深入解析 ThreadLocal 和 ThreadLocalMap
Introduction
最近琐事比较多,关于之前决定的阅读 jdk 1.8 源码的计划稍微耽搁了一个月,现在重新捡起来,本文来讲讲 java.lang 包下的 ThreadLocal 结构,先介绍一下 ThreadLocal 的基本用法,之后解析一下它的源码实现,ThreadLocal 字面意思是线程局部变量,能为当前线程存储独属的变量,每个线程往这个结构中读写是线程安全的,因为每个线程都有各自独立的副本不冲突。
API
之前也说了,ThreadLocal 结构让我们能够存储只能被特定线程访问的数据,如果我们需要一个和某个线程绑定的 Integer 值的话,我们可以这样:
ThreadLocal threadLocalValue = new ThreadLocal<>() 接下来,当我们需要在线程中使用这个值时,我们只需要调用 get() 或者 set() 方法,从方法名字上我们可以猜测 ThreadLocal 应该是将数据存储在 Map 结构中,并且为了根据特定线程去取值,那么究竟是用什么作为 key 存在呢?下文源码分析中有,目前其他博文中根据 get(this) 方法认为是 thread 作为 key 实际上并不正确。
继续,当我们在 threadLocalValue 对象上调用其 get() 方法时,我们可以获得其中存储的值:
threadLocalValue.set(1);
Integer result = threadLocal.get();JDK 1.8 中为了契合函数式编程,我们也可以直接使用 withInitial() 这个静态方法去创建有初始值的 ThreadLocal 对象:
ThreadLocal threadLocal = ThreadLocal.withInitial(() -> 1); 调用 remove() 方法可以删除对象存储的值:
threadLocal.remove();Example
我们先看一个例子,来源于 An Introduction to ThreadLocal in Java
下面的程序使用 ThreadLocal 来存储 userName,每个线程都有属于自己的 userName 变量。
public class Context {
private String userName;
public Context(String userName) {
this.userName = userName;
}
}
public class ThreadLocalWithUserContext implements Runnable {
private static ThreadLocal userContext = new ThreadLocal<>();
private Integer userId;
private UserRepository userRepository = new UserRepository();
@Override
public void run() {
String userName = userRepository.getUserNameForUserId(userId);
userContext.set(new Context(userName));
System.out.println("thread context for given userId: "
+ userId + " is: " + userContext.get());
}
// standard constructor
} 我们可以这样来测试一下:
ThreadLocalWithUserContext firstUser = new ThreadLocalWithUserContext(1);
ThreadLocalWithUserContext secondUser = new ThreadLocalWithUserContext(2);
new Thread(firstUser).start();
new Thread(secondUser).start();输出结果如下:
thread context for given userId: 1 is: Context{userNameSecret='18a78f8e-24d2-4abf-91d6-79eaa198123f'}
thread context for given userId: 2 is: Context{userNameSecret='e19f6a0a-253e-423e-8b2b-bca1f471ae5c'}Attention
如果我们想使用 ExecutorService 并向它提交一个 Runnable,那么使用ThreadLocal将会产生非确定性的结果 —— 因为我们没有保证每一个给定的变量的 Runnable 在每次被执行时都被同一个线程处理。
因此,我们的 ThreadLocal 将在不同的用户标识之间共享。这就是为什么我们不应该与 ExecutorService 一起使用 TheadLocal 的原因。只有当我们能够完全控制哪个线程将执行哪个 Runnable 时,才应该去使用它。
Source Code Analysis
get() & set()
public T get() {
Thread t = Thread.currentThread(); //当前线程
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this); //以当前线程为 key 得到 map 中的 Entry
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value; //拿到值
return result;
}
}
return setInitialValue(); //如果是 null 的话,调用 setInitialValue() 方法
}
private T setInitialValue() {
T value = initialValue(); // null
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value); //如果当前线程的 map 已经存在,set 值为 null
else
createMap(t, value); //否则创建 map
return value;
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value); //设置 value
else
createMap(t, value);
}ThreadLocalMap
个人认为 ThreadLocalMap 才是 ThreadLocal 的必读部分。
Thread
我们先来看看 Thread 类下的一个属性:
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;通过这个属性我们可知,每个线程都能获取到一个 ThreadLocalMap,从而从中取值。
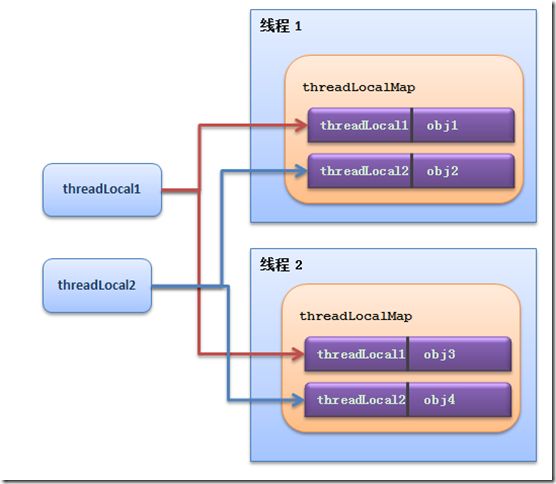
Entry
从源码中我们可以看到,Entry 结构实际上是继承了一个 ThreadLocal 类型的弱引用并将其作为 key,value 为 Object 类型。
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
} Why WeakReference
根据注释我们也可以推测,如果你了解 Java 中的四种引用类型的话,强引用、软引用、弱引用、虚引用的话,应该可以理解如果使用前两者,对于 GC 的话并不合适,除非强引用置 null 手动通知 GC 回收否则会一直存在在线程生命周期中;而软引用的话,也仅当内存不够时才会回收;虚引用因其特性无法完成 ThreadLocalMap 的所需功能;所以使用 WeakReference 类型是出于 GC 考虑,当某个 ThreadLocal 已经没有强引用指向时,它被 GC 回收,那么它的 ThreadLocalMap 里对应的 Entry 的键值会随之失效。
Attribute
// map 初始容量 16,必须为 2 的幂
private static final int INITIAL_CAPACITY = 16;
// Entry表,大小必须为2的幂
private Entry[] table;
private int size = 0;
//下次需要扩容的阈值,默认 0
private int threshold;
// 2/3 的负载因子
private void setThreshold(int len) {
threshold = len * 2 / 3;
}Constructor
ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
//初始化 table,大小 16
table = new Entry[INITIAL_CAPACITY];
//用第一个健的哈希值对初始大小取模得到索引,和 HashMap 的位运算代替取模原理一样
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
//初始化 Entry
table[i] = new Entry(firstKey, firstValue);
//第一个值进入 table,table 大小置 1
size = 1;
//设置阈值
setThreshold(INITIAL_CAPACITY);
}
... ...
//上面的 threadLocalHashCode 值为随着 ThreadLocal 构造时就会生成的 ID
private final int threadLocalHashCode = nextHashCode();
//原子类可以保证并发情况下不同的 ThreadLocal 只会生成唯一 threadLocalHashCode
private static AtomicInteger nextHashCode = new AtomicInteger();
//感觉是个种子一样的存在
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}getEntry & getEntryAfterMiss
private Entry getEntry(ThreadLocal key) {
//拿到 table 索引
int i = key.threadLocalHashCode & (table.length - 1);
//得到 entry
Entry e = table[i];
//得到值
if (e != null && e.get() == key)
return e;
else
//线性探测继续寻找
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal k = e.get();
//如果 key 相等则找到了值,返回
if (k == key)
return e;
//如果拿到一个 null 的 key 说明已经被回收了,需要清理
if (k == null)
expungeStaleEntry(i);
else
//否则的话说明需要继续寻找
i = nextIndex(i, len);
e = tab[i];
}
return null;
}expungeStaleEntry
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 将 table[i] 这个引用和 value 置 null
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--; //table 大小减一
// Rehash until we encounter null
Entry e;
int i;
从 i 位置开始遍历清理
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal k = e.get();
//遇到还可以清理的话顺便清理掉
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
//遇到还没被回收的,rehash 找到新的为空的索引位置
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
//将原位置置 null
tab[i] = null;
//找到新位置
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}set
private void set(ThreadLocal key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
//线性顺序寻找要 set 的位置
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal k = e.get();
//如果 key 存在则更新
if (k == key) {
e.value = value;
return;
}
//如果 key 为 null 说明该 entry 已经失效,则可以替换掉
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}ThreadLocal And Memory Leak
对于 ThreadLocal 与内存泄露的关系,作者 活在夢裡 的文章 ThreadLocal源码解读 中有非常精彩的阐述,在此直接引用他的论述 :
关于 ThreadLocal 是否会引起内存泄漏也是一个比较有争议性的问题,其实就是要看对内存泄漏的准确定义是什么。认为 ThreadLocal 会引起内存泄漏的说法是因为如果一个 ThreadLocal 对象被回收了,我们往里面放的 value 对于【 当前线程->当前线程的 threadLocals (ThreadLocal.ThreadLocalMap 对象)-> Entry 数组 -> 某个 entry.value】这样一条强引用链是可达的,因此 value 不会被回收。
认为 ThreadLocal 不会引起内存泄漏的说法是因为 ThreadLocal.ThreadLocalMap 源码实现中自带一套自我清理的机制。之所以有关于内存泄露的讨论是因为在有线程复用如线程池的场景中,一个线程的寿命很长,大对象长期不被回收影响系统运行效率与安全。如果线程不会复用,用完即销毁了也不会有 ThreadLocal 引发内存泄露的问题。《Effective Java》 一书中的第6条对这种内存泄露称为 unintentional object retention (无意识的对象保留)。
当我们仔细读过 ThreadLocalMap 的源码,我们可以推断,如果在使用的 ThreadLocal 的过程中,显式地进行remove是个很好的编码习惯,这样是不会引起内存泄漏。那么如果没有显式地进行remove呢?只能说如果对应线程之后调用ThreadLocal 的 get 和 set 方法都有很高的概率会顺便清理掉无效对象,断开value强引用,从而大对象被收集器回收。但无论如何,我们应该考虑到何时调用 ThreadLocal 的 remove 方法。一个比较熟悉的场景就是对于一个请求一个线程的 server 如 tomcat ,在代码中对 web api 作一个切面,存放一些如用户名等用户信息,在连接点方法结束后,再显式调用 remove。
Conclusion
本博文重点介绍了 ThreadLocal 的 api、使用方法、注意事项、源码分析,和其内部类 ThreadLocalMap 的源码分析。
许可协议
- 本文遵守创作共享 CC BY-NC-SA 3.0协议
- 商业用途转载请联系 Chen.Jiayang [AT] foxmail.com
- 个人主页 chenjiayang.me