Hadoop学习笔记(二)HDFS
一、简介
HDFS是Apache Hadoop Core项目的一部分,是一个分布式文件系统。
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。
1.1 HDFS特点&目标
- 在HDFS文件系统中一个文件将被分布在几圈中的多肽机器上存储。
- HDFS与其他分布式文件系统的主要区别是:
- HDFS是一个高度容错性的系统,适合部署在廉价的机器上。
- 提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
- HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
硬件故障
硬件故障是常态,而不是异常。整个HDFS系统将由数百或数千个存储着文件数据片断的服务器组成。实际上它里面有非常巨大的组成部分,每一个组成部分都很可能出现故障,这就意味着HDFS里的总是有一些部件是失效的,因此,故障的检测和自动快速恢复是HDFS一个很核心的设计目标。
数据访问
运行在HDFS之上的应用程序必须流式地访问它们的数据集,它不是运行在普通文件系统之上的普通程序。HDFS被设计成适合批量处理的,而不是用户交互式的。重点是在数据吞吐量,而不是数据访问的反应时间,POSIX的很多硬性需求对于HDFS应用都是非必须的,去掉POSIX一小部分关键语义可以获得更好的数据吞吐率。
大数据集
运行在HDFS之上的程序有很大量的数据集。典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。
简单一致性模型
大部分的HDFS程序对文件操作需要的是一次写多次读取的操作模式。一个文件一旦创建、写入、关闭之后就不需要修改了。这个假定简单化了数据一致的问题,并使高吞吐量的数据访问变得可能。一个Map-Reduce程序或者网络爬虫程序都可以完美地适合这个模型。
移动计算比移动数据更经济
在靠近计算数据所存储的位置来进行计算是最理想的状态,尤其是在数据集特别巨大的时候。这样消除了网络的拥堵,提高了系统的整体吞吐量。一个假定就是迁移计算到离数据更近的位置比将数据移动到程序运行更近的位置要更好。HDFS提供了接口,来让程序将自己移动到离数据存储更近的位置。
异构软硬件平台间的可移植性
HDFS被设计成可以简便地实现平台间的迁移,这将推动需要大数据集的应用更广泛地采用HDFS作为平台。
1.2 不适合的存储场景
将HDFS用于要求低延迟数据访问的场景
由于HDFS是为高数据吞吐量应用而设计的,必然以高延迟为代价。
存储大量小型数据文件
HDFS中元数据(文件的基本信息)存储在NameNode的内存中,而NameNode为单点进程。这样当小文件数据量达到一定程度时,NameNode内存就吃不消了。
二、HDFS架构
2.1 数据块
HDFS机制将每个文件分割成一个或多个数据块,存储在一不同的从节点(DataNode)上。
数据块(Block):大文件被分割成多个Block进行存储,Block大小默认为64MB。每一个Block会在多个DataNode上存储多个副本,默认值为3。

每一个数据块都有一个对应的元数据,记录该数据块的位置和大小等信息。所有的元数据被放在主节点上。当客户端访问一个文件时,首先从主节点获取该文件的元数据,从而获取该文件所有数据块的存放信息。
2.2 机架与系统
机架(Rack):就是用于容纳多台机器的物理框架。
多台机器,尤其是成百上千台机器,其物理组织形式上通常是安装在“机架中”。通常情况下,一个机架可安装2-8台机器,若干机架再组成一个大型系统。
一个Block的三个副本通常会保存在两个或者两个以上的机架中(当然是机架中的服务器),这样做的目的是做防灾容错,因为一个机架掉电或者一个机架的交换机故障的发生概率还是很高的。
2.3 名字节点和数据节点
HDFS是一个主从结构,一个HDFS集群是由一个名字节点(NameNode),它是一个管理文件命名空间和调节客户端访问文件的主服务器,当然还有一些数据节点(DataNode),通常是一个节点一个机器,它来管理对应节点的存储。HDFS对外开放文件命名空间并允许用户数据以文件形式存储。
名字节点和数据节点都是运行在普通的机器之上的软件,机器典型的都是GNU/Linux,HDFS是用java编写的,任何支持java的机器都可以运行名字节点或数据节点,利用java语言的超轻便型,很容易将HDFS部署到大范围的机器上。典型的部署是由一个专门的机器来运行名字节点软件,集群中的其他每台机器运行一个数据节点实例。体系结构不排斥在一个机器上运行多个数据节点的实例,但是实际的部署不会有这种情况。
集群中只有一个名字节点极大地简单化了系统的体系结构。名字节点是仲裁者和所有HDFS元数据的仓库,用户的实际数据不经过名字节点。
DataNode:负责处理来自文件系统客户端的读/写请求,并进行数据块的读写、删除和复制。当然大部分容错机制都是在DataNode上实现的。
NameNode:负责管理文件目录、文件和Block的对应关系,以及Block和DataNode的映射关系。
内部机制
内部机制是将一个文件分割成一个或多个块,这些块被存储在一组数据节点中。名字节点用来操作文件命名空间的文件或目录操作,如打开,关闭,重命名等等。它同时确定块与数据节点的映射。数据节点负责来自文件系统客户的读写请求。数据节点同时还要执行块的创建,删除,和来自名字节点的块复制指令。
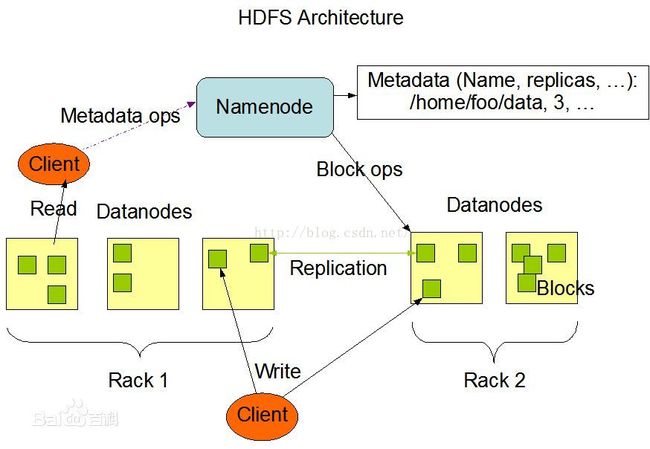
HDFS支持传统的继承式的文件组织结构。一个用户或一个程序可以创建目录,存储文件到很多目录之中。文件系统的名字空间层次和其他的文件系统相似。可以创建、移动文件,将文件从一个目录移动到另外一个,或重命名。HDFS还没有实现用户的配额和访问控制。HDFS还不支持硬链接和软链接。然而,HDFS结构不排斥在将来实现这些功能。
名字节点维护文件系统的命名空间,任何文件命名空间的改变和或属性都被名字节点记录。应用程序可以指定文件的副本数,文件的副本数被称作文件的复制因子,这些信息由命名空间来负责存储。
数据复制
一个Hadoop集群可能包含成百上千的节点,因此硬件故障时常态。这包括硬盘、从节点和机架等。HDFS通过从节点的数据块的冗余机制,有效地解决了高可用性与廉价硬件系统的矛盾。为了达成高可用性目标,文件的每个数据块必须有三个拷贝(可以预定义),这种数据块备份的存储策略使得数据高可用性,而无关于硬件的故障。
HDFS设计成能可靠地在集群中大量机器之间存储大量的文件,它以块序列的形式存储文件。文件中除了最后一个块,其他块都有相同的大小。属于文件的块为了故障容错而被复制。块的大小和复制数是以文件为单位进行配置的,应用可以在文件创建时或者之后修改复制因子。HDFS中的文件是一次写的,并且任何时候都只有一个写操作。
名字节点负责处理所有的块复制相关的决策。它周期性地接受集群中数据节点的心跳和块报告。
- 一个心跳的到达表示这个数据节点是正常的。
- 一个块报告包括该数据节点上所有块的列表。
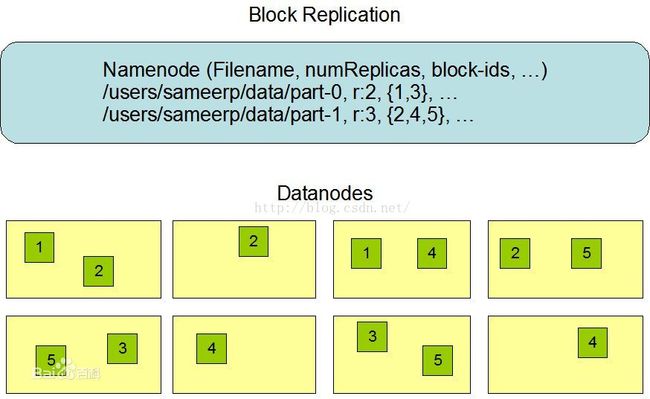
副本位置:第一小步
块副本存放位置的选择严重影响HDFS的可靠性和性能。副本存放位置的优化是HDFS区分于其他分布式文件系统的的特征,这需要精心的调节和大量的经验。机架敏感的副本存放策略是为了提高数据的可靠性,可用性和网络带宽的利用率。副本存放策略的实现是这个方向上比较原始的方式。短期的实现目标是要把这个策略放在生产环境下验证,了解更多它的行为,为以后测试研究更精致的策略打好基础。
HDFS运行在跨越大量机架的集群之上。两个不同机架上的节点是通过交换机实现通信的,在大多数情况下,相同机架上机器间的网络带宽优于在不同机架上的机器。
在开始的时候,每一个数据节点自检它所属的机架id,然后在向名字节点注册的时候告知它的机架id。HDFS提供接口以便很容易地挂载检测机架标示的模块。一个简单但不是最优的方式就是将副本放置在不同的机架上,这就防止了机架故障时数据的丢失,并且在读数据的时候可以充分利用不同机架的带宽。这个方式均匀地将复制分散在集群中,这就简单地实现了组建故障时的负载均衡。然而这种方式增加了写的成本,因为写的时候需要跨越多个机架传输文件块。
默认的HDFS block放置策略在最小化写开销和最大化数据可靠性、可用性以及总体读取带宽之间进行了一些折中。一般情况下复制因子为3,HDFS的副本放置策略是将第一个副本放在本地节点,将第二个副本放到本地机架上的另外一个节点而将第三个副本放到不同机架上的节点。这种方式减少了机架间的写流量,从而提高了写的性能。机架故障的几率远小于节点故障。这种方式并不影响数据可靠性和可用性的限制,并且它确实减少了读操作的网络聚合带宽,因为文件块仅存在两个不同的机架, 而不是三个。文件的副本不是均匀地分布在机架当中,1/3在同一个节点上,1/3副本在同一个机架上,另外1/3均匀地分布在其他机架上。这种方式提高了写的性能,并且不影响数据的可靠性和读性能。
副本的选择
为了尽量减小全局的带宽消耗读延迟,HDFS尝试返回给一个读操作离它最近的副本。假如在读节点的同一个机架上就有这个副本,就直接读这个,如果HDFS集群是跨越多个数据中心,那么本地数据中心的副本优先于远程的副本。
安全模式
在启动的时候,名字节点进入一个叫做安全模式的特殊状态。安全模式中不允许发生文件块的复制。名字节点接受来自数据节点的心跳和块报告。一个块报告包含数据节点所拥有的数据块的列表。
每一个块有一个特定的最小复制数。当名字节点检查这个块已经大于最小的复制数就被认为是安全地复制了,当达到配置的块安全复制比例时(加上额外的30秒),名字节点就退出安全模式。它将检测数据块的列表,将小于特定复制数的块复制到其他的数据节点。
文件系统的元数据的持久化
HDFS的命名空间是由名字节点来存储的。名字节点使用叫做EditLog的事务日志来持久记录每一个对文件系统元数据的改变,如在HDFS中创建一个新的文件,名字节点将会在EditLog中插入一条记录来记录这个改变。类似地,改变文件的复制因子也会向EditLog中插入一条记录。名字节点在本地文件系统中用一个文件来存储这个EditLog。整个文件系统命名空间,包括文件块的映射表和文件系统的配置都存在一个叫FsImage的文件中,FsImage也存放在名字节点的本地文件系统中。
名字节点在内存中保留一个完整的文件系统命名空间和文件块的映射表的镜像。这个元数据被设计成紧凑的,这样4GB内存的名字节点就足以处理非常大的文件数和目录。名字节点启动时,它将从磁盘中读取FsImage和EditLog,将EditLog中的所有事务应用到FsImage的仿内存空间,然后将新的FsImage刷新到本地磁盘中,因为事务已经被处理并已经持久化的FsImage中,然后就可以截去旧的EditLog。这个过程叫做检查点。当前实现中,检查点仅在名字节点启动的时候发生,正在支持周期性的检查点。
数据节点将HDFS数据存储到本地的文件系统中。数据节点并不知道HDFS文件的存在,它在本地文件系统中以单独的文件存储每一个HDFS文件的数据块。数据节点不会将所有的数据块文件存放到同一个目录中,而是启发式的检测每一个目录的最优文件数,并在适当的时候创建子目录。在本地同一个目录下创建所有的数据块文件不是最优的,因为本地文件系统可能不支持单个目录下巨额文件的高效操作。当数据节点启动的时候,它将扫描它的本地文件系统,根据本地的文件产生一个所有HDFS数据块的列表并报告给名字节点,这个报告称作块报告。
通信协议
所有的通信协议都是在TCP/IP协议之上构建的。一个客户端和指定TCP配置端口的名字节点建立连接之后,它和名字节点之间通信的协议是Client Protocal。数据节点和名字节点之间通过Datanode Protocol通信。
RPC(Remote Procedure Call)抽象地封装了Client Protocol和DataNode Protocol协议。按照设计,名字节点不会主动发起一个RPC,它只是被动地对数据节点和客户端发起的RPC作出反馈。
2.4 小结
对于HDFS客户端而言,无论读文件还是写文件,首先向NameNode发出元数据操作请求,以获取文件数据块与DataNode映射,然后在根据映射在对应的DataNode上进行数据块读/写操作。因此,用户的实际文件操作是不经过NameNode的。
三、主节点对数据块的管理
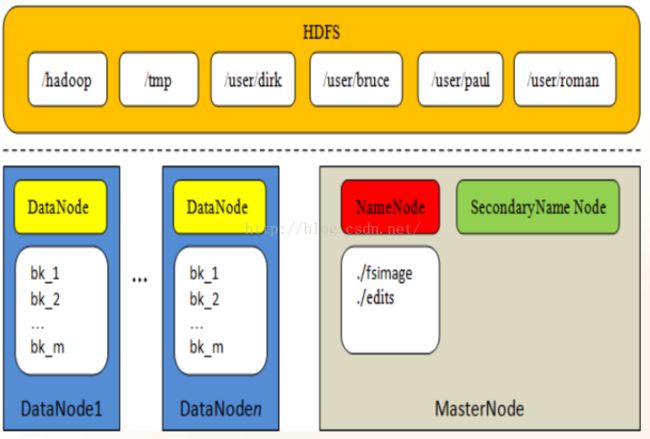
NameNode进程运行在主节点上,负责管理文件目录、文件和Block的对应关系,以及Block和DataNode的映射关系。
NameNode主要使用的以下两个文件:
- fsimage:顾名思义,是保存文件系统的映射信息。所有的数据块和文件的对应关系都被保存在该文件中,即元数据信息。
- edits:用来临时性记录数据改变情况的文件。NameNode使用edits文件来保存对元数据进行的每次操作,例如创建文件、删除文件,或修改文件的副本系数。
3.1 简单过程
当Hadoop客户端读取HDFS文件时,从NameNode获取的元数据就位于fsimage文件中。
如果Hadoop客户端进行了创建文件、删除文件,或修改文件的副本系数等操作,从而导致元数据发生变化时,这些改变不会立即更新到fsimage中,二十临时记录在edits文件中,称为EditLog。因此,HDFS是一个日志型文件系统。
3.2 CheckPoint机制
HDFS提供了一种机制,用于在合适的时机将edits文件内容合并到fsimage。这种时机被称为检查点(CheckPoint),在Hadoop 1.x中,SecondaryNameNode进程担任着CheckPoint工作。
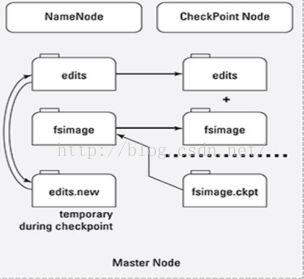
CheckPointNode(SecondaryNameNode)进程的CheckPoint工作过程如下:
- 定期启动CheckPoint。当CheckPoint启动时,NameNode创建一个新文件来接受日志文件系统的变化,该文件名为edits.new
- 文件edits不再接受新的变化,并和fsimage一起拷贝到CheckPointNode所在的文件系统中
- CheckPointNode将两个文件合并产生fsimage.ckpt文件
- CheckPointNode将fsimage.ckpt拷贝到NameNode上
- NameNode将使用新的fsimage.ckpt替代原fsimage文件
- NameNode用edits.new替代edits
3.3 NameNode工作过程
当Hadoop系统启动时,将启动NameNode进程,启动后将执行以下步骤完成初始化工作:
- NameNode进程将fsimage载入内存
- NameNode载入edit,并将日志文件中记录的数据改变更新到内存中的元数据
- DataNode进程向NameNode发送数据块报告单
当初始化完成后,NameNode进程随即进入就绪状态。
在就绪状态下,将执行以下任务:
- 处理基于客户端的请求,在DataNode上进行数据块增加删除等
- 更新日志文件edit,并在NameNode内存中更新元数据和数据块的位置
- DataNode进程每三秒向NameNode发送心跳信号,表明DataNode活动状态
- DataNode进程每六个小时向NameNode发送其所在节点的文件数据块报告(时间间隔可以自定义)
3.4 HDFS客户端读文件
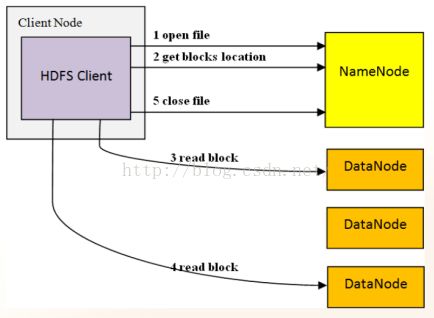
当HDFS客户端执行读文件操作时:
- 客户端想NameNode发出打开指定文件请求
- NameNode在元数据中找到该文件与DataNode之间数据块的映射关系,并将此数据返回给客户端
- 客户端按照映射关系,向指定DataNode发出读数据请求,并进而获取数据
- 如果第三步出现故障,客户端将根据映射从另外的DataNode上读取同样的数据,这体现了HDFS的容错能力
- 客户端NameNode发出关闭文件请求,以结束此次文件读操作。
3.5 HDFS客户端写文件
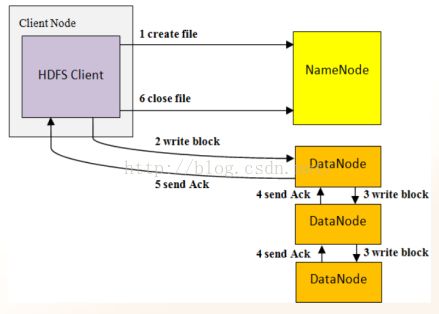
当HDFS客户端执行写文件操作时:
- 客户端向NameNode发出创建文件请求,NameNode计算出该文件与DataNode之间与DataNode之间数据块映射关系的元数据,并将此数据返回给客户端
- 客户端按照映射关系,向第一个DataNode发出写数据请求,并进而写入数据
- HDFS根据映射关系,将同样的数据块写入到另外两个DataNode主机上
- DataNode写数据块成功后,向前一个DataNode返回应答结果
- 第一个DataNode将最终应答结果返回给客户端
- 客户端向NameNode发出关闭文件请求,以结束此次文件写操作。
四、异常处理
HDFS的主要目标就是在存在故障的情况下也能可靠地存储数据。三个最常见的故障是名字节点故障,数据节点故障和网络断开。
4.1 重新复制
一个数据节点周期性发送一个心跳包到名字节点。网络断开会造成一组数据节点子集和名字节点失去联系。名字节点根据缺失的心跳信息判断故障情况。名字节点将这些数据节点标记为死亡状态,不再将新的IO请求转发到这些数据节点上,这些数据节点上的数据将对HDFS不再可用,可能会导致一些块的复制因子降低到指定的值。
名字节点检查所有的需要复制的块,并开始复制他们到其他的数据节点上。重新复制在有些情况下是不可或缺的,例如:数据节点失效,副本损坏,数据节点磁盘损坏或者文件的复制因子增大。
4.2 数据正确性
从数据节点上取一个文件块有可能是坏块,坏块的出现可能是存储设备错误,网络错误或者软件的漏洞。HDFS客户端实现了HDFS文件内容的校验。当一个客户端创建一个HDFS文件时,它会为每一个文件块计算一个校验码并将校验码存储在同一个HDFS命名空间下一个单独的隐藏文件中。当客户端访问这个文件时,它根据对应的校验文件来验证从数据节点接收到的数据。如果校验失败,客户端可以选择从其他拥有该块副本的数据节点获取这个块。
4.3 元数据失效
FsImage和Editlog是HDFS的核心数据结构。这些文件的损坏会导致整个集群的失效。因此,名字节点可以配置成支持多个FsImage和EditLog的副本。任何FsImage和EditLog的更新都会同步到每一份副本中。
同步更新多个EditLog副本会降低名字节点的命名空间事务交易速率。但是这种降低是可以接受的,因为HDFS程序中产生大量的数据请求,而不是元数据请求。名字节点重新启动时,选择最新一致的FsImage和EditLog。
名字节点对于一个HDFS集群是单点失效的。假如名字节点失效,就需要人工的干预。还不支持自动重启和到其它名字节点的切换。
4.4 避免错误的手段
快照
快照支持在一个特定时间存储一个数据拷贝,快照可以将失效的集群回滚到之前一个正常的时间点上。HDFS已经支持元数据快照。
数据组织
数据块
HDFS的设计是用于支持大文件的。运行在HDFS上的程序也是用于处理大数据集的。这些程序仅写一次数据,一次或多次读数据请求,并且这些读操作要求满足流式传输速度。HDFS支持文件的一次写多次读操作。HDFS中典型的块大小是64MB,一个HDFS文件可以被被切分成多个64MB大小的块,如果需要,每一个块可以分布在不同的数据节点上。
阶段状态
一个客户端创建一个文件的请求并不会立即转发到名字节点。实际上,一开始HDFS客户端将文件数据缓存在本地的临时文件中。应用程序的写操作被透明地重定向到这个临时本地文件。当本地文件堆积到一个HDFS块大小的时候,客户端才会通知名字节点。名字节点将文件名插入到文件系统层次中,然后为它分配一个数据块。名字节点构造包括数据节点ID(可能是多个,副本数据块存放的节点也有)和目标数据块标识的报文,用它回复客户端的请求。客户端收到后将本地的临时文件刷新到指定的数据节点数据块中。
当文件关闭时,本地临时文件中未上传的残留数据就会被转送到数据节点。然后客户端就可以通知名字节点文件已经关闭。此时,名字节点将文件的创建操作添加到到持久化存储中。假如名字节点在文件关闭之前死掉,文件就丢掉了。
上述流程是在认真考虑了运行在HDFS上的目标程序之后被采用。这些应用程序需要流式地写文件。如果客户端对远程文件系统进行直接写入而没有任何本地的缓存,这就会对网速和网络吞吐量产生很大的影响。这方面早有前车之鉴,早期的分布式文件系统如AFS,也用客户端缓冲来提高性能,POSIX接口的限制也被放宽以达到更高的数据上传速率。
流水式复制
当客户端写数据到HDFS文件中时,如上所述,数据首先被写入本地文件中,假设HDFS文件的复制因子是3,当本地文件堆积到一块大小的数据,客户端从名字节点获得一个数据节点的列表。这个列表也包含存放数据块副本的数据节点。当客户端刷新数据块到第一个数据节点。第一个数据节点开始以4kb为单元接收数据,将每一小块都写到本地库中,同时将每一小块都传送到列表中的第二个数据节点。同理,第二个数据节点将小块数据写入本地库中同时传给第三个数据节点,第三个数据节点直接写到本地库中。一个数据节点在接前一个节点数据的同时,还可以将数据流水式传递给下一个节点,所以,数据是流水式地从一个数据节点传递到下一个。
五、HDFS访问操作
HDFS提供多种方式由应用程序访问,自然地,HDFS提供为程序提供java api,为c语言包装的java api也是可用的,还有一个HTTP浏览器可以浏览HDFS中的文件,通过WebDAV协议访问HDFS库的方式也正在构建中。
5.1 DFSShell
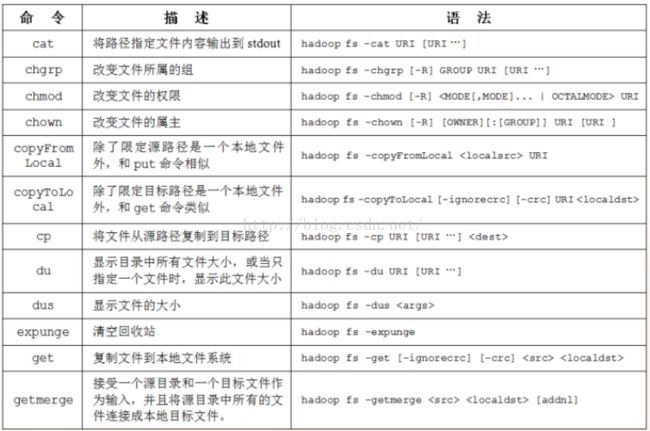
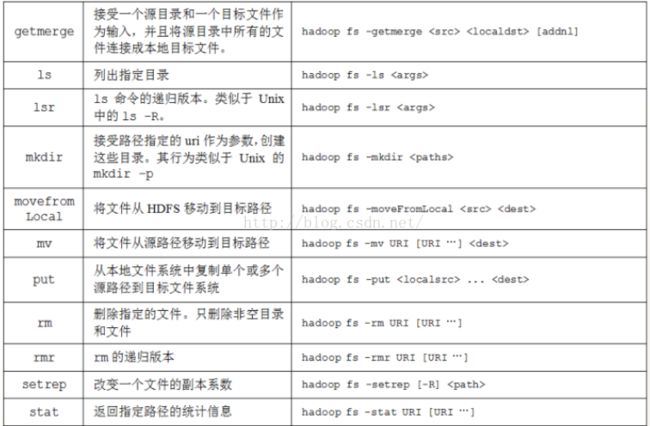
HDFS允许用户数据组织成文件和文件夹的方式,它提供一个叫DFSShell的接口,使用户可以和HDFS中的数据交互。命令集的语法跟其他用户熟悉的shells(bash,csh)相似。
命令的通用格式为:
hadoop fs|dfs - [args] cmd表示具体的操作命令;args表示命令所需要的参数
例如:列出HDFS指定目录下的文件:
hadoop fs -ls HDFS路径
HDFS路径(称为资源)使用URI格式来表示:
scheme://authority/pathscheme:协议名,file或hdfs;authority:NameNode主机名+端口号;path:文件路径
例如:
[root@winstar ~]# hadoop fs -ls hdfs://winstar:9000/user/root
Found 4 items
-rw-r--r-- 1 root supergroup 13 2016-11-22 14:22 /user/root/text
drwxr-xr-x - root supergroup 0 2016-11-23 00:57 /user/root/wceout
drwxr-xr-x - root supergroup 0 2016-11-22 09:28 /user/root/wcin
drwxr-xr-x - root supergroup 0 2016-11-22 09:29 /user/root/wcout如果在core-site.xml中有如下配置,则直接使用/user/root(路径)即可。
fs.default.name
hdfs://winstar:9000
HDFS默认工作目录为/user/$USER,$USER表示当前账户的用户名。
常用的命令示例
在user/目录下创建trunk子目录:
hadoop fs -mkdir /user/trunk列出user/目录下所有文件和子目录:
hadoop fs -ls /user递归列出user/目录下所有文件和子目录
hadoop fs -lsr /user将本地目录下test.txt文件上传至HDFS当前目录
hadoop fs -put test.txt .将HDFS/user/root/test.txt文件下载至本地当前目录
hadoop fs -get /user/root/test.txt查看/user/root/test.txt文件内容
hadoop fs -cat /user/root/test.txt查看/user/root/test.txt文件的尾部呃逆荣(最后1K)
hadoop fs -tail /user/root/test.txt删除/user/root/test.txt文件
hadoop fs -rm /user/root/test.txt查看ls命令的帮助文档
hadoop fs -help ls下面是上面命令的全部实战代码演示:
Script started on 2016年11月23日 星期三 07时50分32秒
[root@winstar Desktop]# hadoop fs -mkdir /user/trunk
[root@winstar Desktop]# hadoop fs -ls /user
Found 2 items
drwxr-xr-x - root supergroup 0 2016-11-23 00:57 /user/root
drwxr-xr-x - root supergroup 0 2016-11-23 07:50 /user/trunk
[root@winstar Desktop]# hadoop fs -lsr /user
drwxr-xr-x - root supergroup 0 2016-11-23 00:57 /user/root
-rw-r--r-- 1 root supergroup 13 2016-11-22 14:22 /user/root/text
drwxr-xr-x - root supergroup 0 2016-11-23 00:57 /user/root/wceout
-rw-r--r-- 3 root supergroup 0 2016-11-23 00:57 /user/root/wceout/_SUCCESS
-rw-r--r-- 3 root supergroup 35 2016-11-23 00:57 /user/root/wceout/part-r-00000
drwxr-xr-x - root supergroup 0 2016-11-22 09:28 /user/root/wcin
-rw-r--r-- 1 root supergroup 12 2016-11-22 09:28 /user/root/wcin/test1.txt
-rw-r--r-- 1 root supergroup 13 2016-11-22 09:28 /user/root/wcin/test2.txt
-rw-r--r-- 1 root supergroup 21 2016-11-22 09:28 /user/root/wcin/test3.txt
drwxr-xr-x - root supergroup 0 2016-11-22 09:29 /user/root/wcout
-rw-r--r-- 1 root supergroup 0 2016-11-22 09:29 /user/root/wcout/_SUCCESS
drwxr-xr-x - root supergroup 0 2016-11-22 09:28 /user/root/wcout/_logs
drwxr-xr-x - root supergroup 0 2016-11-22 09:28 /user/root/wcout/_logs/history
-rw-r--r-- 1 root supergroup 19024 2016-11-22 09:28 /user/root/wcout/_logs/history/job_201611220926_0001_1479835717524_root_word+count
-rw-r--r-- 1 root supergroup 47543 2016-11-22 09:28 /user/root/wcout/_logs/history/job_201611220926_0001_conf.xml
-rw-r--r-- 1 root supergroup 35 2016-11-22 09:28 /user/root/wcout/part-r-00000
drwxr-xr-x - root supergroup 0 2016-11-23 07:50 /user/trunk
[root@winstar Desktop]# ls
ceshi.sh~ softWare typescript 运行脚本记录
eclipse SubProjects WordCount.java
HDFSTest temp~ 大数据处理技术教学课件-详细标签.pdf
org test.txt 新文件~
[root@winstar Desktop]# hadoop fs -put test.txt .
[root@winstar Desktop]# hadoop fs -ls
Found 5 items
-rw-r--r-- 1 root supergroup 0 2016-11-23 07:54 /user/root/test.txt
-rw-r--r-- 1 root supergroup 13 2016-11-22 14:22 /user/root/text
drwxr-xr-x - root supergroup 0 2016-11-23 00:57 /user/root/wceout
drwxr-xr-x - root supergroup 0 2016-11-22 09:28 /user/root/wcin
drwxr-xr-x - root supergroup 0 2016-11-22 09:29 /user/root/wcout
[root@winstar Desktop]# ls
ceshi.sh~ org temp~ 大数据处理技术教学课件-详细标签.pdf
eclipse softWare typescript 新文件~
HDFSTest SubProjects WordCount.java 运行脚本记录
[root@winstar Desktop]# hadoop fs -get /user/root/test.txt .
[root@winstar Desktop]# ls
ceshi.sh~ softWare typescript 运行脚本记录
eclipse SubProjects WordCount.java
HDFSTest temp~ 大数据处理技术教学课件-详细标签.pdf
org test.txt 新文件~
[root@winstar Desktop]# hadoop fs -cat /user/root/test.txt
我是测试数据
[root@winstar Desktop]# hadoop fs -tail /user/root/test.txt
我是测试数据
[root@winstar Desktop]# hadoop fs -rm /user/root/test.txt
Deleted hdfs://winstar:9000/user/root/test.txt
[root@winstar Desktop]# hadoop fs -help ls
-ls : List the contents that match the specified file pattern. If
path is not specified, the contents of /user/
will be listed. Directory entries are of the form
dirName (full path)
and file entries are of the form
fileName(full path) size
where n is the number of replicas specified for the file
and size is the size of the file, in bytes.
[root@winstar Desktop]# exit
exit
Script done on 2016年11月23日 星期三 08时04分27秒 常用命令总结

5.2 DFSAdmin
DFSAdmin命令集是用于管理dfs集群的,这些命令只由HDFS管理员使用。
| Action |
Command |
| 将集群设置成安全模式 |
bin/hadoop dfsadmin -safemode enter |
| 产生一个数据节点的列表 |
bin/hadoop dfsadmin -report |
| 去掉一个数据节点 |
bin/hadoop dfsadmin -decommission datanodename |
5.3 浏览器接口
典型的HDFS初始化配置了一个web 服务,通过一个可配的TCP端口可以访问HDFS的命名空间。这就使得用户可以通过web浏览器去查看HDFS命名空间的内容。
六、HDFS管理与维护
6.1 可靠性运行机制
HDFS文件系统在设计上,除了通过冗余存储机制来保证高可用性之外,还提供了以下保障系统运行可靠性的机制:
- 数据块报告
- 心跳检测
- 安全模式
- 数据完整性检测
- 存储空间回收
数据块报告
DataNode使用本地文件系统来存储HDFS数据。DataNode本身不关心HDFS文件,他只是将HDFS文件的一个个数据块存储到本地文件系统中。当DataNode启动时,它会遍历本地文件系统,进而产生一份HDFS数据块和本地文件对应关系列表的报告,然后将该报告发送给NameNode,这就是数据块报告(BlockReport)。
块报告中包含了DataNode上所有块的列表。
心跳检测
NameNode会周期性地接收集群中每个DataNode发送过来的心跳包和数据块报告,并根据这个报告验证数据块映射和其它文件系统元数据。如果NameNode能够定时收到DataNode的心跳包,则认为DataNode工作正常,否则将标记那些没有心跳的DataNode为宕机,且不会再发给它们任何新的I/O请求。
DataNode的宕机会导致一些数据块的副本数下降并低于设定值,但NameNode会不断检测这些需要复制的数据块,并在需要的时候重新复制它们。
安全模式
Hadoop系统启动时,NameNode会进入安全模式。此时不会出现数据块的写操作。
在安全模式下,NameNode会收到各个DataNode发送来的数据块列表报告:
- 当数据块达到最小副本数时,该数据块被认为是安全的。
- 在一定比例(可以配置)的数据块被NameNode检测确认是安全之后,在等待若干时间,NameNode自动退出安全模式,进入正常工作状态
- 如果检测到副本数不足的数据块,该块会被复制到其他数据节点,以达到最小副本数。
数据完整性检测
多种原因会造成从DataNode获取的数据块有可能是损坏的,为此HDFS客户端软件实现了对HDFS文件内容的校验和检查。
当创建HDFS文件时,系统会计算每个数据块的校验和,并将校验和作为一个单独的隐含文件保存在其命名空间下。
当客户端获取文件后,会检查从DataNode所获得数据块的检验和隐含文件的校验和是否相同。如果不同,客户端认为数据块有损坏,会再从其他DataNode获取该数据块的副本。
存储空间回收
文件删除和恢复删除
当一个文件被用户或程序删除时,它并没有立即从HDFS中删除。HDFS将它重新命名后转存到/trash目录下,这个文件只要还在/trash目录下保留就可以重新快速恢复。文件在/trash中存放的时间是可配置的(缺省为6小时)。存储时间超时后,名字节点就将目标文件从名字空间中删除,同时此文件关联的所有文件块都将被释放。注意,用户删除文件的时间和HDF系统回收空闲存储之间的时间间隔是可以估计的。
删除一个文件之后,只要它还在/trash目录下,用户就可以恢复删除一个文件。如果一个用户希望恢复删除他已经删除的文件,可以查找/trash目录获得这个文件。/trash目录仅保存最新版本的删除文件。/trash目录也像其他目录一样,只有一个特殊的功能,HDFS采用一个特定的策略去自动地删除这个目录里的文件,当前默认的策略是删除在此目录存放超过6小时的文件。以后这个策略将由一个定义好的接口来配置。(取消操作很简单,只需将文件移动至普通目录即可)
减少复制因子
当文件的复制因子减少了,名字节点选择删除多余的副本,下一次的心跳包的回复就会将此信息传递给数据节点。然后,数据节点移除相应的块,对应的空闲空间将回归到集群中,需要注意的就是,在setReplication函数调用后和集群空闲空间更新之间会有一段时间延迟。
6.2 报告HDFS信息
Hadoop工具的dfsadmin选项是HDFS系统的管理工具之一,可用来获取HDFS状态信息,或在HDFS上执行一系列管理操作。可以使用dfsadmin的report命令来查看文件系统的基本信息和统计信息。
例如:
[root@winstar ~]# hadoop dfsadmin -report
Configured Capacity: 26827005952 (24.98 GB)
Present Capacity: 20673622016 (19.25 GB)
DFS Remaining: 20673343488 (19.25 GB)
DFS Used: 278528 (272 KB)
DFS Used%: 0%
Under replicated blocks: 1
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Datanodes available: 1 (1 total, 0 dead)
Name: 127.0.0.1:50010
Decommission Status : Normal
Configured Capacity: 26827005952 (24.98 GB)
DFS Used: 278528 (272 KB)
Non DFS Used: 6153383936 (5.73 GB)
DFS Remaining: 20673343488(19.25 GB)
DFS Used%: 0%
DFS Remaining%: 77.06%
Last contact: Wed Nov 23 08:38:52 PST 20166.3 管理安全模式
当Hadoop启动时,NameNode首先进入安全模式。在安全模式下,如果DataNode丢失的数块达到一定比例,系统会一直处于安全模式中。
dfsamin的safemode命令用于安全模式的操作:
hadoop dfsadmin -safemode 参数arg可以是以下值:
- enter:进入安全模式
- leave:强制NameNode离开安全模式
- get:获取安全模式是否开启的信息
- wait:等待,到安全模式结束
[root@winstar ~]# hadoop dfsadmin -safemode get
Safe mode is OFF
[root@winstar ~]# hadoop dfsadmin -safemode enter
Safe mode is ON
[root@winstar ~]# hadoop dfsadmin -safemode leave
Safe mode is OFF6.4 调节存储平衡
随着HDFS系统上数据读写的不断进行,各DataNode节点上的数据块会逐渐变得不均衡。
HDFS提供了调节存储平衡的工具start-balancer.sh。可用来根据存储策略重新分配数据,将数据从过度使用的节点移动到使用率较低的节点,以达到存储的平衡。
管理员须定期监控HDFS健康情况,如果发现不均衡,应及时使用该工具加以调整。
例如:
[root@winstar ~]# start-balancer.sh 参考资料:
- hdfs百度百科
- 大数据处理技术教学课件-详细标签
