机器学习模型评估与改进: 交叉验证(cross validation)
文章目录
- 交叉验证
- 调用方法
- 优势和不足
- 注意事项:
- 分层k折交叉验证
- 交叉验证的更多变形
- leave-one-out交叉验证
- Shuffle-split交叉验证
- 组间的交叉验证
- 总结
以监督学习的众多算法为例,不管是分类还是回归,都有很多不同的算法模型,在不同的问题中,这些算法模型的表现是不同的。如何对模型的表行进行评估和改进呢?scikit learn网站给出了这样一个模型评估和改进的流程图:
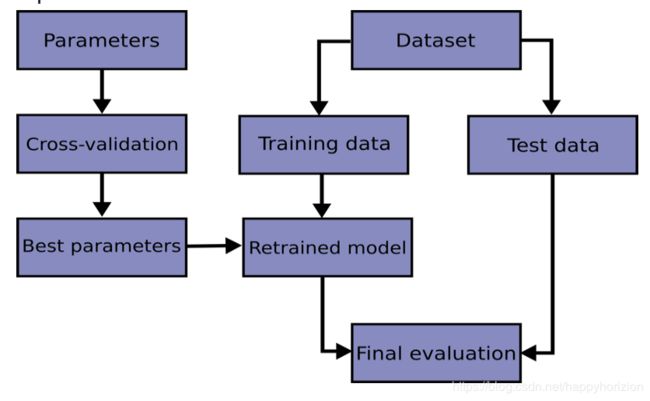
首先我们再来看看模型评估的过程,在模型训练时,我们首先可以用scikit learn的model_selection模块train_test_split函数对数据划分,分为训练集合和测试集合。对于验证模型的泛化能力,测试集合至关重要。
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
交叉验证
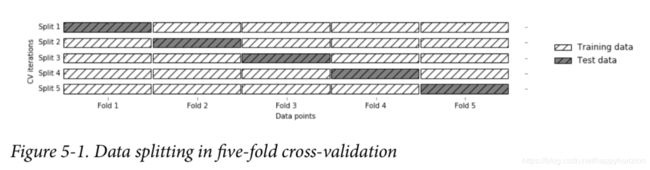
交叉验证是一种统计学方法,用于衡量算法表现是否稳定。在交叉验证里,数据不是简单按照某个比例分为训练集合和测试集合,而是将数据如下图做多次划分,并且基于这些划分,训练多个机器学习模型。这也就是所谓的k折交叉验证(k-fold cross validation),k通常为5或者10.
以5折交叉验证为例,数据首先被均匀地分为5份(“折”,fold),取其中一份作为测试集合,其他为训练集合,训练一个模型。之后,轮流地选择其中的一折作为测试集合,其他为训练集合,再依次训练模型。
调用方法
scikit-learn提供了非常简便的方法调用交叉验证。只需要从model_selection模块中加载cross_val_score函数就可以了。以鸢尾花数据集,logistic回归预测为例:
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris()
logreg = LogisticRegression()
scores = cross_val_score(logreg, iris.data, iris.target)
print("Cross-validation scores: {}".format(scores))
通常cross_val_score函数默认是3折交叉验证,运行后输出Cross-validation scores: [ 0.961 0.922 0.958]。 可以在cross_val_score() 函数中修改默认设置,例如改成5折交叉验证:
scores = cross_val_score(logreg, iris.data, iris.target, cv=5)
正确率为[ 1. 0.967 0.933 0.9 1. ]。平均来说,交叉验证的正确率是我们关心的指标,可以用scores.mean()得到,约为0.96。 96%的正确率,模型的性能还是比较好的,但是具体看每折交叉验证的正确率,从0.933到1之间变化,说明模型在不同测试集合上的表现并不是特别稳定,预测结果与测试数据的选择有关,当然,也有可能和测试集合数量比较少有关。
优势和不足
从上面每折验证的正确率和平均正确率就可以看出,交叉验证首先会抹平由于测试集合选择的“运气”带来的模型评价“失真”。在交叉验证的时候,数据集中的所有数据都有机会成为测试数据,这样可以更好地测试模型的泛化能力。
其次,交叉验证结果也可以说明模型对数据的敏感程度,例如上面的例子,模型的正确率在93.3%~100%之间,我们可以进一步推测,这个模型的正确率在更大的鸢尾花数据集上(如果我们有的话),正确率可能在90%~100%之间。这个范围还是挺大的,在新的数据上,模型的表现大致会在这个范围内。
另外一个好处是,通过交叉验证,数据集中所有的数据都得到了充分的利用。在用train_test_split函数划分模型的训练集合和测试集合时,通常会用75%的数据作为训练集合,25%的数据作为测试集合,在5折交叉验证时候,80%的数据用于训练,20%的用于测试,10折交叉验证的时候,90%的数据训练,10%的数据测试。显然,训练集合的数据越多,模型就会越精确,整体来说,交叉验证训练模型,会让模型的精度得到更好的提升。
交叉验证的不足之处主要是增加了计算开销。k折交叉验证,也就意味着模型要训练k次,比train_test_split要增加k倍的训练时间。
注意事项:
k折交叉验证不会返回唯一的一个模型
k折交叉验证的过程中,实际上训练了k个模型,所以该方法主要是用来测试这个模型在这个数据集合上的表现,并不是一个生成训练模型的方法,更准确地说是一个评价模型的方法。
分层k折交叉验证
k折交叉验证很好,但是有一种情况,k折交叉验证的效果就要大打折扣,就是如果数据集的标签都是连续排列的。例如iris数据集,如果标签是这样的:

那么在3折交叉验证的时候,每次训练和测试的数据,都是完全不同标签类型的,模型正确率可能只有0%左右了。如何改进呢?
分层k折交叉验证就是一个很好的选择,该方法将数据集先分成k折,然后再从每个k折中选择k折作为测试集合,如下图:
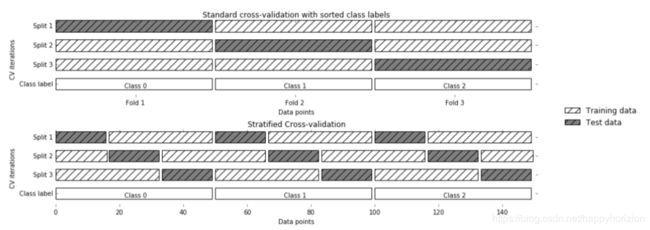
这样就可以在某种程度上保证,每次测试集合和训练集合都有各个类型的数据,特别是当数据分类的类型数量相差悬殊的情况。比如数据集合一共有1000个样本,900个都属于A类型,只有100个属于B类型。不过不用担心,scikit learn在分类问题中采用的就是这种分层的交叉验证策略。但是对于回归问题, scikit learn用的不是分层k折交叉验证,而是经典版本。这么做很有可能是因为回归问题与分类不同,分类是希望将各个不同(那么数量很少)区别开来,但是回归是希望得到大多数的规律。
交叉验证的更多变形
scikit learn提供了多种对交叉验证进行设置的参数。前面的例子中用到了cv这个参数,可以用来设置交叉验证的折数,对于一般的分类问题,指定cv的折数,scikit learn默认的分层交叉验证就很好用了。不过有时候,例如当我们只需要经典的k折交叉验证,我们可以加载model_selection模块的KFold函数。
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
之后可以把kfold赋给cross_val_score()函数中的cv参数:
cross_val_score(logreg, iris.data, iris.target, cv=kfold)
可以验证一下之前提到的,经典k折交叉验证在iris数据集上惨不忍睹的正确率为0是如何“做到的”
kfold = KFold(n_splits=3) print("Cross-validation scores:\n{}".format(cross_val_score(logreg, iris.data, iris.target, cv=kfold)))
得到Cross-validation scores: [ 0. 0. 0.]。可见,经典的k折交叉验证对于这样“排列”好的数据集上,的确是会造成非常错误的结果。改进的方法除了用model_selection模块的cross_val_score()函数,还可以在KFold函数中设置shuffle参数,例如:
kfold=KFold(n_splits=3, shuffle=True, random_state=0)
print(“Cross-validation scores: \n {}”.format(cross_val_score(logreg, iris.data, iris.target, cv=kfold)))
leave-one-out交叉验证
leave-one-out,顾名思义,就是一种特殊的k折交叉验证,每次留下来做测试集合的只有一个样本。这是一种非常耗时的交叉验证方法,特别是当数据集比较大的时候。但是对于小数据集,可能会给出更好的模型评估。
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
scores = cross_val_score(logreg, iris.data, iris.target, cv=loo)
print(“Number of cv iterations:”, len(scores))
print(”Mean accuracy: {:.2f}”.format(scores.mean()))
Shuffle-split交叉验证
这种交叉验证方法是最为灵活的一种数据集划分方法。
shuffle_split交叉验证是model_selection模块的ShuffleSplit( )函数实现,训练数据集合和测试数据集合按照train_set,test_set参数设置的比例在整个数据集中随机选择,n_iter参数设置的是交叉验证的数量。如下图展示的是train_size=5, test_size=2, n_iter=4的情形:

from sklearn.model_selection import ShuffleSplit
shuffle_split = ShuffleSplit(test_size=.5, train_size=.5, n_splits=10)
scores = cross_val_score(logreg, iris.data, iris.target, cv=shuffle_split)
print("Cross-validation scores:\n{}".format(scores))
根据这里的设置,随机选择50%的数据作为训练集合,50%的数据作为测试集合,训练10轮。当数据集特别大的时候,用这种方式训练比较好,不过需要注意的是,train_size+test_size不能大于1。
ShuffleSplit交叉验证也有对应的分层形式,是StraifiedShuffleSplit() 函数。
组间的交叉验证
另外一种很常见的交叉验证发生在数据中有分组,而且这些分组非常相关的情况下。例如对不同的面部表情图片进行分类,1数据采集的时候选择了100个不同的被试,每个被试都采集了多个不同表情,目前是要建立一个分类器,对不在数据集中的人的表情进行分类。可以用默认的分层交叉验证对分类器的性能进行评估,但是有可能同一个人的不同表情图片同时出现在测试集和训练集中,对于这种情况,模型测试的效果会比完全新人的数据要好(意味着如果测试集合中的图片和训练集合中的图片都属于同一个人的不同表情,这时模型的测试效果会比较好,但是对于不在数据集中的,或者测试集中的图像所属的人没有一张照片在训练集中,这时候模型在测试集上的表现会差很多)。为了很好的评估模型在新面孔上的泛化能力,我们需要保证在训练集和测试集上包含不同人的表情照片。
我们用GroupKFold()函数来实现这个需求,具体来说,
from sklearn.model_selection import GroupKFold
# create synthetic dataset
X, y = make_blobs(n_samples=12, random_state=0)
# assume the first three samples belong to the same group, # then the next four, etc.
groups=[0,0,0,1,1,1,1,2,2,3,3,3]
scores = cross_val_score(logreg, X, y, groups, cv=GroupKFold(n_splits=3))
print("Cross-validation scores:\n{}".format(scores))
上面代码段中,数据集中一共是12个样本,groups数列中的0,1,2,3是每个样本所属的分组号,指定分组号就是为了指定对应的数据属于同一个组,在划分测试集合和训练集合的时候,不要将同一组的数据分开。
这种情况在医疗数据中非常常见,例如经常会见到同一个病人的多个样本,训练模型后希望模型可以泛化到其他人的诊断上。类似地,在语音识别中也比较常见,通常训练的样本集合都来自于专门的数据集,是特定的一些人录制的,但是希望训练模型后应用在其他人的语音数据上。
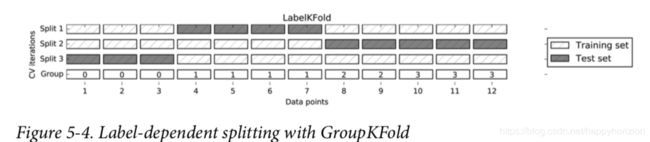
上图中就是group交叉验证的一个例子。
总结
交叉验证还有更多的变形,具体可以见scikit-learn的user guide. (https://scikit-learn.org/stable/modules/cross_validation.html) 。但是总的来说, KFold, StratifiedKFold, GroupKFold是最常用的几种形式。