Tensorflow入门第一步
说明:
这个学习代码来自于Google的COLAB, 原链接点击here.
课程目的:
1、了解Tensorflow的基本概念
2、用TEnsorflow自带的逻辑回归算法预测房价中位数
3、利用均方根误差RMSE来评估模型预测准确度
(如果不清楚RMSE是什么,请点击此处看我的另一篇博客)
4、通过调整超参数来提高模型的准确度
代码下载点击此处

如果报如下错误:
ModuleNotFoundError Traceback (most recent call last) ModuleNotFoundError: No module named 'numpy.core.multiarrayumath'
请执行命令:
!pip install --upgrade --force-reinstall numpy==1.14.5 !pip install --upgrade --force-reinstall pandas==0.22.0
模型训练
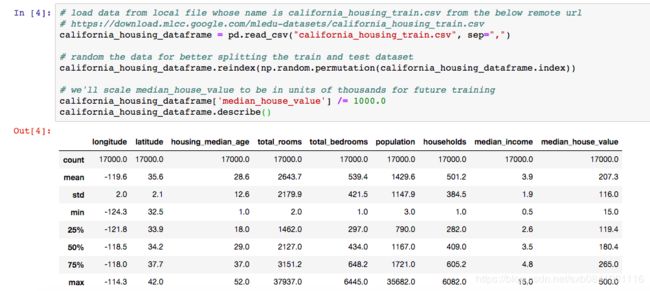
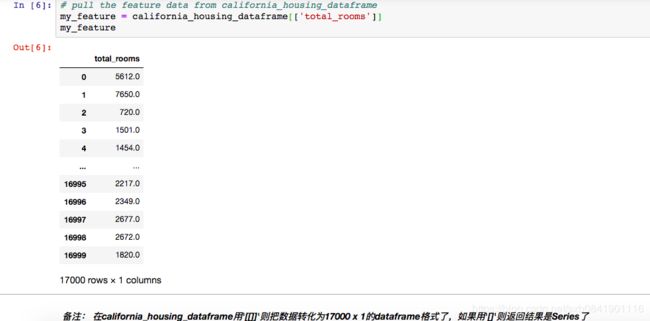
我们这个模型主要是预测房子的median_house_value,那么这个数据就是我们的目标值。为了方面观察,我们只选择其中的一个特征,total_rooms.由于我们这个数据是基于城市中的街区的,那么这个total_rooms这个特征就这个街区的房子总数
第一步: 定义特征和配置特征列
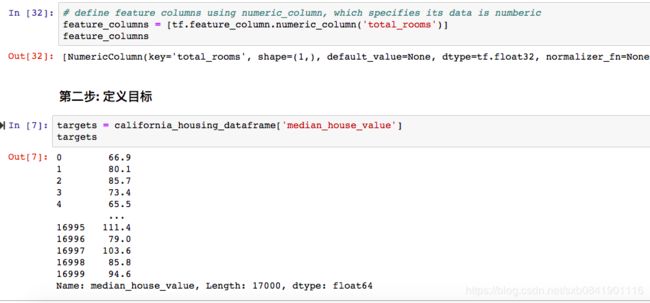
为了将我们的数据映射到tensorflow, 我们需要指定特征的数据类型,一般在tensorflow中由2种数据类型:分类类型和数值类型,分类类型一般用one-hot方式进行编码,如果特征是浮点或者整型,一般都用数值类型。由于我们total_rooms是数值,我们就用数值类型
第三步: 选择线性回归模型(LinearRegressor)¶
我们使用线性回归模型,主要用梯度下降法来训练模型,不了解梯度下降法的可以点击此处,在tensorflow已经有实现的优化器GradientDescentOptimizer。 此外,为了防止在模型训练中防止梯度爆炸式的降低,一般通过clip_gradients_by_norm来限制。

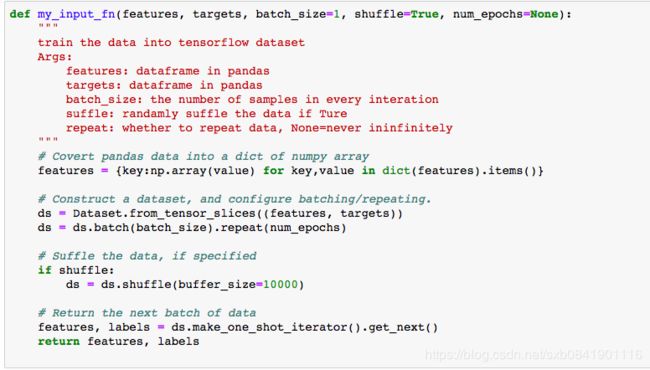
第四步: 定义输入函数
输入函数input_function主要是用来把我们的数据导入到模型中,在这个函数中我们可以根据模型的需要对数据进行预处理,比如批量处理、随机打乱、重复等等。把数据处理成tensorflow数据需要的格式。 这个模型中训练数据主要分为以下几步:
1、我们把pandas中dataframe数据转换为numpy数组的字典形式,然后调用tensorflow的数据接口构造tensorflo需要的dataset对象,根据批量训练大小(batch_size)分为若干份,并确定要迭代的具体次数
2、根据参数shuffle是否True,我们看在模型训练过程中是否需要将数据打乱,buffer_size参数指定shuffle随机抽样的数据集的大小。
3、我们的输入方法生成一个迭代器,每次生成模型下次训练时候的数据集
第五步: 训练模型
在tensorflow中训练模型一般用方法train,把输入函数作为参数传递进去

第六步: 评估模型
在模型训练过程中,我们要了解训练的情况,看看我们的模型能否在训练集上表现良好。 所以我们在训练中打印出均方误差和均方根误差,来观察模型的泛化能力。 在后期的练习中,我们会把数据分为训练集和测试集,更能反馈模型的普适性。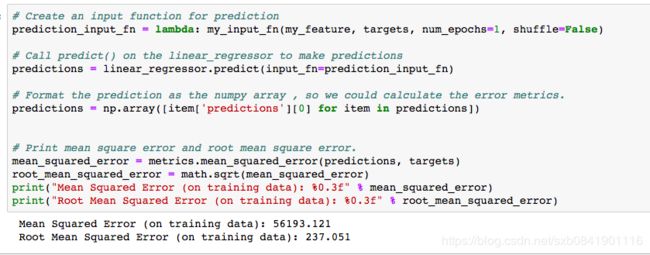
我们得到的均方根误差为237和均方差误差为56193,那么这个数字能说明我们的模型好坏吗? 我们选择用RMSE,因为MSE和我们的数据不在一个量纲上。 利用这个值我们和最大最小值的差距进行比较
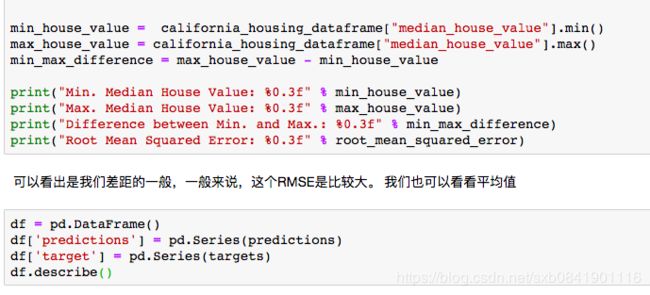
我们可以看出这个线相对数据来说,比较遥远。 通过上面的一些方法,我们就可以对模型做一个基本健康性的检查。
封装我们的模型,进行调整超参数
def train_model(learning_rate=0.000001, steps=100, input_feature='total_rooms', batch_size=1 ):
"""
Trains a linear regression model of one feature.
Args:
learning_rate: A float, the learning rate
steps: a non-zero 'int',the total number of training steps.
input_feature: A `string` specifying a column from `california_housing_dataframe` to use as input feature.
batch_size: A non-zero `int`, the batch size.
"""
periods = 10
steps_per_period = steps / periods
my_label = "median_house_value"
my_feature = input_feature
# extract the feature and targets from dataframe
features_data = california_housing_dataframe[[my_feature]]
targets = california_housing_dataframe[my_label]
# define the model with feature_columns and optimizer
feature_columns = [tf.feature_column.numeric_column(my_feature)]
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(clip_norm=5, optimizer=my_optimizer)
linear_regressor = tf.estimator.LinearRegressor(optimizer=my_optimizer,
feature_columns=feature_columns
)
# define the input function for training and prediction
training_input_fn = lambda: my_input_fn(features=features_data, targets=targets, batch_size=batch_size)
prediction_input_fn = lambda: my_input_fn(features=features_data, targets=targets, batch_size=batch_size, num_epochs=1,
shuffle=False)
# Set up to plot the state of our model's line each period.
plt.figure(figsize=(15, 6))
plt.subplot(1, 2, 1)
plt.title("Learned Line by Period")
plt.ylabel(my_label)
plt.xlabel(my_feature)
sample = california_housing_dataframe.sample(n=300)
plt.scatter(sample[my_feature], sample[my_label])
colors = [cm.coolwarm(x) for x in np.linspace(-1, 1, periods)]
# Train the model, but do so inside a loop so that we can periodically assess
# loss metrics.
print("Training model...")
print("RMSE (on training data):")
root_mean_squared_errors = []
for period in range(0, periods):
linear_regressor.train(input_fn=training_input_fn,
steps=steps_per_period
)
# Call predict() on the linear_regressor to make predictions
predictions = linear_regressor.predict(input_fn=prediction_input_fn)
# Format the prediction as the numpy array , so we could calculate the error metrics.
predictions = np.array([item['predictions'][0] for item in predictions])
# Print mean square error and root mean square error.
mean_squared_error = metrics.mean_squared_error(predictions, targets)
root_mean_squared_error = math.sqrt(mean_squared_error)
root_mean_squared_errors.append(root_mean_squared_error)
# Occasionally print the current losss
print('Period: %02d : %0.2f' % (period, root_mean_squared_error))
# Finally, track the weights and biases over time.
# Apply some math to ensure that the data and line are plotted neatly.
y_extents = np.array([0, sample[my_label].max()])
weight = linear_regressor.get_variable_value('linear/linear_model/%s/weights' % input_feature)[0]
bias = linear_regressor.get_variable_value('linear/linear_model/bias_weights')
x_extents = (y_extents - bias) / weight
x_extents = np.maximum(np.minimum(x_extents,
sample[my_feature].max()),
sample[my_feature].min())
y_extents = weight * x_extents + bias
plt.plot(x_extents, y_extents, color=colors[period])
print("Model training finished.")
print("Final RMSE (on training data): %0.2f" % root_mean_squared_error)
# Output a graph of loss metrics over periods.
plt.subplot(1, 2, 2)
plt.ylabel('RMSE')
plt.xlabel('Periods')
plt.title("Root Mean Squared Error vs. Periods")
plt.tight_layout()
plt.plot(root_mean_squared_errors)
# Output a table with calibration data.
calibration_data = pd.DataFrame()
calibration_data["predictions"] = pd.Series(predictions)
calibration_data["targets"] = pd.Series(targets)
display.display(calibration_data.describe())
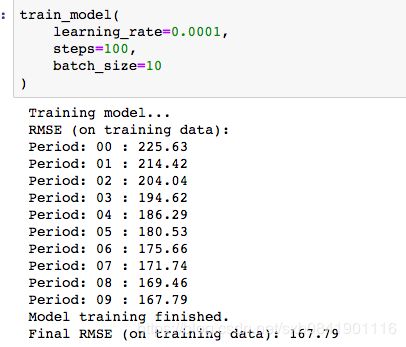
在上面不断调节超参数,就会看到不同曲线。 如果RMSE是一条不断下降的曲线,那么说明模型的效果会更好。
一些调参经验(来自于Google) 模型调整是否有标准启发式?
这是一个常见问题。简而言之,不同超参数的影响是与自己的数据有关。一些通用调整参数的规则:
训练误差应该首先急剧下降,并且随着训练收敛,最终应该稳定下来。
如果训练没有收敛,请尝试延长训练时间。
如果训练误差减慢得太慢,提高学习率可能会帮助它更快地减少。
但是,如果学习率太高,有时可能会发生完全相反的情况。如果训练误差变化很大,请尝试降低学习率。
较低的学习率加上较大的步骤数或较大的批量大小通常是一个很好的组合。 非常小的批量大小也会导致不稳定。首先尝试更大的值,如100或1000,并减少直到看到退化。
同样,永远不要严格遵循这些经验法则,因为效果与数据有关。始终进行实验和验证。