深度学习---目标检测理论笔记
主要内容来自于对 “专知深度学习-高君宇” 教学资料的梳理笔记 和 来自互联网知识的辅助理解,感谢。
目标检测 就是在一张图片中找到所有的物体并且给出其类别和边框(bounding box),如图。

早期的目标检测有很多模型,典型的有基于部件的模型(DPM),Pedro F在2010年提出来的利用HOG对多精度下的图片进行特征提取,然后将特征转换成响应信号,进行响应集成,最终获得目标检测框。
HOG:方向梯度直方图,常用于图像特征提取(与LBP,Harr并称图像特征提取三大法宝,哈哈),经常配合SVM使用解决图像识别问题。有几个博客写的很详细:
https://www.cnblogs.com/zhehan54/p/6723956.html
https://blog.csdn.net/coming_is_winter/article/details/72850511
随着科技的发展,图片的获取变得便捷,数据量的大幅上升,在数据驱动下,目标检测的方法逐渐向深度学习神经网络方向偏移。
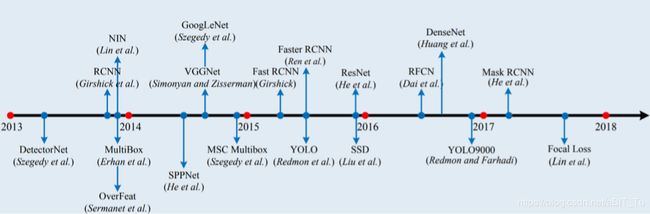
目标检测仍旧存在几个难点:1)精度;2)图片内容日益复杂,需要测试的位置增加;3)需要检测的目标增加。
以上就是概述部分,下面是详细讲解。
名词了解:
1)评价标准:召回率,准确率,交并比,平均准确率,详细解释可以查看我的往期博客。
2)滑动窗口(sliding window)
3)难样本挖掘(Hard negative mining):给难分的负样本更多关照(权重)。
4)非极大值抑制(Non-maximum suppression):将与指定框overlap过高的框移除。
5)边界框回归:对目标候选进行精化,减少框内无关背景。
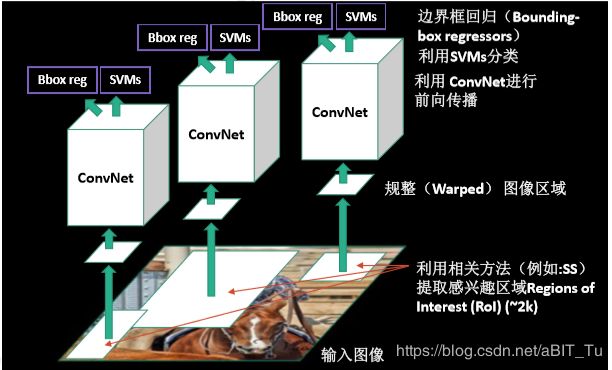
两阶段目标检测方法:产生目标候选->分类 http://arxiv.org/abs/1311.2524 ,
R-CNN,将特征提取(CNN)和分类(SVM)分为两个步骤完成。
基本框架如图,

SPP-net,https://arxiv.org/abs/1406.4729
改进:多尺度训练,共享整张图片(特征提取部分不同于R-CNN的地方),对形变鲁棒。
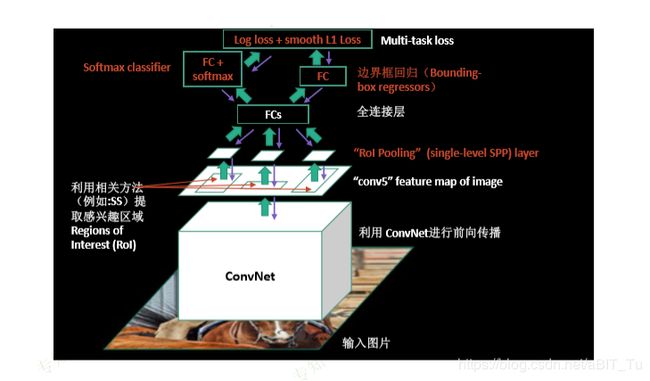
Fast R-CNN, https://arxiv.org/abs/1504.08083

Faster R-CNN, https://arxiv.org/pdf/1506.01497.pdf
RFCN, https://arxiv.org/abs/1605.06409
几种方法对比(Liu, Li, Wanli Ouyang, Xiaogang Wang, Paul Fieguth, Jie Chen, Xinwang Liu, and Matti Pietikäinen. "Deep learning for generic object detection: A survey." arXiv preprint arXiv:1809.02165 (2018).)

两阶段方法都需要经过目标候选和分类两个阶段,计算复杂度高,不利于实时性。
单阶段目标检测算法
YOLO,https://arxiv.org/abs/1803.07113
划分网格,检测每个网格中目标存在的概率,每个网格预测是某一类别的条件概率(将第二阶段加入进来了)

未完待续。。。