Hadoop集群——(二)作业编写、打包、启动、查看
Hadoop集群——(二)作业编写、打包、运行、查看
Hadoop集群搭建好后,就可以将MapReduce作业提交到集群上运行了。下面以我自己编写的一个WordCount单词计数的程序为例,介绍一下如何在集群上进行作业的提交和运行。
1. 程序编写
我写了一个简单的WordCount.java文件,它实现了一个WordCount类,用于对文件中的单词进行计数,代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import java.util.*;
import java.lang.Integer;
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import java.net.URI;
import java.lang.Math;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.util.*;
import org.apache.hadoop.fs.FSDataInputStream;
public class WordCount extends Configured implements Tool {
public static class MyInputFormat extends FileInputFormat<NullWritable, Text> {
public RecordReader<NullWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
MyRecordReader myrecordreader = new MyRecordReader();
myrecordreader.initialize(split, context);
return myrecordreader;
}
}
public static class MyRecordReader extends RecordReader<NullWritable, Text> {
private long wordnumber = 0;
private NullWritable key;
private Text value = new Text();
private int process = 0;
private FileSplit filesplit;
private Configuration conf;
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
filesplit = (FileSplit)split;
conf = context.getConfiguration();
Path path = filesplit.getPath();
FileSystem fs = path.getFileSystem(conf);
FSDataInputStream in = null;
byte[] bytes = new byte[(int)filesplit.getLength()];
try {
in = fs.open(path);
IOUtils.readFully(in, bytes, 0, (int)filesplit.getLength());
String content = new String(bytes);
value.set(content);
} finally {
IOUtils.closeStream(in);
}
}
public boolean nextKeyValue() throws IOException, InterruptedException {
if(process == 0) {
process = 1;
return true;
} else {
return false;
}
}
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return key;
}
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
public float getProgress() throws IOException, InterruptedException {
if(process == 1) {
return (float)1.0;
}
return (float)0.0;
}
public void close() throws IOException {
}
}
public static class Map extends Mapper<NullWritable, Text, Text, Text> {
private int ans = 0;
private Text one;
protected void setup(Context context) throws IOException, InterruptedException {
InputSplit split = context.getInputSplit();
Path path = ((FileSplit)split).getPath();
int i = 1;
one = new Text(String.valueOf(i));
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while(context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
public void map(NullWritable key, Text value, Context context) throws IOException, InterruptedException{
StringTokenizer tokenizer = new StringTokenizer(value.toString());
while(tokenizer.hasMoreTokens()) {
String temp = tokenizer.nextToken();
context.write(new Text(temp), one);
}
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Iterator<Text> iter = values.iterator();
String wordans = "";
int ans = 0;
while(iter.hasNext()) {
String temp = iter.next().toString();
ans = ans + Integer.parseInt(temp);
}
wordans = String.valueOf(ans);
System.out.println("word:" + key.toString() + " count:" + wordans);
context.write(key, new Text(wordans));
}
}
public int run(String[] args) throws Exception {
Job job = new Job(getConf());
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(MyInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
//FileInputFormat.addInputPath(job, new Path(args[1]));
//FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean success = job.waitForCompletion(true);
return success ? 0:1;
}
public static void main(String[] args) throws Exception {
int ret = ToolRunner.run(new WordCount(), args);
System.exit(ret);
}
}
2. 代码编译
该Java程序的存放路径为/hadoop/hadoop-2.9.1/test/mapreduce/wordcount:
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# ll
total 20
drwxr-xr-x 2 root root 4096 Nov 10 07:49 ./
drwxr-xr-x 1 root root 4096 Nov 10 06:21 ../
-rw-r--r-- 1 root root 92 Nov 10 06:42 1.txt
-rw-r--r-- 1 root root 5231 Nov 10 07:37 WordCount.java
该路径下的1.txt是测试文件,内容如下:
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# cat 1.txt
hehehe
haha
apple
pear
peach
banana
orange
car
plane
chair
apple
car
car
haha
pear
car
car
将该测试文件上传至HDFS上:
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# hadoop fs -put 1.txt /wordcount
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# hadoop fs -ls /wordcount
Found 1 items
-rw-r--r-- 2 root supergroup 92 2018-11-10 08:08 /wordcount/1.txt
在该路径下创建文件夹WordCount:
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# mkdir WordCount
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# ll
total 24
drwxr-xr-x 3 root root 4096 Nov 10 07:53 ./
drwxr-xr-x 1 root root 4096 Nov 10 06:21 ../
-rw-r--r-- 1 root root 92 Nov 10 06:42 1.txt
drwxr-xr-x 2 root root 4096 Nov 10 07:53 WordCount/
-rw-r--r-- 1 root root 5231 Nov 10 07:37 WordCount.java
利用javac命令编译Java文件,其中的参数[-d path]指定了生成的class文件都存放在路径path下:
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# javac -d WordCount WordCount.java
Note: WordCount.java uses or overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
利用jar命令将class文件打包成jar包:
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# jar -cvf WordCount.jar -C WordCount .
added manifest
adding: WordCount$Map.class(in = 2478) (out= 1027)(deflated 58%)
adding: WordCount.class(in = 1928) (out= 961)(deflated 50%)
adding: WordCount$MyRecordReader.class(in = 2796) (out= 1300)(deflated 53%)
adding: WordCount$MyInputFormat.class(in = 1135) (out= 481)(deflated 57%)
adding: WordCount$Reduce.class(in = 2048) (out= 915)(deflated 55%)
其中,jar命令的参数格式如下:
jar {c t x u f }[ v m e 0 M i ][-C 目录]文件名...
其中{ctxu}这四个参数必须选选其一。[v f m e 0 M i ]是可选参数,文件名也是必须的。
-c 创建一个jar包
-t 显示jar中的内容列表
-x 解压jar包
-u 添加文件到jar包中
-f 指定jar包的文件名
-v 生成详细的报造,并输出至标准设备
-m 指定manifest.mf文件.(manifest.mf文件中可以对jar包及其中的内容作一些一设置)
-0 产生jar包时不对其中的内容进行压缩处理
-M 不产生所有文件的清单文件(Manifest.mf)。这个参数与忽略掉-m参数的设置
-i 为指定的jar文件创建索引文件
-C 表示转到相应的目录下执行jar命令,相当于cd到那个目录,然后不带-C执行jar命令
3. 启动作业
利用hadoop命令运行jar包,命令格式为:
hadoop + jar + jar包名 + main函数所在的class名 + 参数
在这个例子中,参数有2个,第一个是测试文件的路径,第二个是输出的结果所在的路径。运行的命令为:
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# hadoop jar /hadoop/hadoop-2.9.1/test/mapreduce/wordcount/WordCount.jar WordCount /wordcount/1.txt /wordcount/wordcount_result
4. 结果查看
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# hadoop fs -ls /wordcount/wordcount_result
Found 2 items
-rw-r--r-- 2 root supergroup 0 2018-11-10 08:09 /wordcount/wordcount_result/_SUCCESS
-rw-r--r-- 2 root supergroup 79 2018-11-10 08:09 /wordcount/wordcount_result/part-r-00000
root@fcf5acd99239:/hadoop/hadoop-2.9.1/test/mapreduce/wordcount# hadoop fs -cat /wordcount/wordcount_result/part-r-00000
apple 2
banana 1
car 5
chair 1
haha 2
hehehe 1
orange 1
peach 1
pear 2
plane 1
5. 作业运行状态查看
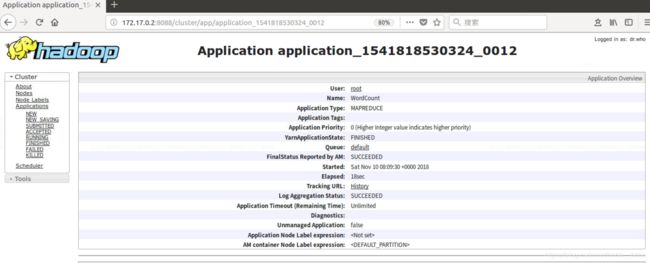
在浏览器中输入http://172.17.0.2:8080,可以在Web页面中看到刚刚运行的这个作业:

点击该application,可以看到该作业的具体运行情况: