输入图像大小假设为77,使用大小为11的卷积核对输入图像进行卷积,经过卷积后的图如下所示:


如上图4所示,经过卷积后的图像每个网格赋予不同类别的颜色,每个网格判决类别信息主要通过训练经过标定后的图像集物体通过卷积网络训练出的模型来进行预测判别。那么我们可以得出:卷积核与图像卷积出来了目标的类别信息。 Yolo系统将每个网格单元预测B个边界框和置信度参数,置信度参数反应训练出的模型是否包含目标概率以及预测边界框位置信息的准确程度。Yolo论文中将置信度定义为:
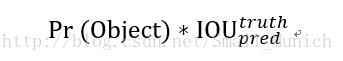
Yolo对每个边界框预测5个参数:中心坐标信息(x, y) 、目标物体宽与高(w, h)、置信度。每个网格单元同时预测目标的C个条件类别概率Pr(Class|Object),这些概率以包含目标的网格单元为条件。每个网格单元只预测一组概率,并不管边界框的数量B是多少。因此,在测试(预测)阶段,每个box通过类别的概率和box的置信度相乘来获取某一类别的置信分数:
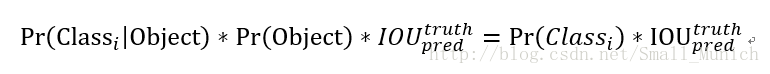
1.3 网络设计
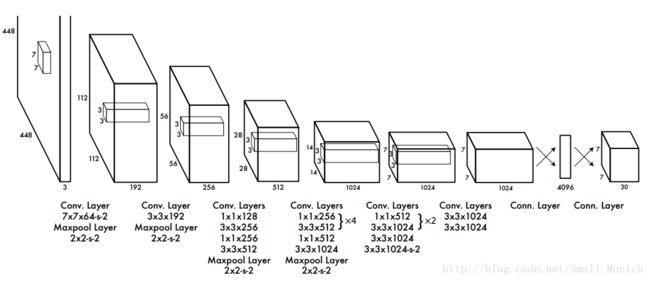
1.4 训练
1.4.1 训练策略
使用ImageNet数据集上进行训练,预训练模块采用yolo网络架构的前20个卷积层+平均池化层+全连接层。训练时长大约一周并且在ImageNet2012上验证集上获取88%的top-5准确率,与Caffe下的GoogleNet性能相当。
训练出的模型来进行检测之前,再添加4个卷积层+2个全连接层,随机初始化权重参数,输入图像分辨率从224224提升至448448。通过输入图像宽高来规范边界框的宽高,归一化至0-1之间。使用Leaky Relu函数作为非线性激活函数。
同时yolo采用dropout层的ratio=0.5的比率(防止层与层之间相互适应)和大量的数据增强(引入高达原始图像20%大小随机缩放和转换,HSV空间中使用1.5的因子来调整图像的曝光与饱和度)方式来降低过拟合的风险。
1.4.2 损失函数
Yolo文章作者对模型优化选取容易优化的平方和误差方式,公式如下:


模型采用平方和误差损失函数来优化有以下不足:
1 分类误差与定位误差如果权重系数相同并不是很合理:定位误差参数8维,分类误差参数20维。(因此为了更加重视坐标的预测,给定位误差损失函数前面添加权重系数 λ c o o r d λ_{coord} λcoord=5)。

2 每张图像中,许多网格单元不包含任何的目标对象,如果直接将这些单元格的置信度分数推向零,通常会压倒包含目标的单元格梯度,可能会导致模型不稳定,以至于使训练早期发散。(因此对于没有目标的边界框的置信度,赋予小的损失权重 λ n o o b λ_{noob} λnoob=0.5,对于有目标的边界框损失权重参数设置为1,类别参数权重设置为1)。
3 对于不同大小的边界框预测中,大的边界框(bounding boxes)小偏差与小的边界框小偏差的IoU影响程度不同,但是采用平方和误差是相同的加权误差方式。为了降低这部分的干扰,作者采取直接预测边界框的宽度与高度的平方根(然而并不是根本解决方法)。
1.5 预测推断
Yolo模型在预测测试图像的检测阶段只需要一次网络评估,在pasvoc上面每张图像预测98个边界框和每个边界框的类别概率。yolo网络设计强化了边界框预测的空间多样性,网络只能为每个目标预测一个边界框。但是,较大的目标物体或者靠近多网格单元的目标会被多个网格单元很好的定位,这种情况下采用非极大值抑制的方法来修正这些多重检测。对于R-CNN与DPM,非极大值抑制能够提升2-3%的mAP。
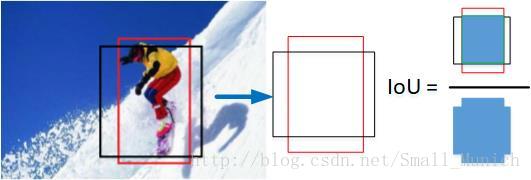
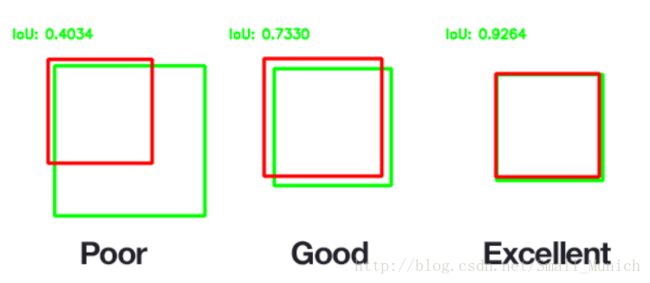
候选框交集IoU(Intersect over Union)和非极大值抑制(Non-Maxima Suppresion)算法,评估真实目标边界框与预测目标的边界框的IoU:

2-Yolo算法优缺点
优点:
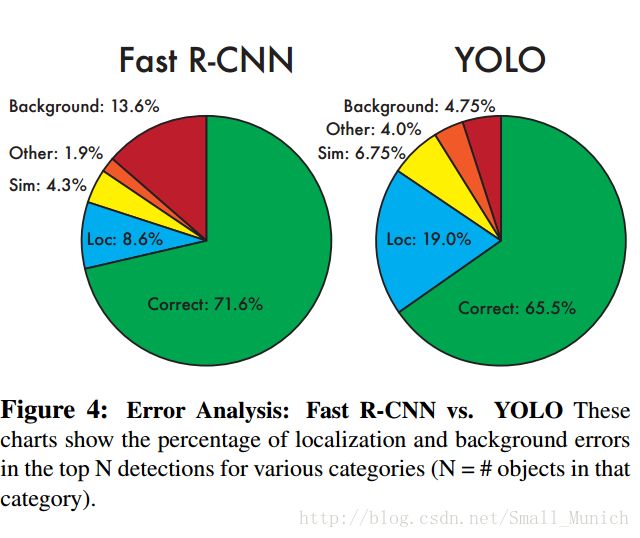
1 Yolo检测速度快,能够实时处理流媒体视频。(因为Yolo框架把目标检测视为回归问题,流程不像RCNN/Fast-RCNN那样复杂)
2 Yolo较RCNN/Fast-RCNN等算法相比,背景误检数量少了一半。(因为Yolo算法是对输入图像进行全局处理,与滑动窗口/区域提取方式不同,yolo能够有效获取上下文信息)
3 Yolo通用性强(泛化能力好)
缺点:
1 Yolo算法对检测到的物体定位精准性较差。(因为损失函数的问题,定位误差是影响检测效果的主要原因)。
2 Yolo算法对小目标、密集出现的物体(鸟群)检测较差。(因为Yolo框架设计对边界框[Bounding Boxes]强加了空间约束,每个格子最多只能检测一个(即多个小物体在一个格子中只能够检测出一个))。
3 Yolo算法召回率较低。
4 Yolo算法在同一类物体出现的新的不常见长宽比泛化能力偏弱。
3- Yolo算法实验结果
图片目标检测结果:

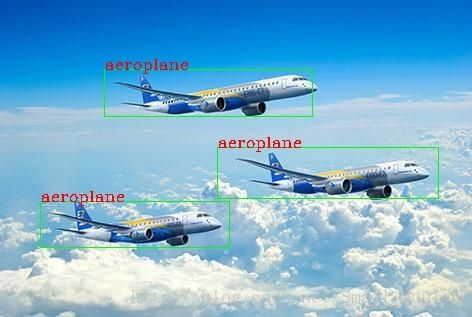

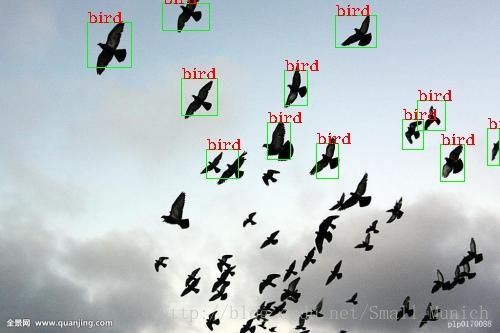
视频目标追踪显示:
奈何CSDN插入视频失败,暂时给个链接…
http://v.youku.com/v_show/id_XMzQ1MTgzMzAxMg==.html?spm=a2hzp.8244740.0.0
代码下载地址
[opencv-yolo_v2示例百度网盘]
链接:https://pan.baidu.com/s/14PiN0cZK9qUDjeTwsPM3vQ 密码:22yj
(opencv读取模型目前支持yolo_v2版本 .cfg .weights文件在yolo作者官网下载后放置工程data/yolov2文件夹下)
参考博客
https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/content/single-shot-detectors/yolo.html
https://zhuanlan.zhihu.com/p/25236464
https://zhuanlan.zhihu.com/p/25045711