MPI——实现梯形积分法
用MPI来实现梯度积分法
梯度积分法
我们可以用积分法来估计函数 y = f ( x ) y=f(x) y=f(x)的图像中,两条垂直线与 x x x轴之间的区间大小
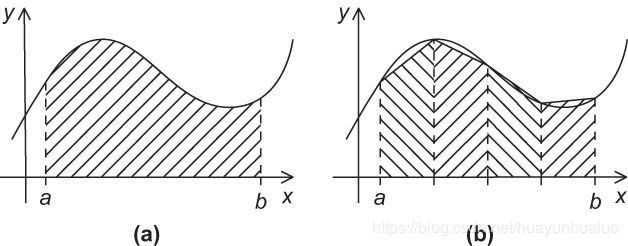
基本思想:将 x x x轴上的区间划分为n个等长的子区间。然后估计介于函数图像以及每个子区间内的梯形区域的面积。梯形的底边是 x x x轴的子区间,两条垂直边是经过子区间的端点垂直线。
那么梯形的面积
梯 形 的 面 积 = h 2 [ f ( x i ) + f ( x i + 1 ) ] 梯形的面积 = \frac{h}{2} [f(x_i)+f(x_{i+1})] 梯形的面积=2h[f(xi)+f(xi+1)]
由于n个子区间是等分的,因此如果两条垂直线包围区域的边界分别为 x = a x=a x=a和 x = b x=b x=b
h = b − a n h = \frac{b-a}{n} h=nb−a
因此,如果称最左边的端点为 x 0 x_0 x0,最右边的端点为 x n x_n xn,则有:
x 0 = a , x 1 = a + h , x 2 = a + 2 h , ⋯ , x n − 1 = a + ( n − 1 ) h , x n = b x_0 = a,x_1=a+h,x_2=a+2h,\cdots,x_{n-1} =a+(n-1)h,x_n=b x0=a,x1=a+h,x2=a+2h,⋯,xn−1=a+(n−1)h,xn=b
那么整个区域的面积为
S = h [ f ( x 0 ) 2 + f ( x 1 ) + ⋯ + f ( n − 1 ) + f ( x n ) 2 ] S = h[\frac{f(x_0)}{2} + f(x_1) +\cdots + f(n-1)+\frac{f(x_n)}{2}] S=h[2f(x0)+f(x1)+⋯+f(n−1)+2f(xn)]

因此一个串行程序的伪代码为:
/*Input a, b, n*/
h = (b - a)/n;
approx = (f(a) + f(b))/2.0;
for(i = 1;i <= n-1; i++) {
x_i = a + i * h;
approx += f(x_i);
}
approx = h * approx;
并行化梯形积分法
在划分阶段,通常尝试识别成尽可能多的任务,对于梯形积分法,我们可以识别出两种任务
- 获取单个矩形面积的任务
- 计算这些区域的面积和
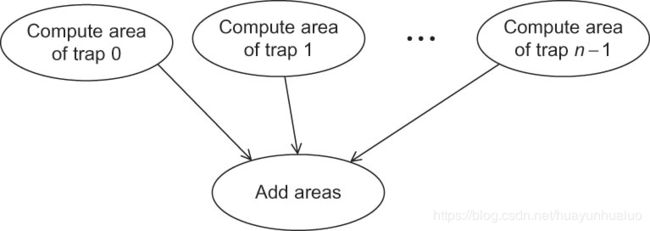
使用的梯度越多,估计值就越精确。当梯形的数目将超过核的数量,需要将梯度区域面积的计算聚合成组。为了实现这一目标一个很自然的地方是将区间 [ a , b ] [a,b] [a,b]划分成comm_sz个子区间。
程序的伪代码如下
Get a,b,n;
h = (b-a) / n;
local_n = n / comm_sz;
local_a = a + my_rank * local_n * h;
local_b = local_a + local_n * h;
local_integral = Trap(local_a, local_b, local_n, h);
if(my_rank != 0) {
Send local_integral to process 0;
}
else {
total_integral = local_integral;
for( proc = 1; proc < comm_sz; proc++) {
Receive lcoal_integral from proc;
total_integral += local_integral;
}
}
if(my_rank == 0) {
print result;
}
Trap函数是一个梯形积分法的串行实现。
为了区分局部变量和全局变量。局部变量只在使用他们的进程中有效,如果变量的所有进程中有效,那么该变量称为全局变量。
I/O处理
输出
虽然MPI标准没有指定那些进程可以访问哪些I/O设备,但是几乎所有的MPI实现都允许MPI_COMM_WORLD里的所有进程都能访问标准输出(stdout)和标准错误输出(stderr),所以,大部分的MPI实现都允许所有进程执行printf和fprintf
但是,大部分的MPI实现并不提供对这些I/O设备访问的自动调度,也就是说,如果多个进程试图写标准输出stdout,那么这些进程的输出顺序是无法预测的,甚至会发生一个进程的输出被另一个进出的输出打断的情况。
int main(void){
int my_rank, comm_sz, n = 1024, local_n;
double a = 0.0, b = 3.0, h, local_a,local_b;
double local_int, total_int;
int source;
MPI_Init(NULL, NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
h = (b-a)/n;
local_n = n / comm_sz;
local_a = a + my_rank * local_n *h;
local_b = local_a + local_n * h;
local_int = Trap(local_a, local_b, local_n, h);
if(my_rank != 0) {
MPI_Send(&local_int, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);;
}
else {
total_int = local_int;
for(source = 1; source < comm_sz; source ++) {
MPI_Recv(&local_int, 1, MPI_DOUBLE, source, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
total_int += local_int;
}
}
if(my_rank == 0) {
printf("With n = %d trapeziods. our estimate\n",n);
printf("of the integral from %f to %f = %.15e\n", a,b,total_int);
}
MPI_Finalize();
return 0;
}
梯形积分法MPI程序的Trap函数
double Trapp(double left_endpt, double right_endpt, int trap_count, double base_len) {
double estimate, x;
int i;
estimate = (f(left_endpt) + f(right_endpt))/2.0;
for(i = 1;i<=trap_count; i++) {
x = left_endpt + i * base_len;
estimate += f(x);
}
estimate = estimate * base_len;
return estimate;
}
使用不同的进程打印消息
#include 输出
Proc 4 of 6 > Does anyone have a toothpick?
Proc 0 of 6 > Does anyone have a toothpick?
Proc 1 of 6 > Does anyone have a toothpick?
Proc 5 of 6 > Does anyone have a toothpick?
Proc 3 of 6 > Does anyone have a toothpick?
Proc 2 of 6 > Does anyone have a toothpick?
or
Proc 2 of 6 > Does anyone have a toothpick?
Proc 4 of 6 > Does anyone have a toothpick?
Proc 0 of 6 > Does anyone have a toothpick?
Proc 5 of 6 > Does anyone have a toothpick?
Proc 1 of 6 > Does anyone have a toothpick?
Proc 3 of 6 > Does anyone have a toothpick?
这一现象产生的原因是MPI进程都在相互竞争,以取得对共享输出设备、标准输出stdout的访问。
输入
与输出不同,大部分的MPI实现只允许MPI_COMM_WORLD中的0号进程访问标准输入stdin。为了编写能够使用scanf的MPI程序,根据进程号来选取转移分支。
void Get_input(int my_rank , int comm_sz, double *a_p, double *b_p, int * n_p) {
int dest ;
if(my_rank ==0) {
printf("Enter a, b, and n\n");
scanf("%lf %lf %d",a_p, b_p, n_p);
for(dest =1 ;dest < comm_sz;dest++) {
MPI_Send(a_p,1,MPI_DOUBLE, dest, 0, MPI_COMM_WORLD);
MPI_Send(b_p,1,MPI_DOUBLE, dest, 0, MPI_COMM_WORLD);
MPI_Send(n_p,1,MPI_INT, dest,0, MPI_COMM_WORLD);
}
}
else {
MPI_Recv(a_p, 1 ,MPI_DOUBLE,0,0,MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(b_p, 1 ,MPI_DOUBLE,0,0,MPI_COMM_WORLD, MPI_STATUS_IGNORE);
MPI_Recv(n_p, 1 ,MPI_INT,0,0,MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
}
在主程序中调用
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
Get_input(my_rank, comm_sz, &a , &b, &n);
h = (b-a)/n;