Hadoop2.7.4集群的Linux安装步骤
一、 目标
搭建Hadoop2 HDFS HA集群
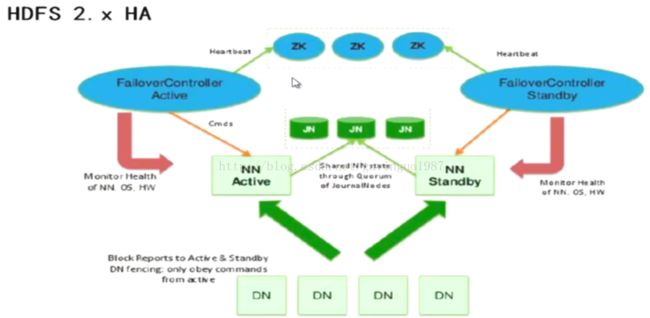
系统架构:
在一个典型的HA集群中,两台独立的服务器被配置为NameNode。在任何时间点,只有一个NameNode节点是Active状态,其他NameNode节点都是Standby状态。Active的NameNode节点负责集群中所有客户端的操作,而其他的Standby状态的节点只是简单的作为从节点保存状态数据,以便在必要的时候提供快速故障切换。
为了Standby节点保持与Active节点的数据同步,所有的NameNode节点都与一组独立的被称为JournalNode的后台进程通信。当任何命名空间的改动被Active节点执行,改动会被持久化的记录到JournalNode集群中。Standby节点能够从JournalNode集群中读取edits,并持久的监视edit日志的改动。在Standby节点读取edits的同时,它将edits应用到自己的命名空间。当发生系统故障时,在Standby节点升级为Active节点前,它将确认已经从JournalNode集群同步完了所有edits。这个动作确保了在系统故障前所有命名空间的状态被同步了。
为了提供一个快速的系统故障切换,Standby节点必须有集群最新的block地址数据。为了达成这个目标,所有的DataNode节点都被配置了所有NameNode的地址并将block的地址信息和心跳检查信息发送给所有的NameNode。
同时只有一个NameNode节点是Active的,这点对于正确使用HA集群十分重要。否则,命名空间的状态就会很快就会在不同的NameNode之间出现差异,存在数据丢失和产生错误结果的风险。为了避免风险产生,阻止所谓的“脑裂场景”,JournalNode集群同一时刻只允许一个NameNode节点写数据。当系统故障时,要升级为Active的NameNode节点将获取写数据的权限,这有效的阻止了其他NameNode继续在Active状态并允许新的Active节点安全处理系统故障。
JournalNode节点最少需要3台,并且应该是奇数个(如:3、5、7…),最多允许(N-1)/2的节点故障。
HA集群的nameserviceID和NameNode的NameNode ID需要提供给zookeeper进行注册。
操作系统:
CentOS Linux release 7.3.1611
服务器集群:
Node-0: 192.168.2.200
Node-1: 192.168.2.201
Node-2: 192.168.2.202
Node-3: 192.168.2.203
Node-4: 192.168.2.204
Node-5: 192.168.2.205
节点:
NN: NameNode
DN: DataNode
ZK: Zookeeper
ZKFC: Zookeeper Failover Controller
JN: JournalNoe
RM: YARN ResourceManager
DM: DataManager
部署规划:
|
|
NN |
DN |
ZK |
ZKFC |
JN |
RM |
DM |
| Node-0 |
1 |
|
1 |
1 |
|
1 |
|
| Node-1 |
1 |
|
1 |
1 |
|
|
|
| Node-2 |
|
1 |
1 |
|
1 |
|
1 |
| Node-3 |
|
1 |
1 |
|
1 |
|
1 |
| Node-4 |
|
1 |
1 |
|
1 |
|
1 |
| Node-5 |
|
1 |
|
|
|
|
1 |
二、 HDFS安装
1. 下载
Hadoop官网地址:http://hadoop.apache.org/
Hadoop 官网提供的安装包是32位编译的,在64位系统安装时需要下载源码并在64位系统上进行编译。编译后的安装包上传至/usr/loca/文件下。
2. 解压
| cd /usr/local tar -zxvf hadoop-2.7.4.tar.gz ls |
3. 安装
| cd /home/ mkdir hadoop ln -sf /usr/local/hadoop-2.7.4 /home/hadoop/hadoop2.7 |
4. 配置ssh免密码登录
免密码登录允许在任何一个节点使用ssh远程到其他服务器启动整个集群
是否使用免密码登录不影响集群的使用,可以分别登录到其他服务器单独启动其他节点
| #生成公钥私钥 ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa #将公钥导出为认证的key文件 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #修改key文件权限 chmod 0600 ~/.ssh/authorized_keys #将node0的公钥拷贝到node2上(node0中执行) scp ~/.ssh/id_rsa.pub root@node2:~/.ssh/node0_id_rsa.pub #在node2上将node0的公钥加入到认证列表中(node2中执行),more authorized_keys,里面有哪台机器的公钥,哪台机器才能免密码登录到node2 cat ~/.ssh/node0_id_rsa.pub >> ~/.ssh/authorized_keys #免密码登录到node2(node0中执行) ssh node2 #退出node2 exit |
三、 HDFSHA集群配置
1. 配置JAVA_HOME(etc/hadoop/hadoop-env.sh)
| cd /home/hadoop/hadoop2.7/etc/hadoop/ vi hadoop-env.sh |
| export JAVA_HOME=/usr/java/jdk1.8.0_144/ |
2.配置hdfs-site.xml(etc/hadoop/hdfs-site.xml)
| cd /home/hadoop/hadoop2.7/etc/hadoop/ vi hdfs-site.xml |
l 基础配置
n 配置命名服务,key格式dfs.nameservices
| |
n 配置NameNode,key格式dfs.ha.namenodes.[nameservice ID]
| |
n 配置每个NameNode的rpc协议端口,key格式dfs.namenode.rpc-address.[ nameservice ID].[namenode ID]
| |
n 配置每个NameNode的http协议端口,key格式dfs.namenode.http-address.[ nameservice ID].[namenode ID]
| |
n 配置JournalNode集群的URI,key格式dfs.namenode.shared.edits.dir
| |
n 配置客户端连接Active NameNode的Java类,key格dfs.client.failover.proxy.provider.[nameserviceID]
| |
n 配置故障隔离方法,key格式dfs.ha.fencing.methods
n (故障隔离保证原Active NameNode被杀死,不再提供read服务)
n 配置SSH的私钥,key格式dfs.ha.fencing.ssh.private-key-files
n 配置故障隔离方法失败的超时时间,key格式dfs.ha.fencing.ssh.connect-timeout
| |
n 配置JournalNode保存元数据的目录,key格式dfs.ha.fencing.ssh.connect-timeout
| |
l 自动故障切换配置
自动切换使用了ZooKeeper集群和ZKFailoverController进程
n ZooKeeper集群作用
u 故障检测
u Active NameNode 选举
n ZKFailoverController进程作为ZooKeeper的客户端运行在每个NameNode节点所在的服务器中,监控管理NameNode的状态
u 健康状况检测
u ZooKeeper会话管理
u 基于ZooKeeper的选举
n 配置启用自动故障切换,key格式dfs.ha.automatic-failover.enabled
|
|
至此,hdfs-site.xml配置完成,完整配置
| xml version="1.0" encoding="UTF-8"?> xml-stylesheettype="text/xsl"href="configuration.xsl"?>
<configuration> <property> <name>dfs.nameservicesname> <value>hdfs-clustervalue> property> <property> <name>dfs.ha.namenodes.hdfs-clustername> <value>nn1,nn2value> property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn1name> <value>node0:8020value> property> <property> <name>dfs.namenode.rpc-address.hdfs-cluster.nn2name> <value>node1:8020value> property> <property> <name>dfs.namenode.http-address.hdfs-cluster.nn1name> <value>node0:50070value> property> <property> <name>dfs.namenode.http-address.hdfs-cluster.nn2name> <value>node1:50070value> property> <property> <name>dfs.namenode.shared.edits.dirname> <value>qjournal://node2:8485;node3:8485;node4:8485/hdfs-cluster value> property> <property> <name>dfs.client.failover.proxy.provider.hdfs-clustername> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider value> property> <property> <name>dfs.ha.fencing.methodsname> <value>sshfencevalue> property> <property> <name>dfs.ha.fencing.ssh.private-key-filesname> <value>/root/.ssh/id_rsavalue> property> <property> <name>dfs.ha.fencing.ssh.connect-timeoutname> <value>30000value> property> <property> <name>dfs.journalnode.edits.dirname> <value>/opt/hadoop/jn/datavalue> property>
<property> <name>dfs.ha.automatic-failover.enabledname> <value>truevalue> property> configuration>
|
3.配置core-site.xml(etc/Hadoop/core-site.xml)
| cd /home/hadoop/hadoop2.7/etc/hadoop/ vi core-site.xml |
l 配置临时目录,key格式hadoop.tmp.dir
| |
l 配置NameNode入口,key格式fs.defaultFS
| |
l 配置ZooKeeper集群地址,key格式ha.zookeeper.quorum
| |
至此,core-site.xml配置完成,完整配置
| xml version="1.0" encoding="UTF-8"?> xml-stylesheettype="text/xsl"href="configuration.xsl"?>
<configuration> <property> <name>hadoop.tmp.dirname> <value>/opt/hadoop/tmpvalue> property> <property> <name>fs.defaultFSname> <value>hdfs://hdfs-clustervalue> property> <property> <name>ha.zookeeper.quorumname> <value>node0:2181,node1:2181,node2:2181,node3:2181,node4:2181value> property> configuration> |
4.配置slaves(etc/Hadoop/slaves)
| cd /home/hadoop/hadoop2.7/etc/hadoop/ vi slaves |
l 配置DataNode
| node2 node3 node4 node5 |
四、 启动环境
1. 将配置完毕的hadoop同步至其他节点
| echo 1.将hadoop安装文件拷贝至其他节点 scp /usr/local/ hadoop-2.7.4-x86_64.tar.gz root@node1:/usr/local/ scp /usr/local/ hadoop-2.7.4-x86_64.tar.gz root@node2:/usr/local/ scp /usr/local/ hadoop-2.7.4-x86_64.tar.gz root@node3:/usr/local/ scp /usr/local/ hadoop-2.7.4-x86_64.tar.gz root@node4:/usr/local/ scp /usr/local/ hadoop-2.7.4-x86_64.tar.gz root@node5:/usr/local/
echo 2.将hadoop安装文件解压并创建软连接 ssh node1 tar –zxvf /usr/local/ hadoop-2.7.4-x86_64.tar.gz ln –sf /usr/local/hadoop-2.7.4 /usr/home/hadoop/hadoop2.7 exit ssh node2 tar –zxvf /usr/local/ hadoop-2.7.4-x86_64.tar.gz ln –sf /usr/local/hadoop-2.7.4 /usr/home/hadoop/hadoop2.7 exit ssh node3 tar –zxvf /usr/local/ hadoop-2.7.4-x86_64.tar.gz ln –sf /usr/local/hadoop-2.7.4 /usr/home/hadoop/hadoop2.7 exit ssh node4 tar –zxvf /usr/local/ hadoop-2.7.4-x86_64.tar.gz ln –sf /usr/local/hadoop-2.7.4 /usr/home/hadoop/hadoop2.7 exit ssh node5 tar –zxvf /usr/local/ hadoop-2.7.4-x86_64.tar.gz ln –sf /usr/local/hadoop-2.7.4 /usr/home/hadoop/hadoop2.7 exit
echo 3.将node0中已配置完毕的配置文件拷贝至其他节点 cd /home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node1:/home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node2:/home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node3:/home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node4:/home/hadoop/hadoop2.7/etc/hadoop/ scp ./* root@node5:/home/hadoop/hadoop2.7/etc/hadoop/ |
2. 启动JournalNode
JournalNode所在节点node2,node3,node4
| ssh node2 cd /home/hadoop/hadoop2.7/sbin ./hadoop-daemon.sh start journalnode exit ssh node3 cd /home/hadoop/hadoop2.7/sbin ./hadoop-daemon.sh start journalnode exit ssh node4 cd /home/hadoop/hadoop2.7/sbin ./hadoop-daemon.sh start journalnode exit |
| 检查JournalNode是否正常 jps cd /home/hadoop/hadoop2.7/logs tail -n50 hadoop-root-journalnode-gyrr-centos-node-2.log |
3. 首次启动HDFS格式化
仅在一个NameNode所在节点初始化,且不启动NameNode
| exit cd /home/hadoop/hadoop2.7/bin/ ./hdfs namenode -format |
| 格式化成功日志 17/08/30 18:52:55 INFO common.Storage: Storage directory /opt/hadoop/tmp/dfs/name has been successfully formatted. |
| 检查JournalNode是否正常 jps cd /home/hadoop/hadoop2.7/logs tail -n50 hadoop-root-journalnode-gyrr-centos-node-2.log cd /opt/hadoop/jn/data/hdfs-cluster/current/ ls |
| 检查元数据文件是否生成正常(元数据目录:/opt/hadoop/meta) cd /opt/hadoop/meta/dfs/name/current ls |
4. 启动格式化过的NameNode
| ssh node0 cd /home/hadoop/hadoop2.7/sbin/ ./hadoop-daemon.sh start namenode jps exit |
5. 在未格式化的NameNode中拷贝格式化的元文件(保持格式化过的NameNode在运行中)
| ssh node1 cd /home/hadoop/hadoop2.7/bin/ ./hdfs namenode -bootstrapStandby exit |
| 检查元数据 cd /opt/hadoop/meta/dfs/name/current/ |
6. 格式化zkfc(在任意一个NameNode中执行)
| ssh node1 cd /home/hadoop/hadoop2.7/bin/ ./hdfs zkfc -formatZK exit |
7. 启动HDFS
l 停止所有服务(当前只有HDFS没有MapReduce),在node0上执行
| cd /home/hadoop/hadoop2.7/sbin/ ./stop-dfs.sh |
| Stopping namenodes on [node0 node1] node0: stopping namenode node1: no namenode to stop node2: no datanode to stop node3: no datanode to stop node4: no datanode to stop node5: no datanode to stop Stopping journal nodes [node2 node3 node4] node2: stopping journalnode node4: stopping journalnode node3: stopping journalnode Stopping ZK Failover Controllers on NN hosts [node0 node1] node0: no zkfc to stop node1: no zkfc to stop |
l 启动所有服务(当前只有HDFS没有MapReduce),在node0上执行
| cd /home/hadoop/hadoop2.7/sbin/ ./start-dfs.sh |
| Starting namenodes on [node0 node1] node0: starting namenode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-namenode-gyrr-centos-node-0.out node1: starting namenode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-namenode-gyrr-centos-node-1.out node5: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-datanode-GYRR-CentOS-Node-5.out node2: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-datanode-gyrr-centos-node-2.out node3: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-datanode-gyrr-centos-node-3.out node4: starting datanode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-datanode-gyrr-centos-node-4.out Starting journal nodes [node2 node3 node4] node4: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-journalnode-gyrr-centos-node-4.out node3: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-journalnode-gyrr-centos-node-3.out node2: starting journalnode, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-journalnode-gyrr-centos-node-2.out Starting ZK Failover Controllers on NN hosts [node0 node1] node0: starting zkfc, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-zkfc-gyrr-centos-node-0.out node1: starting zkfc, logging to /usr/local/hadoop-2.7.4/logs/hadoop-root-zkfc-gyrr-centos-node-1.out |
jps与节点规划表中的节点进行对比
部署规划:
|
|
NN |
DN |
ZK |
ZKFC |
JN |
RM |
DM |
| Node-0 |
1 |
|
1 |
1 |
|
1 |
|
| Node-1 |
1 |
|
1 |
1 |
|
|
|
| Node-2 |
|
1 |
1 |
|
1 |
|
1 |
| Node-3 |
|
1 |
1 |
|
1 |
|
1 |
| Node-4 |
|
1 |
1 |
|
1 |
|
1 |
| Node-5 |
|
1 |
|
|
|
|
1 |
五、 测试
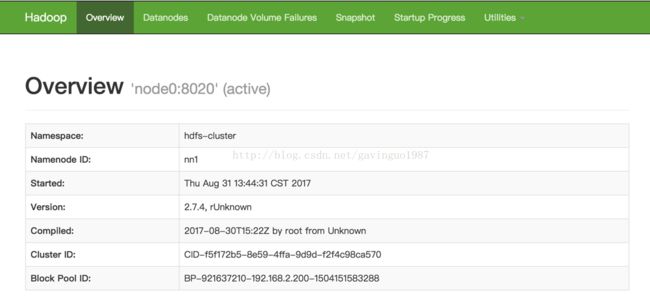
l 浏览器访问http://node0:50070/
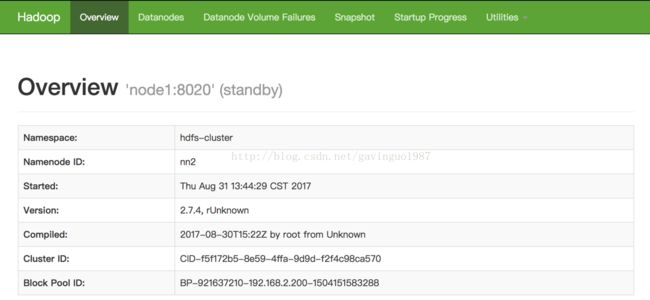
l 浏览器访问http://node1:50070/
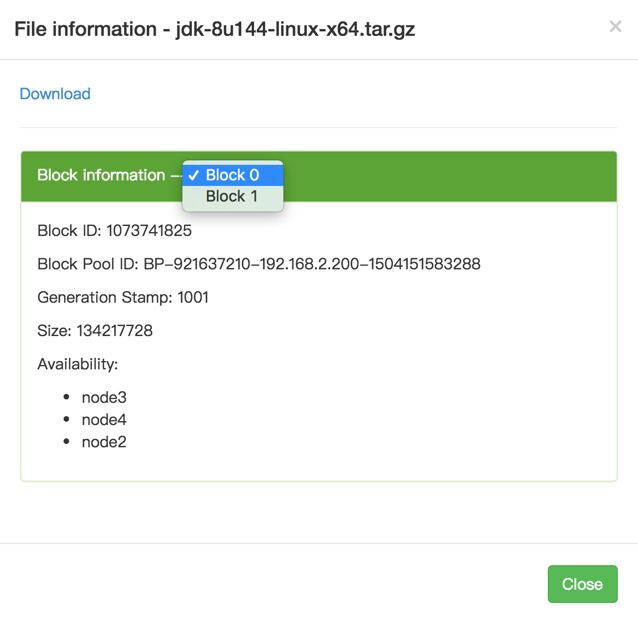
l 上传文件测试
| ssh node0 cd /home/hadoop/hadoop2.7/bin/ echo 1.create dir ./hdfs dfs -mkdir -p /usr/file echo 2.upload file ./hdfs dfs -put /share/jdk/jdk-8u144-linux-x64.tar.gz /usr/file |
l 访问上传文件
http://node0:50070/explorer.html#/usr/file
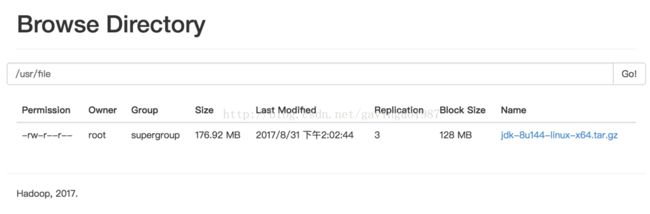
文件大小超过128MB,分为2个block保存