QoS的基本原理
1 前言
QoS(Quality of Service)是服务质量的简称。对于网络业务来说,服务质量包括哪些方面呢?从传统意义上来讲,无非就是传输的带宽、传送的时延、数据的丢包率等,而提高服务质量无非也就是保证传输的带宽,降低传送的时延,降低数据的丢包率以及时延抖动等。广义上讲,服务质量涉及网络应用的方方面面,只要是对网络应用有利的措施,其实都是在提高服务质量。因此,从这个意义上来说,防火墙、策略路由、快速转发等也都是提高网络业务服务质量的措施之一。
服务质量相对网络业务而言,在保证某类业务服务质量的同时,可能就是在损害其它业务的服务质量。因为网络资源总是有限的,只要存在抢夺网络资源的情况,就会出现服务质量的要求。比如,网络总带宽为100Mbps,而BT下载占用了90Mbps,其他业务就只能占用剩下的10Mbps。而如果限制BT下载占用的最大带宽为50Mbps,也就提高了其他业务的服务质量,使其他业务能够占用最少50Mbps的带宽,但这是在损害BT业务的服务质量为前提的。
2 QoS模型
网络中的通信都是由各种应用流组成的,这些应用对网络服务和性能的要求各不相同,比如FTP下载业务希望能获取尽量多的带宽,而VoIP语音业务则希望能保证尽量少的延迟和抖动等。但是所有这些应用的特殊要求又取决于网络所能提供的QoS能力,根据网络对应用的控制能力的不同,可以把网络的QoS能力分为三种模型:
2.1 Best Effort模型
Best Effort(尽力而为)模型是最简单的服务模型,应用程序可以在任何时候,发出任意数量的报文,网络尽最大的可能性来发送报文,对带宽、时延、抖动和可靠性等不提供任何保证。
Best Effort是Internet的缺省服务模型,通过FIFO(First In First Out,先进先出)队列来实现。
尽力而为的服务实质上并不属于QoS的范畴,因为在转发尽力而为的通信时,并没有提供任何服务或转发保证。
2.2 DiffServ模型
DiffServ(Differentiated Service,区分服务)模型由RFC2475定义,在区分服务中,根据服务要求对不同业务的数据进行分类,对报文按类进行优先级标记,然后有差别地提供服务。
区分服务一般用来为一些重要的应用提供端到端的QoS,它通过下列技术来实现:
1)流量标记与控制技术:它根据报文的CoS(Class of Service,服务等级)域、ToS域(对于IP报文是指IP优先级或者DSCP)、IP报文的五元组(协议、源地址、目的地址、源端口号、目的端口号)等信息进行报文分类,完成报文的标记和流量监管。目前实现流量监管技术多采用令牌桶机制。
2)拥塞管理与拥塞避免技术:WRED、PQ、CQ、WFQ、CBQ等队列技术对拥塞的报文进行缓存和调度,实现拥塞管理与拥塞避免。
上述这些技术的主要实现原理将在下文的QoS基本原理中进行重点介绍。
2.3 IntServ模型
IntServ(Integrated Service,综合服务)模型由RFC1633定义,在这种模型中,节点在发送报文前,需要向网络申请资源预留,确保网络能够满足数据流的特定服务要求。
IntServ可以提供保证服务和负载控制服务两种服务,保证服务提供保证的延迟和带宽来满足应用程序的要求;负载控制服务保证即使在网络过载的情况下,也能对报文提供与网络未过载时类似的服务。
在IntServ模型中,网络资源的申请是通过信令来完成的,应用程序首先通知网络它自己的流量参数和需要的特定服务质量请求,包括带宽、时延等,应用程序一般在收到网络的确认信息,即确认网络已经为这个应用程序的报文预留了资源后,才开始发送报文。同时应用程序发出的报文应该控制在流量参数描述的范围以内。负责完成保证服务的信令为RSVP(Resource Reservation Protocol,资源预留协议),它通知网络设备应用程序的QoS需求。RSVP是在应用程序开始发送报文之前来为该应用申请网络资源的,所以是带外信令。
保证服务要求为单个流预先保留所有连接路径上的网络资源,而当前在Internet主干网络上有着成千上万条应用流,保证服务如果要为每一条流提供QoS服务就变得不可想象了。因此,IntServ模型很难独立应用于大规模的网络,目前主要与MPLS TE(Traffic Engineering,流量工程)结合使用。
3 QoS基本原理
3.1 流量分类与标记
流量分类,就是将流量划分为多个优先级或多个服务类,如使用以太网帧中802.1Q头保留的User Priority(用户优先级)字段标记服务级别,可以将以太网帧最多分成23 = 8类;使用IP报文头的ToS(Type of service,服务类型)字段的前三位(即IP优先级)来标记报文,可以将报文最多分成23 = 8类;使用DSCP(Differentiated Services Codepoint,区分服务编码点,ToS域的前6位),则最多可分成26 = 64类。在报文分类后,就可以将其它的QoS特性应用到不同的分类,实现基于类的拥塞管理、流量整形等。
对于MPLS网络报文,则一般是根据MPLS报文中的EXP域进行处理。EXP域包括3位,虽然RFC 3032把它叫做实验域,但它通常作为MPLS报文的CoS域,与IP网络的ToS或DSCP域等效。
对于流量的分类,上面提到的关于以太网帧的Cos域、IP报文的ToS域等与MPLS报文的EXP域等仅是分类的一种情况,其实几乎可以对报文的任何信息段进行分类,比如也可以根据源IP地址、目的IP地址、源端口号、目的端口号、协议ID等进行流量的分类。
虽然流量分类几乎可以根据报文的任何字段进行,但是流量分类标记则一般只对802.1Q 以太网帧的CoS域、IP报文的ToS域、MPLS报文的EXP域进行标记。流量的标记主要的目的就是让其他处理此报文的应用系统或设备知道该报文的类别,并根据这种类别对报文进行一些事先约定了的处理。
例如,在网络的边界做如下分类和标记:
1)所有VoIP数据报文聚合为EF业务类,将报文的IP优先级标记为5,或者将DSCP值标记为EF;
2)所有VoIP控制报文聚合AF业务类,将报文的IP优先级标记为4,或者将DSCP值标记为AF31。
当报文在网络边界被标记分类之后,在网络的中间节点,就可以根据标记,对不同类别的流量给予差别服务了。例如:对上述例子中的EF类业务保证时延和减少抖动,同时进行流量监管;对AF业务类在网络拥塞时仍然保证一定的带宽,等等。
3.2 拥塞管理技术原理
3.2.1 拥塞管理基本概念
在计算机数据通信中,通信信道是被多个计算机共享的,并且,广域网的带宽通常要比局域网的带宽小,这样,当一个局域网的计算机向另一个局域网的计算机发送数据时,由于广域网的带宽小于局域网的带宽,数据将不可能按局域网发送的速度在广域网上传输。此时,处在局域网和广域网之间的路由器将不能发送一些报文,即网络发生了拥塞。
如下图所示,当公司分支1向公司总部以100M的速度发送数据时,将会使Router2的串口S0/1发生拥塞。
图1 实际应用中的拥塞实例
拥塞管理是指网络在发生拥塞时,如何进行管理和控制。处理的方法是使用队列技术。将所有要从一个接口发出的报文进入多个队列,按照各个队列的优先级进行处理。不同的队列算法用来解决不同的问题,并产生不同的效果。常用的队列技术有FIFO、PQ、CQ、WFQ、CBWFQ等,下文逐一介绍这些常用队列技术的基本原理。
3.2.2 FIFO队列原理简述
FIFO(First In First Out,先进先出)队列示意图如下所示:
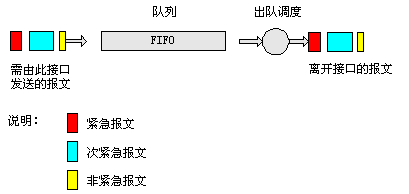
图2 FIFO队列示意图
FIFO队列不对报文进行分类,当报文进入接口的速度大于接口能发送的速度时,FIFO按报文到达接口的先后顺序让报文进入队列,同时,FIFO在队列的出口让报文按进队的顺序出队,先进的报文将先出队,后进的报文将后出队。
FIFO队列具有处理简单,开销小的优点。但FIFO不区分报文类型,采用尽力而为的转发模式,使对时间敏感的实时应用(如VOIP)的延迟得不到保证,关键业务的带宽也不能得到保证。
3.2.3 PQ原理简述
PQ(Priority Queuing,优先队列)示意图如下所示:
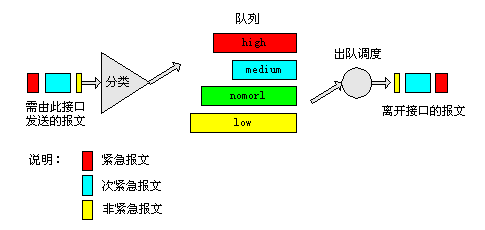
图3 PQ队列示意图
PQ队列是针对关键业务应用设计的。关键业务有一个重要特点,需要在拥塞发生时要求优先获得服务以减少响应的延迟。PQ可以根据网络协议(如IP、IPX)、数据流入接口、报文长短、IP报文的ToS、五元组(协议ID、源IP地址、目的IP地址、源端口号、目的端口号)等条件进行分类,对于MPLS网络,则根据MPLS报文EXP域值进行分类。最终将所有报文分成最多4类,分别属于PQ的4个队列中的一个,然后,按报文所属类别将报文送入相应的队列。
PQ的4个队列分别为高优先队列、中优先队列、正常优先队列和低优先队列,它们的优先级依次降低。在报文出队的时候,PQ首先让高优先队列中的报文出队并发送,直到高优先队列中的报文发送完,然后发送中优先队列中的报文,同样,直到发送完,然后是正常优先队列和低优先队列。这样,分类时属于较高优先级队列的报文将会得到优先发送,而较低优先级的报文将会在发生拥塞时被较高优先级的报文抢占。这样会使得实时业务(如VoIP)的报文能够得到优先处理,非实时业务(如E-Mail)的报文在网络处理完关键业务后的空闲间隙得到处理,既保证了实时业务的优先,又充分利用了网络资源。
PQ的缺点是,当较高优先级队列中总有报文存在时,则低优先级队列中的报文将一直得不到服务,出现队列“饿死”现象。
3.2.4 CQ原理简述
CQ(Custom Queuing,定制队列)示意图如下所示:
图4 CQ队列示意图
CQ的分类方法和PQ基本相同,不同的是它最终将所有报文分成最多至17类,每类报文对应CQ中的一个队列,接口拥塞时,报文按匹配规则被送入对应的队列;如果报文不匹配任何规则,则被送入缺省队列(缺省队列默认为1,可配置修改缺省队列)。
CQ的17个队列中,0号队列是优先队列,路由器总是先把0号队列中的报文发送完,然后才处理1到16号队列中的报文,所以0号队列一般作为系统队列,把实时性要求高的交互式协议报文放到0号队列。1到16号队列调度采用轮询方式,按照用户预先配置的额度依次从1到16号用户队列中取出一定数量的报文发送。如果轮询到某队列时该队列恰好为空,则立即转而轮询下一个队列。
CQ把报文分类,然后按类别将报文分配到CQ的一个队列中去,而对每个队列,又可以规定队列中的报文所占接口带宽的比例,这样,就可以让不同业务的报文获得合理的带宽,从而既保证关键业务能获得较多的带宽,又不至于使非关键业务得不到带宽。但由于采用轮询调度各个队列,CQ无法保证任何数据流的延迟。
3.2.5 WFQ原理简述
WFQ(Weighted Fair Queuing,加权公平队列)示意图如下所示:
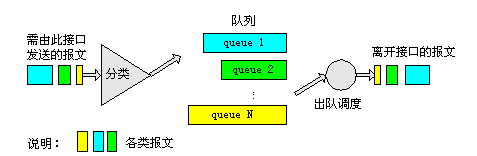
图5 WFQ队列示意图
WFQ对报文按流特征进行分类,对于IP网络,相同源IP地址、目的IP地址、源端口号、目的端口号、协议号、ToS的报文属于同一个流,而对于MPLS网络,具有相同的标签和EXP域值的报文属于同一个流。每一个流被分配到一个队列,该过程称为散列,采用HASH算法来自动完成,这种方式会尽量将不同特征的流分入不同的队列中。每个队列类别可以看作是一类流,其报文进入WFQ中的同一个队列。WFQ允许的队列数目是有限的,用户可以根据需要配置该值。
在出队的时候,WFQ按流的优先级(precedence)来分配每个流应占有出口的带宽。优先级的数值越小,所得的带宽越少。优先级的数值越大,所得的带宽越多。这样就保证了相同优先级业务之间的公平,体现了不同优先级业务之间的权值。
WFQ优点在于配置简单,有利于小包的转发,每条流都可以获得公平调度,同时照顾高优先级报文的利益。但由于流是自动分类,无法手工干预,故缺乏一定的灵活性,且受资源限制,当多个流进入同一个队列时无法提供精确服务,无法保证每个流获得的实际资源量。WFQ均衡各个流的延迟与抖动,同样也不适合延迟敏感的业务应用。
3.2.6 CBQ原理简述
CBQ(Class Based Queuing,基于类的队列)示意图如下所示:
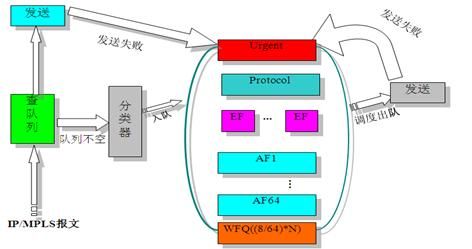
图6 CBQ队列示意图
CBQ首先根据IP优先级或者DSCP、输入接口、IP报文的五元组等规则来对报文进行分类;对于MPLS网络的LSR,主要是根据EXP域值进行分类。然后让不同类别的报文进入不同的队列。对于不匹配任何类别的报文,报文被送入系统定义的缺省类。
CBQ包括一个低时延队列LLQ(Low Latency Queuing,低时延队列),用来支撑EF(Expedited Forwarding,快速转发)类业务,被绝对优先发送,保证时延。进入EF的报文在接口没有发生拥塞的时候(此时所有队列中都没有报文),所有属于EF的报文都可以被发送。在接口发生拥塞的时候(队列中有报文时),进入EF的报文被限速,超出规定流量的报文将被丢弃。
另外有64个BQ队列(Bandwidth Queuing,带宽保证队列),用来支撑AF(Assured Forwarding,确保转发)类业务,可以保证每一个队列的带宽及可控的时延。系统调度报文出队列的时候,按用户为各类报文设定的带宽将报文出队发送。这种队列技术应用了先进的队列调度算法,可以实现各个类的队列的公平调度。当接口中某些类别的队列没有报文时,BQ队列的报文还可以公平地得到空闲的带宽,和时分复用系统相比,大大提高了线路的利用率。同时,在接口拥塞的时候,仍然能保证各类报文得到用户设定的最小带宽。
最后还有一个WFQ队列,对应BE(Best Effort,尽力传送)业务,使用接口剩余带宽进行发送。
CBQ可根据报文的输入接口、满足ACL情况、IP Precedence、DSCP、EXP、Label等规则对报文进行分类、进入相应队列。对于进入EF和AF的报文,要进行测量;考虑到链路层控制报文的发送、链路层封装开销及物理层开销(如ATM信元头),建议EF与AF占用接口的总带宽不要超过接口带宽的75%。
CBQ可为不同的业务定义不同的调度策略(如带宽、时延等),由于涉及到复杂的流分类,对于高速接口(GE以上)启用CBQ特性系统资源存在一定的开销。
3.2.7 RTP原理简述
RTP优先队列(Real Time Protocol Priority Queuing) 示意图如下所示:
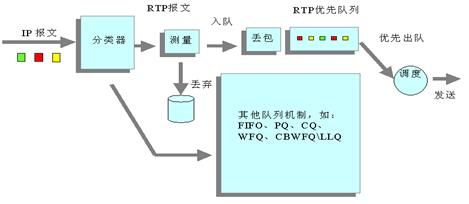
图7 RTP队列示意图
RTP优先队列是一种保证实时业务(包括语音与视频业务)服务质量的简单队列技术。其原理就是将承载语音或视频的RTP报文送入高优先级队列,使其得到优先发送,保证时延和抖动降低为最低限度,从而保证了语音或视频这种对时延敏感业务的服务质量。
RTP优先队列将RTP报文送入一个具有较高优先级的队列,RTP报文是端口号在一定范围内为偶数的UDP报文,端口号的范围可以配置,一般为16384~32767。RTP优先队列可以同前面所述的任何一种队列(包括FIFO、PQ、CQ、WFQ与CBQ)结合使用,它的优先级是最高的。由于CBQ中的EF完全可以解决实时业务,所以不推荐将RTP优先队列与CBQ结合应用。
由于对进入RTP优先队列的报文进行了限速,超出规定流量的报文将被丢弃,这样在接口拥塞的情况下,可以保证属于RTP优先队列的报文不会占用超出规定的带宽,保护了其他报文的应得带宽,解决了PQ的高优先级队列的流量可能“饿死”低优先级流量的问题。
3.3 拥塞避免原理
受限于设备的内存资源,按照传统的处理方法,当队列的长度达到规定的最大长度时,所有到来的报文都被丢弃。对于TCP报文,如果大量的报文被丢弃,将造成TCP超时,从而引发TCP的慢启动和拥塞避免机制,使TCP减少报文的发送。当队列同时丢弃多个TCP连接的报文时,将造成多个TCP连接同时进入慢启动和拥塞避免,称之为:TCP全局同步。这样多个TCP连接发向队列的报文将同时减少,使得发向队列的报文的量不及线路发送的速度,减少了线路带宽的利用。并且,发向队列的报文的流量总是忽大忽小,使线路的上的流量总在极少和饱满之间波动。
为了避免这种情况的发生,队列可以采用加权随机早期检测WRED(Weighted Random Early Detection)的报文丢弃策略(WRED与RED的区别在于前者引入IP优先权,DSCP值,和MPLS EXP来区别丢弃策略)。采用WRED时,用户可以设定队列的阈值(threshold)。当队列的长度小于低阈值时,不丢弃报文;当队列的长度在低阈值和高阈值之间时,WRED开始随机丢弃报文(队列的长度越长,丢弃的概率越高);当队列的长度大于高阈值时,丢弃所有的报文。
WRED和队列机制的关系如下图所示:
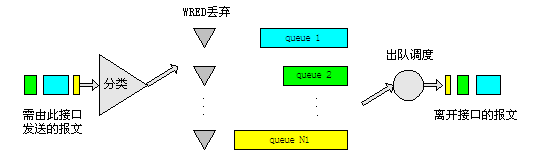
图8 WRED处理方式示意图
3.4 流量监管原理
流量监管(Commit Access Rate,简称CAR)的典型作用是限制进入某一网络的某一连接的流量与突发。在报文满足一定的条件时,如某个连接的报文流量过大,流量监管就可以对该报文采取不同的处理动作,例如丢弃报文,或重新设置报文的优先级等。通常的用法是使用CAR来限制某类报文的流量,例如限制HTTP报文不能占用超过50%的网络带宽。
CAR利用令牌桶(Token Bucket,简称TB)进行流量控制。下图所示为利用CAR进行流量控制的基本处理过程:
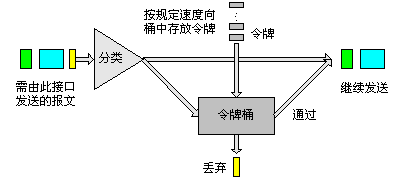
图9 CAR处理方式示意图
首先,根据预先设置的匹配规则来对报文进行分类,如果是没有规定流量特性的报文,就直接继续发送,并不需要经过令牌桶的处理;如果是需要进行流量控制的报文,则会进入令牌桶中进行处理。如果令牌桶中有足够的令牌可以用来发送报文,则允许报文通过,报文可以被继续发送下去。如果令牌桶中的令牌不满足报文的发送条件,则报文被丢弃。这样,就可以对某类报文的流量进行控制。
在实际应用中,CAR不仅可以用来进行流量控制,还可以进行报文的标记(mark)或重新标记(re-mark)。具体来讲就是CAR可以设置IP报文的优先级或修改IP报文的优先级,达到标记报文的目的。
3.5 流量整型原理
通用流量整形(Generic Traffic Shaping,简称GTS)可以对不规则或不符合预定流量特性的流量进行整形,以利于网络上下游之间的带宽匹配。
GTS与CAR一样,均采用了令牌桶技术来控制流量。GTS与CAR的主要区别在于:利用CAR在接口的出、入方向进行报文的流量控制,对不符合流量特性的报文进行丢弃;而GTS只在接口的出方向对于不符合流量特性的报文进行缓冲,减少了报文的丢弃,同时满足报文的流量特性,但增加了报文的延迟。
GTS的基本处理过程如下图所示,其中用于缓存报文的队列称为GTS队列。
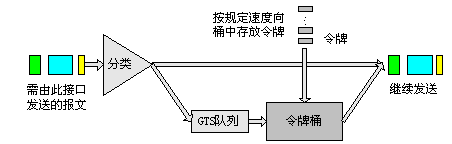
图10 GTS处理过程示意图
3.6 物理接口总速率限制原理
利用物理接口总速率限制(Line Rate,简称LR)可以在一个物理接口上,限制接口发送报文(包括紧急报文)的总速率。
LR的处理过程仍然采用令牌桶进行流量控制。如果用户在路由器的某个接口上配置了LR,规定了流量特性,则所有经由该接口发送的报文首先要经过LR的令牌桶进行处理。如果令牌桶中有足够的令牌可以用来发送报文,则报文可以发送。如果令牌桶中的令牌不满足报文的发送条件,则报文入QoS队列进行拥塞管理。这样,就可以对通过该物理接口的报文流量进行控制。
LR的基本处理过程如下图所示:
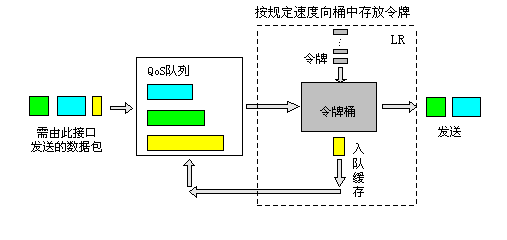
图11 LR处理过程示意图
4 其他提高QoS的技术
4.1 链路效率机制
链路效率机制,用于改善链路的性能,间接提高网络的QoS,如降低链路发包的时延(针对特定业务)、调整有效带宽。链路效率机制有很多种,下面介绍两种比较典型的链路效率机制及其基本原理。
4.1.1 链路分片与交叉(Link Fragment & Interleave,LFI)
对于低速链路,即使为语音等实时业务报文配置了高优先级队列(如RTP优先队列或LLQ),也不能够保证其时延与抖动,原因在于接口在发送其他数据报文的瞬间,语音业务报文只能等待,而对于低速接口发送较大的数据报文要花费相当长的时间。采用LFI以后,数据报文(非RTP实时队列和LLQ中的报文)在发送前被分片、逐一发送,而此时如果有语音报文到达则被优先发送,从而保证了语音等实时业务的时延与抖动。LFI主要用于低速链路。
链路效率机制的工作原理图如下所示:
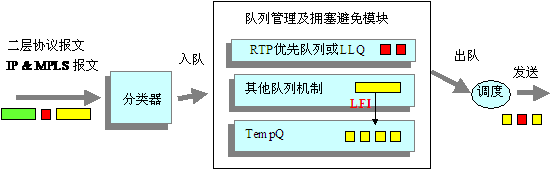
图12 LFI处理过程示意图
如上图所示,应用LFI技术,在大报文出队的时候,可以将其分为定制长度的小片报文,这就使RTP优先队列或LLQ中的报文不必等到大片报文发完后再得到调度,它等候的时间只是其中小片报文的发送时间,这样就很大程度的降低了低速链路因为发送大片报文造成的时延。
4.1.2 RTP报文头压缩(RTP Header Compression,CRTP)
CRTP用于RTP(Real-time Transport Protocol)协议,对IP头、UDP头和RTP头进行压缩,通常在低速链路上使用。可将40字节的IP/UDP/RTP头压缩到2~4个字节(不使用UDP校验和可到2字节),提高链路带宽的利用率。CRTP主要得益于同一会话的语音分组头和语音分组头之间的差别往往是不变的,因此只需传递增量。
RTP协议用于在IP网络上承载语音、视频等实时多媒体业务。RTP报文包括头部分和数据部分,RTP的头部分包括:12字节的RTP头,加上20字节的IP头和8字节的UDP头,就是40字节的IP/UDP/RTP头;RTP数据部分典型载荷是20字节到160字节。为了避免不必要的带宽消耗,可以使用CRTP特性对报文头进行压缩。CRTP可以将IP/UDP/RTP头从40字节压缩到2~4字节,对于40字节的载荷,头压缩到4字节,压缩比为(40+40)/(40+4),约为1.82,可见效果是相当可观的,可以有效的减少链路带宽的消耗,尤其是低速链路。
RTP报文头压缩的处理过程如下图所示:
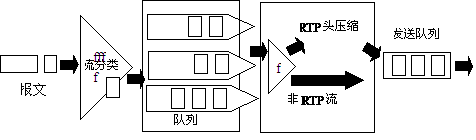
图13 CRTP处理过程示意图
4.2 链路层QoS技术
链路层QoS技术主要针对ATM(Asynchronous Transfer Mode,异步传输模式)、帧中继等链路层协议支持QoS。ATM作为一种面向连接的技术,提供对QoS最强有力的支持,而且可以基于每个连接提供特定的QoS保证;帧中继网络确保连接的CIR(Committed Information Rate,承诺信息速率)最小,即在网络拥塞时,传输速度不能小于这个值。
4.2.1 ATM QoS
ATM是异步传输模式(Asynchronous Transfer Mode)的简称,以信元为基本单位进行信息传输、复接和交换。ATM信元具有53字节的固定长度,其中5个字节构成信元头部,主要用来标识虚连接,另外也完成了一些功能有限的流量控制,拥塞控制,差错控制等功能,其余48个字节是有效载荷。ATM是面向连接的交换,其连接是逻辑连接,即虚电路。每条虚电路(Virtual Circuit,VC)用虚路径标识符(Virtual Path Identifier,VPI)和虚通道标识符(Virtual Channel Identifier,VCI)来标识。一个VPI/VCI值对只具有本地意义,不具有全局有效性。它在ATM节点上被翻译。当一个连接被释放时,与此相关的VPI/VCI值对也被释放,它被放回资源表,供其它连接使用。
ATM中每一条VC都有一定的QoS保障,这是由ATM的连接管理来实现的。当用户与网络或网络与网络建立一个连接的时候,双方就确定了一份通信契约,契约中包括流量参数和QoS参数两部分。此通信契约为双方所共识,双方必须遵守。流量参数包括峰值信元速率(PCR,Peak Cell Rate)、持续信元速率(SCR,Sustained Cell Rate)、最小信元速率(MCR,Minimum Cell Rate)以及最大突发量(MBS,Maximum Burst Size),它们描述业务本身的流量特性,又称为源流量参数。QoS参数主要包括最大信元传递时延(MCTD,MeanCell Transfer Delay)、信元抖动容限(CDVT,CellDelayVariationTolerance)和信元丢失率(CLR,Cell Loss Ratio), MCTD是信元从一个端点到另一个端点所需要的时间, CDVT是信元间隔的上限, CLR是可以接受的因网络拥塞而导致信元丢失比例。
ATM端系统负责确保传输的流量符合QoS合同。ATM端系统通过缓冲数据来对流量进行整形,并按约定的QoS参数传输通信。ATM交换机控制每个用户的通信指标,并将其与QoS合同进行比较。对于超过了QoS合同的通信,ATM节点可以设置信元的CLP(Cell Loss Priority,信元丢弃优先级)位。在网络拥塞时,CLP置位的信元被丢弃的可能性更大。
ATM网络拥塞管理的基本思想在于:引入预防性控制措施,不再是出现拥塞之后再采取措施来消除拥塞,而是通过精心管理网络资源来避免拥塞的出现。
4.2.2 FR QoS
FR(Frame Relay,帧中继)是一种统计复用的协议,它能够在单一物理传输线路上提供多条虚电路。每条虚电路用DLCI(Data Link Connection Identifier,数据链路连接标识)来标识。每条虚电路通过LMI(Local Management Interface,本地管理接口)协议检测和维护虚电路的状态。
帧中继采用VC(Virtual Circuit)虚电路技术,即帧中继传送数据使用的传输链路是逻辑连接,而不是物理连接。虚电路是面向连接的,可以保证用户帧按顺序传送至目的地。根据虚电路建立方式的不同,将帧中继虚电路分为两种类型:永久虚电路(PVC,Permanent Virtual Circuit)和交换虚电路(SVC,Switched Virtual Circuit)。PVC是手工设置产生的虚电路,而SVC是通过协议协商自动创建和删除的虚电路。
帧中继报头中的3个位提供了帧中继网络中的拥塞控制机制,这3个位分别叫做向前显式拥塞通知(FECN,Forward Explicit Congestion Notification)位、向后显式拥塞通知(BECN,Backward Explicit Congestion Notification)位和丢弃合格(DE,Discard Eligible)位。可以通过帧中继交换机将FECN位置1来告知诸如路由器等目标数据终端设备(DTE,Data Terminal Equipment),在帧从源传送到目的地的方向发生了拥塞。帧中继交换机将BECN位置1则告知目标路由器,在帧从源传送到目的地的反方向上发生了拥塞。DE位由路由器或其他DTE设备设置,指出被标记的帧没有传输的其他帧那么重要,它在帧中继网络中提供了一种基本的优先级机制,如果发生拥塞时,DE位置位的帧会被优先丢弃。
帧中继流量整形(FRTS,Frame Relay Traffic Shaping)对从帧中继VC输出的通信进行整形,使之与配置速率一致,它将超出平均速率的分组放到缓冲区来使突发通信变得平滑。根据配置的排队机制,当有足够的可用资源时,这些缓冲的分组出队并等候被传输。排队算法是基于单个VC配置的,它只能针对接口的出站通信进行设置。FRTS可对每个VC的流量进行整形,将其峰值速率整形为承诺信息速率(CIR,Committed Information Rate)或其他定义的值,如超额信息速率(EIR,Excess Information Rate)。自适应模式的FRTS还能够根据收到的网络BECN拥塞指示符降低帧中继VC的输出量,将PVC的输出流量整形为与网络的可用带宽一致。
转自: http://www.h3c.com.cn/MiniSite/Technology_Circle/Net_Reptile/The_Four/Home/Catalog/201104/713021_97665_0.htm