京东广告算法架构体系建设--在线模型系统分布式异构计算演变 | 京东零售广告技术团队
一、现状介绍

算法策略在广告行业中起着重要的作用,它可以帮助广告主和广告平台更好地理解用户行为和兴趣,从而优化广告投放策略,提高广告点击率和转化率。模型系统作为承载算法策略的载体,目前承载搜索、推荐、首焦、站外等众多广告业务和全链路的深度学习建模,是广告算法算法创新和业务迭代发展的重要基石。
架构全景图:
1.平台能力:
1.高吞吐高并发:百亿PV,百万QPS
2.低延迟,高可靠:万亿次预估计算/秒,毫秒级延迟,99.99%
3.集群规模:1W+节点
4.迭代周期:3次/天
2.系统能力
1.模型规模:TB级模型预估
2.异构计算:CPU/GPU异构计算
3.在线学习:分钟级模型更新
4.实时图计算:亿级节点、百亿级边;分钟级图数据更新
5.层次化算力:实时计算、离线计算、近线计算
二、发展历程

广告在线模型系统发展大致分为三个主要阶段:
1、深度学习时代:通过组件化、平台化、配置化完成架构的统一和流程机制的规范化,解决迭代效率问题。
2、大模型时代:通过分布式分图计算架构解决模型规模和实效性的问题。
3、算力时代:通过层次化算力建设解决全链路算力协同的问题。
1、深度学习时代——架构统一/迭代效率
广告在线模型系统初期缺乏统一的系统架构和流程机制,随着Tensorflow开源,算法的离线调研能力大幅提升,对应的在线模型架构算法迭代效率问题日益凸显。主要面临的问题如下:
◦业务接入成本高:广告业务涉及的业务较多,包括搜索、推荐、首焦、站外,模型涉及到CTR模型、CVR模型、CPA模型。每个业务都要面临新加广告场景、新加/修改模型,都需要添加额外的开发支持,接入效率低成本高。
◦特征繁多,数据不统一,算法实验低效:1)特征来源较多,有商品特征、用户特征、请求特征,没有统一的数据使用规范。2)特征种类也比较多,每个业务用的特征也比较独立,不利于复用。
◦算法和工程耦合:算法模型强依赖算法服务,模型结构修改都要带来服务修改,影响模型迭代。缺乏配置化导致算法扩展困难。
为了解决以上问题,我们将整体框架进行模块化升级,抽象出三个核心模块:
◦模型接入服务:负责流量管控,统一流量接入规则,与业务逻辑解耦。
◦特征计算服务:负责数据管理和特征提取,统一数据接入规则。
◦模型推理服务:负责模型推理、更新和落日志,统一模型接入规则。
1.1 模型接入
模型接入包含三大功能:
◦流量路由:流量路由的核心是进行动态流量识别,根据配置动态构建语法树,将流量映射到语法树中,从而做到识别流量全路径,包括流量从哪里来、到哪里去。当有新的流量进入或着加入新的模型,可在语法树中添加或修改叶节点,实现动态路由。同时在分层实验中,使用语法树,也可实现流量分层,增加小流量试验的并发度,提升流量使用效率。
◦流量分发:根据流量路由结果进行分发,针对广告队列较多的情况,会将请求进行拆分,并行请求特征和模型推理,实现并行加速。
◦流量防护:对上游来说,通过流量路由拦截异常流量。对下游来说,通过实时监控下游负载,实现动态负载均衡,拦截超负载流量,保护下游服务的安全。

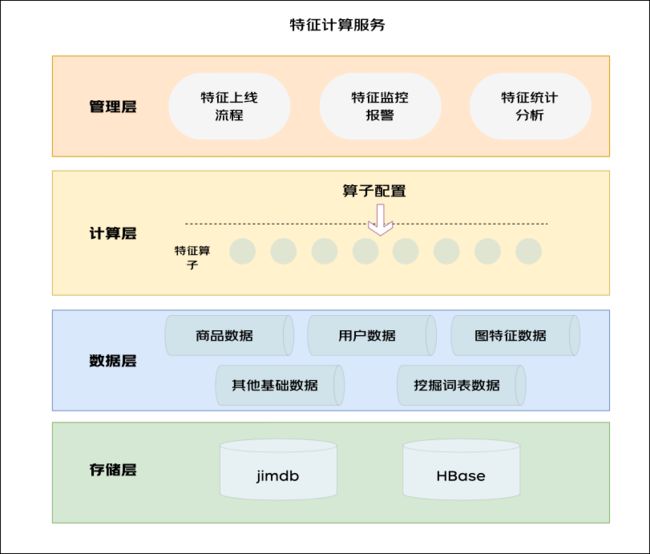
1.2 特征计算
特征计算包含两大功能:
◦数据管理:1、支持多类型数据源,包括三类:1)解析请求获取请求中的原始特征。2)本地数据支持特征词表获取离线特征。3)远程数据请求用户、商品等服务获取用户商品的实时特征。2、数据统一:通过特征转换统一特征格式,方便模型进行特征解析。
◦特征计算:将特征计算算子化,通过注册类的方式实现配置化,提升特征开发效率和复用效率。
1.3 模型推理
为了方便算法迭代,将架构拆分成两层,通过分层的设计,将模型和服务解耦,解决架构和模型迭代冲突的问题,提升模型迭代效率。
◦推理引擎层:推理引擎支持模型推理加速,目前支持多种推理引擎(TensorFlow、TensorRT、FasterTransformer等)
◦服务层:负责消息处理、特征日志、模型管理。
▪特征日志:支持落实时请求级的特征日志,通过离线拼接生成训练样本。
▪模型管理:通过NormGuard机制对训练模型进行校验,防止将不合规模型推到线上。

1.4 总结
架构上,通过以上服务化、单元化、配置化的升级,实现更高层级的抽象,实现一套架构支持所有算法业务。规范上,实现流量、数据、模型统一标准化。降低算法实验难度,整体迭代周期从周级别提升到天级别,极大提升了算法的迭代效率。
第一阶段的在线模型系统升级,将业务开发由无序到有序,架构从散乱到统一,奠定在线模型系统的基础,也为后续的架构发展提供更多可能。
2、大模型时代——模型规模/时效
平台化加速了模型迭代的同时,业界和广告内部也进入大模型的探索阶段,落地期间遇到模型复杂、参数规模大、时效性低等问题,大模型对算力的需求变得迫切。
◦模型复杂:深度模型的引入极大加速模型的发展,同时也带来模型复杂度的指数提升,以Transfomer为代表的全新神经网络框架,奠定了大模型的算法架构基础,复杂度的提升对模型计算提出更高的要求。
◦参数规模大:用户的增长,商品数量的扩展,带来数据量的爆炸,模型为了更好的模拟现实,参数量也成爆炸性增长。从广告场景内看,算法模型的参数规模也从十亿向着百亿、千亿发展,参数规模的增长对模型存储、IO提出了更高的要求。
◦时效性低:这个阶段模型的更新周期普遍在天级别,实效性较低,尤其在大促人货场发生快速变化的时候,模型更新跟不上用户、商品的变化,会带来搜索/推荐效果折损。
针对以上问题,我们基于离在线一体化设计研发分布式分图计算架构提升算力水平,支持更大参数规模的模型,同时支持OnlineLearning进一步提升时效性,同时在引入图计算提升模型表达能力。
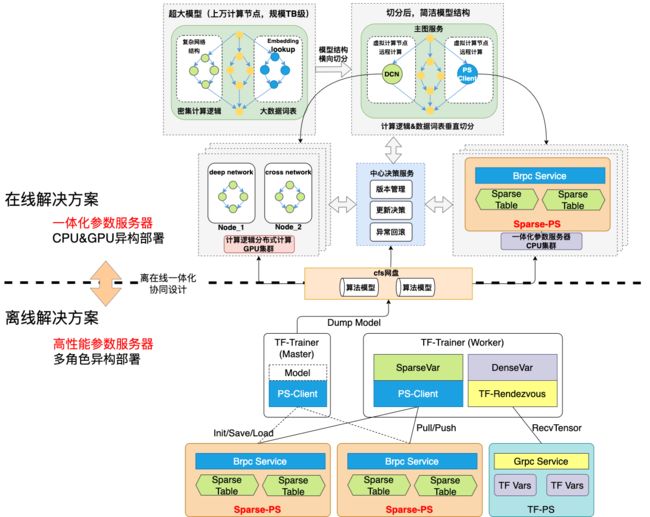
2.1 分布式分图计算架构
1.计算分层:分析复杂的模型网络拓扑结构,基于计算密集逻辑&数据I/O密集进行计算分层
2.存储分层:稀疏&稠密参数分层,充分利用CPU/GPU存储特点
3.离在线一体算力协同:提升模型规模和实效性,做到业界先进水平
效果:
1.在线算力提升10倍+,离线训练性能提升1倍+
2.搜索排序模型参数规模扩大8倍,点消+3%。推荐排序模型升级百G大模型助力算法收益点消+8%。
2.2 OnlineLearning
1.支持增量更新:提供参数增量更新解决方案,更新间隔由天级别缩短为分钟级别。
2.架构高可用,支持快速回滚

效果:
1.系统支持实时流式训练,分钟级别的线上模型增量更新。
2.广告搜索业务双十一大促期间点消共增长+10.47%。
2.3 图计算
模型为了挖掘用户和商品之间的关系,引入实时图关系数据,提升模型表达能力。
1.采用计算和存储分离架构,结构清晰,利于扩展
2.分布式集群存储,毫秒级延迟计算
3.支撑大规模动态图存储,分钟级更新

效果:
1.支撑十亿级节点百亿级边异构图存储的落地
2.多应用场景:推荐我的京东图建模全量上线,点消+3%;推荐首页召回小流量上线,点消+2%。
2.4 总结
分布式分图计算在模型系统平台化的基础上拓展模型计算能力,通过将内存、IO、CPU、GPU等计算资源协同处理实现异构计算能力,通过软硬件协同的方式极大提升GPU的利用率(具体参见“京东广告算法架构体系建设–高性能计算方案最佳实践”),释放模型预估的算力的同时提升模型时效性。
3、算力时代——算力协同
分布式分图计算和GPU硬件的引入横向加速了单模块模型计算,但是随着模型数据和复杂度进一步提升,暴露了更大的算力不足问题,单模块的算力释放已无法满足模型需求。在纵向的全链路算力协同和应用上也面临新的问题:
◦硬件资源不一致,木桶效应:线上机器硬件不一样,比如不同的机器CPU型号不一致导致算力不平衡
◦系统耦合,算力无法充分释放:目前模型计算集中在粗排、精排阶段,在整体耗时的约束下,无法充分发挥算力。
为了解决算力协同的问题,我们的区别前面的优化手段,从算法算力架构一体化融合设计优化角度出发,提出新一代工业化深度学习算法架构体系。整个体系包括两部分,分布式分图计算是基座,通过离在线一体和软硬结合的方式实现算力分层,在此算力架构基础上,结合核心算法场景,对系统算力进行了进一步层次划分,算法算力深度结合,落地广告营销多个场景。
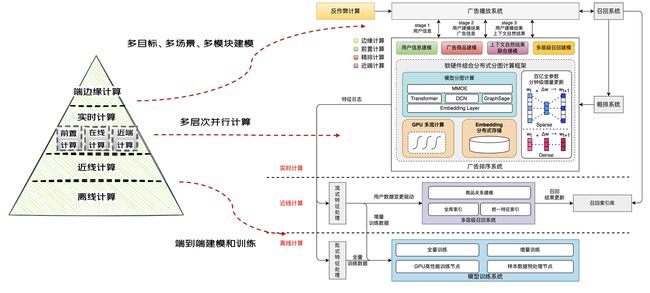
3.1 前置计算

精排用户实时行为建模问题,是业界通用的难点问题,行为序列规模的天花板在百级别, 存在严重的算力瓶颈。针对这一问题,我们的做法是算法和架构深度融合,在算法层面,扩充实时建模规模至千级别,架构层面,通过分图架构拆分精排链路增加前置计算层的方法,进一步实现了算法算力的分配,效果非常显著,在耗时0增长的同时,用户实时建模达到千级别,搜索点消+6%。
3.2 近线计算

在召回场景业界通用的难题是在大规模候选集上实现全库策略检索,从算法层面上解决召回链路和后链路建模不一致问题,我们的方法是通过增加近线计算层,协同特征融合、深度模型端到端建模,实现了离线和在线的进一步算力再分配,实现基于深度模型的全库检索能力,与业界先进水平持平,推荐点消+3%。
3.3 算力动态分配
为了降低机器不同带来的算力不平衡,我们引入多目标分级反馈负载均衡策略:


效果:
共计优化机器资源9000C+。
3.4 总结
面对单模块算力再次不足的问题,从纵向全链路算力协同方面,将算力进行精细化分层,通过实时计算、近线计算、离线计算打通,优化算力分配,拓展算力空间。
三、总结展望
广告在线模型系统经过三个阶段的发展和实践,有力的支撑了多条业务线的快速迭代。为了进一步优化算力,提升算力协同,计划强化动态算力分配机制,根据流量价值和用户分层进行算力动态分配,实现有限资源的收益最大化。

动态算力分配策略包括三类:
◦召回控制:通过控制召回分支及召回个数调控算力
◦队列控制:通过控制物料排序个数调控算力
◦模型控制:通过使用算法消耗不同的模型进行打分调控算力
未来,我们会继续围绕算法、算力、架构一体化的思维去不断优化和提升架构计算性能,提升业务迭代效率。
作者:京东零售 齐浩
来源:京东云开发者社区 转载请注明来源