深度学习笔记:推理服务
在线推理服务
- 解决的问题
- 样本处理
- 特征抽取(生成)
-
- 特征抽取过程
- 特征定义
-
- 通用定义
- 具体定义
- 特征抽取加速
- Embeding查询
- NN计算
-
- DL框架
- 计算优化
-
- 图优化
- 量化优化
- 异构计算
- CodeGen
- 总结
- 参考资料
解决的问题
模型训练解决模型效果问题,模型推理解决模型实时预测问题。推理服务是把训练好的模型部署到线上,进行实时预测的过程。如阿里的RTP系统
顾名思义,实时预测是相对于非实时预测(离线预测)而言,非实时预测是将训练好的模型参数拆分后保存到在线(通常kv的形式),当请求到来时直接进行kv查询,查询本身是实时的,但是没有实时计算过程,也就是查到就有结果,查不到就没有结果。因此效果会没有实时预测那么好。
推理服务主要关注的是实时性,解决实时性问题,则产生一系列问题需要解决,包括高并发、可用性、稳定性、通用型、资源利用优化等问题。后续会针对问题和解决方案逐一展开讨论。
典型的推理服务可以划分为四个阶段:样本处理、特征抽取、Embedding查询、NN计算
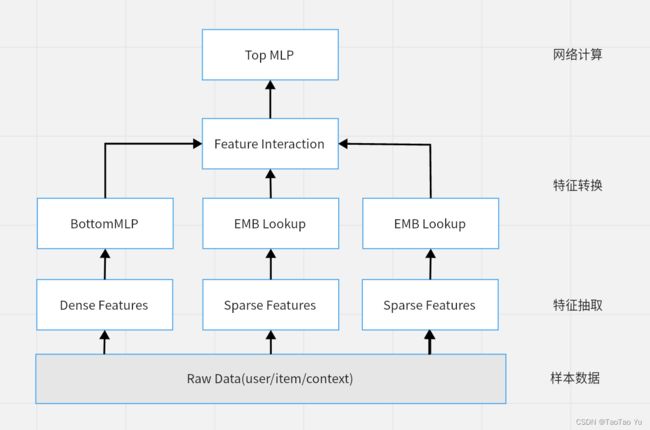
样本处理
样本处理是根据线上用户行为(如加购、收藏、浏览等)打点、预测结果(可能感兴趣、可能购买等)打点,获取模型训练所需要的原始数据的过程。一般是在离现阶段批量完成,涉及大量的用户在线行为join操作,不同来源的用户行为拼接的操作。
特征抽取(生成)
特征抽取是将样本数据转化为模型训练所需的数据表达形式的过程,也称之为特征生成。
特征一般分为Sparse(稀疏)特征和Dense(稠密)特征。
特征又可以分为:Item(商品/物料)特征、User(用户)特征、Context(上下文)特征、Combine(组合)特征、Sequence(序列)特征等,Sequence特征又可以划分为User Sequence和Item Sequence特征。
特征抽取过程
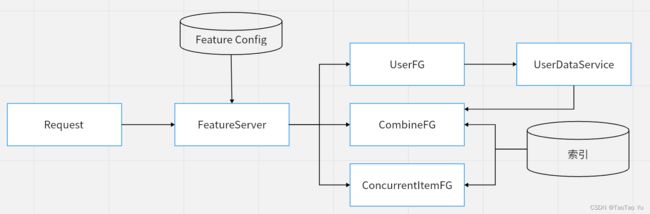
特征抽取也称为特征生成(Feature Generate),是一系列的规则定义和实现。通过训练和推理使用同一套特征抽取逻辑,从而保证模型在离线效果的一致性。
特征定义
通用定义
将特征抽取过程抽象出一系列具体规则,算法同学只需要按照规则定义选择合适的特征生成类,完全不需要做特征抽取类的开发。具体可以参考阿里开源推荐框架EasyRec中的特征定义
具体定义
将特征抽取过程通过接口暴露给算法同学,可以对具体模型复用已有的特征抽取类实现,也可以随时开发新的特征抽取类。具体实现方式在深度学习笔记:特征抽取(待完成)中详细介绍
特征抽取加速
每次请求对应具体一个用户,因此对User特征,只需要进行一次抽取。用户行为变化比较快,实时性要求高,一般user特征或者user数据会以服务化方式实时获取。
每次请求对应一系列Item,因此Item特征可以通过并行抽取加速,可以按照Item抽取,也可以按照Field抽取实现。具体实现和区别在深度学习笔记:特征抽取(待完成)中介绍。
item数据一般分全量/批量/实时更新,全量和批量数据走索引方式定期更新,实时数据一般是直接发送到在线内存,定期merge到增量/全亮版本中。
这里提到了索引的存储方式,当然也可以用LRU cache或其他方式实现,在深度学习笔记:特征抽取(待完成)中会继续展开讨论。
Embeding查询
Embedding是对Sparse特征抽取后的Sign值(暂且称之为Sign值吧),查询Embedding表的过程,一般称之为EmbeddingLookup操作。具体Embedding的原理在深度学习笔记:Embedding查询(待完成)部分再详细介绍。
这里需要知道每个Sparse特征对应一张Embedding表,所有Sparse特征做EmbeddingLookup之后的结果,会和Dense特征拼接(Concat)后作为网络层的输入,拼接的顺序一般是由FeatureConfig中的文件决定,当然要确保训练和推理时使用的FeatureConfig文件是完全一致的。

这里只是对Sparse特征的操作,对于稠密(Dense)特征和稀疏(Sparse)特征区别,这篇文章介绍的已经比较清楚
NN计算
深度模型最关键的步骤是网络计算(Neural Network),也是图计算过程。
DL框架
目前深度学习框架已经非常多,常见的如Tensorflow,Caffe,MaxNet,PyTorch等
可以参考常见框架对比
计算优化
图优化
以Tensorflow为例,基础的图优化包括ConstFolding(常量折叠)、CSE(公共子图消除)、子图消除、子图预计算等,具体可以查看Tensorflow源码实现,更多内容会在深度学习笔记:NN计算(待完成)部分详细展开
量化优化
简单说就是将深度模型中间参数/权重的浮点数(float32)转换成float16、uint8、int8,保持模型输入和输出的浮点数,通过损失推理精度为代价,实现减小模型占用内存大小,同时加速推理计算过程的效果。
也可以参考深度学习模型量化文章
异构计算
异构计算是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。具体就是除CPU外,使用GPU,FPGA进行深度模型网络计算加速。
推理服务一般可以通过TensorRT来实现GPU推理加速,后续通过独立章节展开描述
CodeGen
将运行时解释的东西提前到编译时解决。将运算描述转换成运算代码,这个过程便是 codegen。简单说将一种语言通过转化成IR(中间表达)语言,通过编译自动优化,最终实现性能和通用型的整体提升。
这是一个相对比较深入的优化方式,目前互联网公司在深度学习领域实践落地的方案相对比较少。
典型实现是TVM,具体可以参考阿里推理平台RTP中的CodeGen实践
总结
本文简单阐述了推理服务的几个重要步骤:
- 特征抽取
- Embedding查询
- NN图计算
以及各个步骤遇到的常见问题和基本解决思路。但问题远不止这些,如
- Embedding是如何产生的?为什么Embedding是查表操作?
- 特征抽取如何实现的,特征抽取按列(Field)、按行(Item)进行有什么差别?
- 推理引擎和搜索引擎架构差异是什么?模型图如何实现分布式计算?
- 在线特征、网络参数和物料数据是如何存储的,如何更新的?更新过程如何保持一致性?
- 超大模型如何在线部署的?参数服务器(Parameter Server)是如何工作?
- 异构设备之间是如何通信的?如何解决异构设备存储压力,发挥异构计算能力?
- 面对不同的业务场景、流量大小、流量变化,资源如何分配的?如何避免资源闲置和可用性不足问题?
- …
这样的问题还可以列举出很多,每一个问题的解决,都需要花费数月(甚至几年)的人力时间来解决,但深度学习领域技术在迭代、业务需求在变化,而技术的价值是服务于业务需求。
总而言之,短期方案不能彻底解决需求痛点,长期方案可能已经不适应新的业务需求,这就对系统架构设计提出了非常高的要求。
声明:本人小码农一枚,如果有言语表达不准确,资料引用不当之处,欢迎指正和交流,一起学习进步!
参考资料
- https://developer.aliyun.com/article/674182
- https://developer.aliyun.com/article/674175
- https://github.com/alibaba/EasyRec
- https://tvm.apache.org/docs/
- https://www.cnblogs.com/bonelee/p/14781693.html
- https://github.com/tensorflow/tensorflow/tree/master/tensorflow/core/grappler/optimizers
- https://blog.csdn.net/lingpy/article/details/110008883
- https://blog.csdn.net/qq_46244851/article/details/109412969