效率提升80%!最好的反欺诈系统之一面世

图片来源:unsplash.com/@chillarea
2019年3月发布的一篇研究报告显示,欧洲40%所谓的AI创业实际上并没有使用AI技术。他们只是想利用普通大众(和投资人)对AI的一知半解,把自己标榜为酷炫黑魔法专家。
本文将介绍一款真正的ML驱动产品,并分享其真实的部署过程。
先来个大体介绍吧:Penelope是一款检测欺诈的内部工具。每一个在内部平台(HousingAnywhere:https://housinganywhere.com/?source=post_page---------------------------,一个涵盖全球400多个城市的住宿市场)发布的新页面,都会经由Penelope被分为欺诈或非欺诈,有些还会被标记,由客户解决方案(Customer Solutions,CS)部门进行人工检验。
Penelope使用过去三年收集的数据进行训练,并作为一个整体使用,其中每个模型互不干扰,针对不同的特征或数据集中按时间顺序排列的不同子集。
Penelope之前的反欺诈举措
Penelope并不是在HousingAnywhere成立之初就存在的。过去这些年,反欺诈系统主要依赖于一个由静态SQL规则构成的触发系统,在不使用AI技术的情况下也表现得非常好(这点简直难以置信)。
一些数据结构查询和查询本身并不繁琐,但是在一般情况下,一个经过良好设计和维护的简单系统的性能会优于非常复杂的解决方案。然而问题在于,存在特殊情况。当一家公司开始迅速扩张并需要高效解决问题时,往往容易忽略一些有益的习惯。
初始系统由大约50条规则构成,缺乏适当的文件记录,并存在重复的部分。我们没有收集任何有关它们性能的数据,也不知道为什么最初的设计者要创建这些规则。当意识到有些触发器数月都没有能够指向任何检测,并导致大量的时间浪费在无用的检查上时,却没有任何指标来验证这一假设。最终没有删除任何规则,还在现有系统的基础上加了新的规则。
设计新规则也是很有技巧的。有时候描述可疑行为并不是一件简单的事,有些对人脑来说非常简单的事可能需要上百行SQL语句来把可能储存在不同位置的表格放到一起。从那时起,我们开始考虑利用机器学习来代替规则系统,即停止精确地定义所有规则,让算法从数据中直接学习。
我们花了6个多月才达到了这一略有野心的目标,但是从一开始,我们脑海中就已经有了一个明确的使用案例和清晰的流程。我们没有简单地把随机数据丢给学习算法,看它的性能如何。而且,有了要把一个已经成功应用的现存产品(可以这么说吧)替换掉的目标,就有了一个真实的框架来有效检测替代产品。但是如果不能测量现有产品的性能,要怎么定义新产品是否成功呢?
一开始在Penelope项目上的努力都花费在了合理化和提高先前的规则系统上,后来才停用了这个系统。我们设计和启用了一个能够追踪每个(准确地来说,大部分)触发器性能的监测设备,并开始为客户解决方案部门搜集一些指标,来查出瓶颈,以及是否需要改进技术设备的内部流程。
我们最终认识到:如果一开始遵循的流程就是无效的,那么改进使用的技术设备将会是毫无意义的。人工智能是用于改进的工具,但它只发挥一部分的作用。它的有效性不在于使用它本身,而在于使用它去改进整个流程。实施机器学习不是最容易的事——总之——这是一场无法预料结果的战争。从一些简单的事情开始吧。
Penelope
一个可靠的反欺诈设备就绪后(大约一个月的工作),我们就开始构建一个替代品。一开始从来没有考虑过完全取代人工审核,也没有追求精确的性能。我们一直把准确度看作CS部门浪费在检查标记页面上的无效工作而不仅仅是一个数字,把召回率看作留在无约束条件下的欺诈页面数量。
规则系统在提供初始特征集时也很有帮助。除此之外还进行了一些其他调查,这主要是得益于每天处理诈骗犯的工作人员。我们并没有浪费时间调查那些无法从刚创建5分钟的页面上获取的特征。再一次说明,在初始阶段,有一个产品构想是非常有帮助的。

在训练模型的过程中遇到的真正的挑战在于平台生成数据的演化性。我们最终整合了5个LightGBM模型(https://github.com/microsoft/LightGBM?source=post_page---------------------------)(和XGBoost模型相比,性能相当,但训练时间更短),每个都用不同的纵向(样本数)或横向(特征数)数据集进行训练。每个模型都被赋予权重,以在新数据上有最好的性能(90-10验证,按时间顺序排序样本;用贝叶斯优化来探索权重空间)。
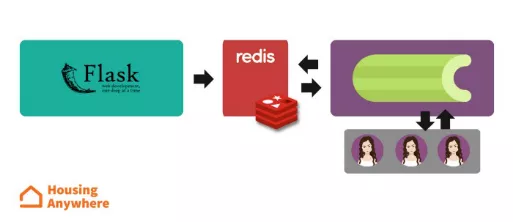
最终的模型被部署成为了网页的API(Flask),并输入了一个能够异步处理预测任务的Celery实例。每个任务的输出送往不同的通道,部署无法意识到正在使用的客户。每个在平台上发布的新页面(除了由信任的广告商发布的页面)都会被送到Penelope进行检查,或接收标记为欺诈,或送到人工检查。每个预测工作持续3-4秒,其中包括通过第三方资源收集数据。
在第一次成功部署后(大约在2019年1月),我们必须决定如何处理系统的再训练过程和数据的演化性。在进行了一些线下模拟,比较了不同的再训练场景后,发现对这一特殊领域来说,每2周再训练一次Penelope可以在性能上获得很大的提升(主要指能抓获更多诈骗犯)。当然,每次分类新页面时,使用整体中最新特征训练的模型都更为重要。希望未来能够去除一些旧模型,并增加一些新模型。当前阶段在这一方面很有信心,并且有可靠的渠道来发现新的移动特征用于训练模型。
性能和后续步骤
在Penelope之前,CS部门每周要花费80小时来人工检测可疑页面。现在,这一时间控制在了15小时(效率提升了80%)。主要的规则本身并没有立即见效,并且需要1-6小时来识别一个欺诈行为。这一局限性将访问者置于危险之中,因为网页在几小时内都是可获得和联系的。
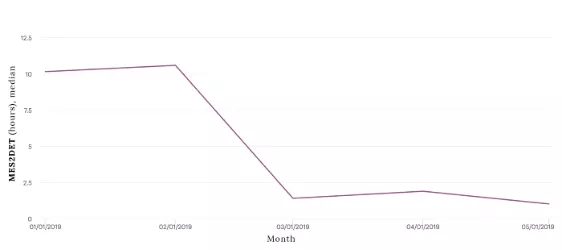
在Penelope发布之初就有的网页分类功能几乎消灭了这个风险,并实际上给了CS一个非常便利的指标来评估性能。目前的反欺诈系统(作为一个公司)的质量和CS部门检测由Penelope标记的网页的反应性紧密相关。Mes2Det是内部用于检测的指标。它是根据一个诈骗犯从被系统发现到上报的时间来计算的。可以清楚地发现,自Penelope启用以来,Mes2Det已经有了很大提升(从10小时到2小时),并且可以稳定运行几个月了。
目前在继续迭代Penelope,正在尽最大努力提高它的性能。已经学到的经验教训包括:研究方向在于减小模型的规模,以及尽可能整合用更小的数据集训练的更简单的组件,而不是用上百个复杂的特征来建立一个更大的结构。6月已经使用了Penelope第二版,并将准确性提高了大约10%,即使仅用初始版本一半的数据集训练,也能达到这一准确率。

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”
(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)