顶级峰会 | 腾讯FPGA团队亮相FPGA2018

FPGA、FPL、FCCM和FPT并称FPGA领域四大顶级会议。其中,FPGA会议是FPGA领域最重要的顶级会议,旨在展现与FPGA技术相关所有领域的最新进展,如基本逻辑电路和架构、计算机辅助设计、高层次综合、工具和模型、处理器和系统、测试方法、应用开发等。 2月25-27日,FPGA 2018依旧在美国加州的Monterey召开,今年是第26届。在本次会议中,共录用26篇long paper,6篇short paper,以及32篇poster。在提交论文的专题应用中,Deep Learning架构占据了最高比例,其次是HLS(High LevelSynthesis)和CAD(Computer- Aided Design)。

图1 FPGA 2018现场盛况
在FPGA2018上,腾讯FPGA团队首次在学术界亮相,分享了FPGA在腾讯数据中心应用的最新进展和于潇宇博士的科研成果,下面就分享内容、会议感受与深度学习构架方向的新进展,分别介绍。

腾讯FPGA在数据中心的应用方案主要包括腾讯云FPGA平台,深度学习FPGA极速推断平台,以及基因计算行业方案。
腾讯云FPGA平台 相比于专用ASIC,FPGA的可编程能力可提供更高的灵活性,可为特定应用提供专属的加速能力。对此,我们在腾讯云推出FPGA硬件能力的同时,提供FaaS(FPGA as a service)方案,以及HDK和SDK,包括硬件侧完善的静态区域设计,软件侧丰富的API接口,从而简化FPGA开发者的工作使其可以专注于加速算法设计。同时,我们也联合合作伙伴,开放针对垂直领域的行业加速方案,如深度学习、基因计算、图像和视频处理等。
深度学习FPGA极速推断平台 图像和视频媒体是社交领域的核心内容,在我们数据中心任务中占据相当的比例。对于针对图像的CNN网络,我们主要解决一下三个问题:
1、不同模型对基本运算的吞吐需求存在差异。我们使用AccLib结合吞吐可配置的基本算子构架,实现针对每个CNN模型的高度定制,达到极致性能;
2、模型更新速度快,应用中也存在大量自定义模型。对此,基于AccLib的方式,我们已提供GoogleNet/VGG/Resnet/Alexnet/ShuffleNet/MobileNet/Yolo等典型模型的加速方案,而对于自定义模型可在一周内实现快速迭代与部署;
3、基于数据复用、指令设计和任务并行的优化。
上述平台已在数据中心服务于近10亿用户的应用。在KU115平台上,实现略高于P4的吞吐,并将延迟降低至P4的1/40。
基因计算二代基因测序可用来预测疾病,随着成本不断降低和数据量的爆发,数据分析和计算成为瓶颈。对此,我们推出了基于腾讯极光异构系统的加速方案,采用众核阵列的极光构架,将全基因组分析从30小时缩短为2.8小时,实现高于10倍的加速比。
在Poster的展示中,腾讯在数据中心的FPGA应用受到了UCLA、Imperial College London、USYD等学术界学者和Microsoft、Intel、Xilinx、Alibaba等工业界专家的关注。

图2 于潇宇博士在大会现场与参会学者交流

图3 于潇宇(中),Eric S. Chung(左,微软Senior Researcher)与Song Han(右,MIT Assi Prof)

背景:近期的视觉任务趋向于更高的精度与更低的延迟,要求视觉感知端具备更高的分辨率与帧频,如无人驾驶、姿态捕捉、虚拟现实、导航等。高速成像研究领域,性能不断刷新,灰度CMOS传感器已可实现5Gpixel/秒,等价于1080p分辨率下每秒2411帧的吞吐能力,但由于缺乏相应的处理架构,仅能用于图像记录。本文以目标检测为例对基于超高速相机实时运算的加速器构架进行讨论。
方法:采用无帧缓存的全流水设计,采用形如金字塔的二维处理节点阵列结合一维标签计算阵列,解决串行多任务执行中的顺序依赖问题,将高速图像的数据流转化为前景特征数据流,实现图像传输、连通域标记、特征提取的任务并行;通过二维金字塔节点阵列的专属架构,解决高速相机传输中,同周期到达的多像素在并行计算中的数据依赖问题,如图4所示。
结论:通过对高速摄像机实时运算的定制构架讨论,在目标检测中实现处理耗时小于成像耗时的帧驱动运算模式(Imager-driven processing mode),在0.8Gpixel/sec (2320×1726 at 192FPS)高速数据流下实现目标检测,图像传输结束至结果输出的处理延迟小于1us。
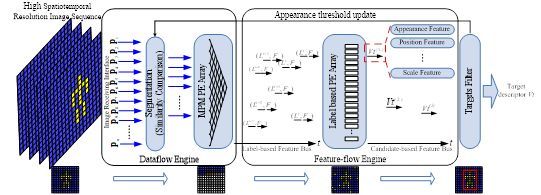
图4 基于高速数据量的目标检测处理框架
本次FPGA 2018中包含了两个大的主题,即深度学习和HLS工具优化。
无论从Session数量,还是论文投稿和录用数量,深度学习已成为FPGA学术界的最时尚的话题。在16年,还与OpenCL合并为一个Session,在17年和18年已占据了2个Session。各大高校的学者们已经普遍感受到了压力,经过近几年的积累,构架层面的优化已触及瓶颈。要实现更好的性能与更低的能耗比,需要算法和架构的联合优化能力。本届大会在深度学习方面的成果主要体现为三方面:更依赖于模型压缩,FFT、Winograd等成为常规优化手段,更注重任务和负载的均衡。
在上一节的FPGA大会上,Song Han通过模型剪枝与稀疏化将模型压缩到原本的1/10,那么是否还有其他方法实现模型压缩和高效计算呢?下面两篇论文中的方法给出了答案。
论文1:C-LSTM: Enabling Efficient LSTMusing Structured Compression Techniques on FPGAs[1]
本文通过块内循环的方式,如图5所示,结合重训练,将权值矩阵从O(k2)压缩到O(k),并结合FFT进一步降低计算复杂度,从而实现18.8倍的性能提升和33.5倍的能效提升。
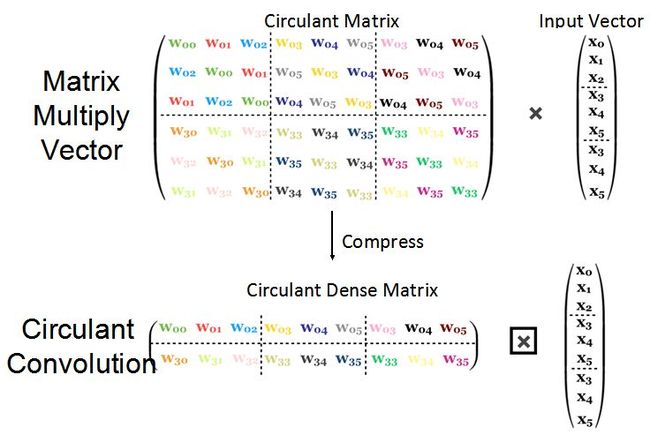
图5 块内循环的权值矩阵压缩方式,例如将3*3的权值子阵借助循环移位展开的方式,压缩为1*3的权值子阵,从而降低带宽瓶颈。
论文2 :DeltaRNN: A Power-efficient Recurrent Neural NetworkAccelerator[2]
Song Han的论文中是针对冗余的权值进行剪枝,那么时间序列中的状态是否存在冗余呢?本文提出了,只有在神经元当前输入的激励与上一次激励的变化超过一定阈值时,才进行计算并更新神经元的输出,这种方式同样减少了参与计算的权值矩阵,从而降低了带宽压力,如图6所示,实现了1.2Tops/s的吞吐和164Gops/W的能效。
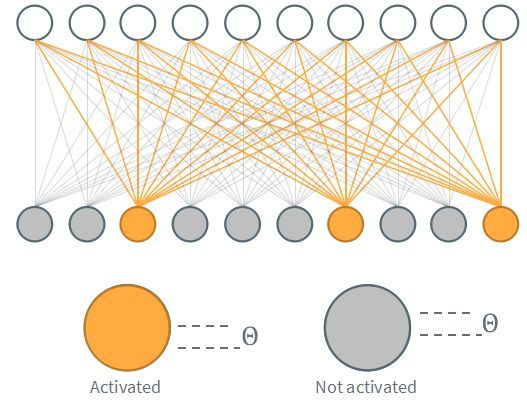
图6 忽略变化低于阈值的输入,从而降低计算量
此外,在任务和负载均衡方面,以下两篇论文分别对基于FFT的负载均衡与CPU+FPGA间的负载均衡进行讨论,可详见:
A Framework for Generating High ThroughputCNN Implementations on FPGAs[3]
A Customizable Matrix MultiplicationFramework for the Intel HARPv2 Xeon+FPGA Platform - A Deep Learning Case Study[4]
在HLS方面,FPGA是否能直接面对毫无硬件经验的软件工程师,是影响FPGA市场规模的关键因素,而这正是HLS的价值所在。鉴于其强大的快速开发优势,学术界已有超过50%的学者使用HLS。在本次大会中,针对HLS生成代码的性能、资源占用、易用性等问题,分别从多设计融合与编译时间优化、存储器优化、降低操作依赖和延迟、HLS设计debug等方面进行了讨论。
FPGA2018会议论文演讲ppt下载地址为:http://www.isfpga.org/program.html
[1] Shuo Wang,Zhe Li, Caiwen Ding, etc. C-LSTM: Enabling Efficient LSTM using StructuredCompression Techniques on FPGAs[C]. 26th ACM/SIGDA International Symposium onField-Programmable Gate Arrays, 2018.
[2] Chang Gao,Daniel Neil, Enea Ceolini, etc. DeltaRNN: A Power-efficient Recurrent Neural Network Accelerator[C]. 26th ACM/SIGDA International Symposium on Field-ProgrammableGate Arrays, 2018.
[3] HanqingZeng, Ren Chen, Chi Zhang, etc. A Framework for Generating High Throughput CNNImplementations on FPGAs[C]. 26th ACM/SIGDA International Symposium onField-Programmable Gate Arrays, 2018.
[4] DuncanMoss, Srivatsan Krishnan, Eriko Nurvitadhi, etc. A Customizable MatrixMultiplication Framework for the Intel HARPv2 Xeon+FPGA Platform - A DeepLearning Case Study[C]. 26th ACM/SIGDA International Symposium onField-Programmable Gate Arrays, 2018.
