独家 | 手把手教你用R语言做回归后的残差分析(附代码)

作者:Abhijit Telang
翻译:张睿毅
校对:丁楠雅
本文约2600字,建议阅读10分钟。
本文介绍了做残差分析的方法及其重要性,以及利用R语言实现残差分析。
在这篇文章中,我们通过探索残差分析和用R可视化结果,深入研究了R语言。
残差本质上是当一个给定的模型(在文中是线性回归)不完全符合给定的观测值时留下的gap。
医学中的病理学发现的残留分析是一个形象的比喻。人们通常用代谢残留水平来作为衡量药物吸收的指标。
残差是用于建模的原始值与作为模型结果的对于原始值的估计之间的差异。
残差=y-y-hat,其中y是初始值,y-hat是计算值。
期望这个错误尽可能接近于零,并且通过残差找到任何异常值。
找到异常值的一个快速方法是使用标准化残差。第一种方法是简单地求出残差与其标准差的比值,因此,任何超过3个标准差的情况都可以被视为异常值。
## 标准化残差-相对于其标准偏差的比例残差
residueStandard<-rstandard(lmfit)
df[residueStandard>3,]
以下是得到的结果:
days.instant days.atemp days.hum days.windspeed days.casual
442 442 0.505046 0.755833 0.110704 3155
456 456 0.421708 0.738333 0.250617 2301
463 463 0.426129 0.254167 0.274871 3252
470 470 0.487996 0.502917 0.190917 2795
471 471 0.573875 0.507917 0.225129 2846
505 505 0.566908 0.456250 0.083975 3410
512 512 0.642696 0.732500 0.198992 2855
513 513 0.641425 0.697083 0.215171 3283
533 533 0.594708 0.504167 0.166667 2963
624 624 0.585867 0.501667 0.247521 3160
645 645 0.538521 0.664167 0.268025 3031
659 659 0.472842 0.572917 0.117537 2806
当然,我希望我的模型是无偏的,至少我想这样。因此回归线两边的任何残差,如果没有在这条线上,都是随机的,也就是说,没有任何特定的模式。
也就是说,我希望我的剩余误差分布遵循一个普通的正态分布。
使用R语言,只需两行代码就可以优雅地完成这项工作。
绘制残差柱状图;
添加一个分位数图,其中有一条线穿过,即第一个和第三个分位数。
hist(lmfit$residuals)
qqnorm(lmfit$residuals);qqline(lmfit$residuals)
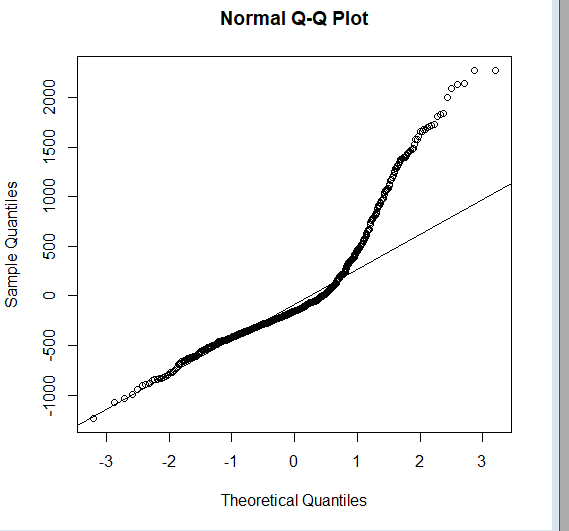
于是,我们知道这个图偏离了正常值(正常值用直线表示)。
但这种非黑即白的信息一般是不够的。因此,我们应该检查偏态和峰度,以了解分布的分散性。
首先,我们将计算偏态;我们将使用一个简单的高尔顿偏态(Galton’s skewness)公式。
## 分布对称性检验:偏态
summary<-summary(lmfit$residuals)
Q1<-summary[[2]]
Q2<-summary[[3]]
Q3<-summary[[5]]
skewness<-((Q1-Q2)+(Q3-Q2))/(Q3-Q1)
skewness
[1] 0.2665384
这量化了分布的方向(分布于右侧或左侧,或者是否完全对称或均匀)。
另一个度量角度是峰度,它显示分布是朝向中心(+ve值)还是远离中心(-ve值)。峰度是一个量化离群值可能性的指标。正值表示离群的存在。
kurtosis(lmfit$residuals)
[1] 2.454145
接下来,除了可视化残差的分布,我还想找出残差是否相互关联。
对于一个模型来说,为了解释观测值的所有变化,残差必须随机发生,并且彼此不相关。
Durbin-Watson测试允许检验残差彼此之间的独立性。
dwt(lm(df$days.windspeed~df$days.atemp+df$days.hum),method='resample', alternative='two.sided')
lag Autocorrelation D-W Statistic p-value
1 0.2616792 1.475681 0
Alternative hypothesis: rho != 0
对于给定的自由度和观测次数,需要将统计值与临界值表确定的下限和上限进行比较。文中案例的值域是[1.55,1.67]。
由于计算的D-W统计值低于该范围的较低值,我们拒绝了残差不相关的零假设。因此取而代之的假设是残差之间可能存在相关性。
直观地看,这个假设可以通过研究模型在试图捕获原始Y值的增加值时失败的原因来了解。当捕获增加值时,随着y的增加,残差与y成正比。
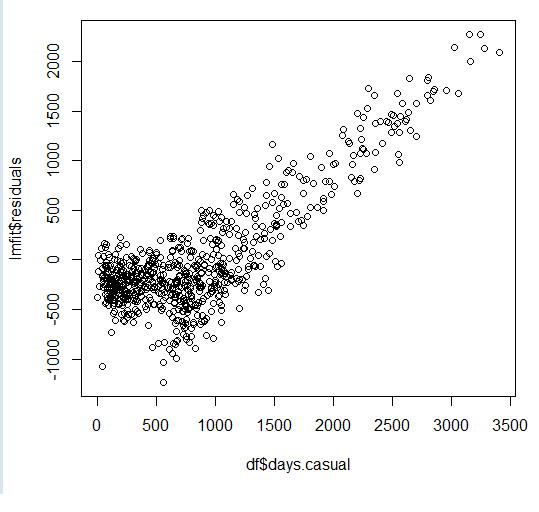
将其与绘制拟合y-hat值与y值进行比较。当y-hat值趋于落后时,残差似乎与y共同增长,故此,因为过去的残值似乎继续沿着固定的坡度值运行,过去的残值似乎是当前值的更好预测因子。同时,在达尔文-沃森检验(Darwin-Watson tests)中在残差与先前值之间的差的平方和,与所有观测的给定残差之和的比较和对比中,发现了相关性。
因此,残余误差之间的相关性就像心率测试失灵一样。如果你的模型不能跟上Y的快速变化,它会越来越和一个检验玩命的跑步者的情况类似,没记录上的步数似乎比跑步者实际的步数更相关。
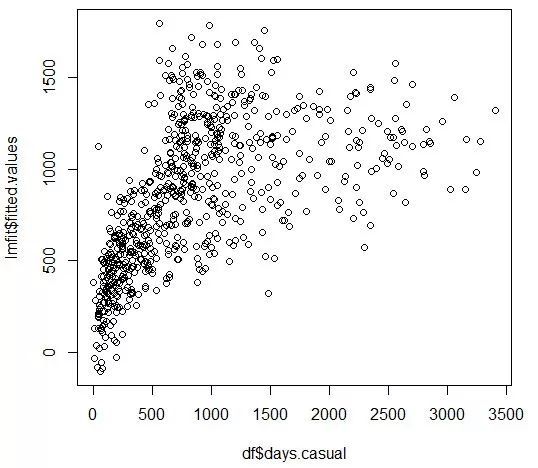
重构你的线性回归模型中的下意识影响。
有一点很重要:当对任何给定的观测集进行线性回归时,因变量(符号上表示为y)的计算估计量(符号上表示为y-hat)的每个值不仅依赖于当前值(例如,观察值),还依赖于每次观测。
毕竟,你的多元线性回归模型只在最小化因变量y的实际值和所有观测值y(y-hat)的计算估计值之间的误差后,才计算出每个影响因素的系数。
在数学上,这可以用简单的加权平均模型表示,如下所示。
Yhat(j)= w1j*Y(1)+w2j*Y(2)+w3j*Y(3)+w4j*Y(4)+.....+wnj*Y(n);
where n is number of observations and j is one particular estimated value.
如果你想用矩阵表示法来考虑这个问题,矩阵w的维数是[n,n],其中n是观察到的数目。同样,以矩阵形式表示的y具有尺寸[n,1],因此y-hat[j]表示为矩阵,因为它是两个矩阵(w和y)的乘积,并且具有与y相同的尺寸[n,1]。
因此,计算出的估计量的每一个值都可以表示为所有初始y值的加权平均值,表明给定的计算估计量在多大程度上受到每个初始y值的影响。
更简单地说,如果我看到一堆分散的观察结果,我必须以尽可能小的偏差,画一条直线穿过它们,也就是说,如果我必须遗漏一些观察结果,我必须在这条回归线的两侧平等地遗漏。
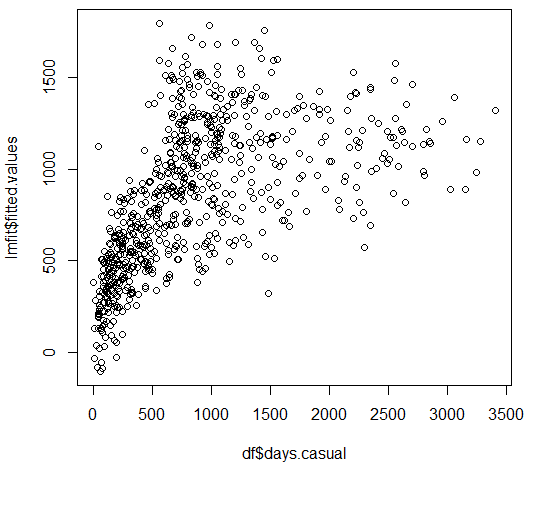
但是在这样做的同时,我(或选择的回归程序)不管来源何处,下意识地估计了每次观察对我回归线的斜率的影响程度。
我现在所做的就是重新计算这些影响。为了改变我的回归线,将它们包括在内或排除在外,每一个观察值的权重是多少?
权重的统计术语是hat values,因为它们连接了计算的估计量和它们的原始对应的估计量。
以下是用R语言计算的方法:
modelmatrix<-model.matrix(lmfit)
hatvalues<-hat(modelmatrix)
首先,我们得到一个矩阵形式的模型。然后我们计算hat值。
或者,可以使用以下函数获得类似的结果。
hatvalues<-lm.influence(lmfit)$hat
让我们考虑一下可以施加在每个权重上的限制。
显然,权重的最小可能值等于所有原始Y值贡献相等的可能性(因为它们必须为线性回归程序贡献一些东西,通过对所有观测进行工作和优化来估计系数)。
在这种情况下,其值域的下限为1/n,其中n是观测总数。在任何情况下,因为n总是+ve,所以权重总是<1。
现在试着将hat值加和,你会看到一个有趣的结果…
sum(hatvalues)
[1] 4
它们等于线性回归模型为计算考虑的影响因素数量+1。
例如,在示例数据集中,我们有三个因素,即温度、湿度和风速。

接下来,我们如何找到最重要或最有影响的观察结果?
一种优雅的方式是:
将hat值切分为四分位数。
应用95%标准过滤最异常值。
将该过滤标准应用于观察结果。
R语言允许你一步完成这些操作!
df[hatvalues>quantile(hatvalues,0.95),]
我们可以得到满足这一标准的具体观测结果。
days.instant days.atemp days.hum days.windspeed days.casual
9 9 0.1161750 0.434167 0.361950 54
21 21 0.1578330 0.457083 0.353242 75
22 22 0.0790696 0.400000 0.171970 93
26 26 0.2036000 0.862500 0.293850 34
32 32 0.2345300 0.829565 0.053213 47
36 36 0.2430580 0.929167 0.161079 100
45 45 0.3983500 0.375833 0.417908 208
50 50 0.3914040 0.187917 0.507463 532
65 65 0.3662520 0.948261 0.343287 114
69 69 0.3856680 0.000000 0.261877 46
90 90 0.2575750 0.918333 0.217646 179
94 94 0.5429290 0.426250 0.385571 734
95 95 0.3983500 0.642083 0.388067 167
106 106 0.4254920 0.888333 0.340808 121
153 153 0.6439420 0.305000 0.292287 736
239 239 0.6355560 0.850000 0.375617 226
249 249 0.5152000 0.886957 0.343943 204
293 293 0.4665250 0.636250 0.422275 471
302 302 0.2279130 0.882500 0.351371 57
341 341 0.4002460 0.970417 0.266175 50
368 368 0.1262750 0.441250 0.365671 89
383 383 0.2752540 0.443333 0.415429 109
388 388 0.2430580 0.911250 0.110708 145
408 408 0.1016580 0.464583 0.409212 73
421 421 0.2556750 0.395833 0.421642 317
433 433 0.5246040 0.567500 0.441563 486
434 434 0.3970830 0.407083 0.414800 447
463 463 0.4261290 0.254167 0.274871 3252
465 465 0.4766380 0.317500 0.358196 905
478 478 0.3895040 0.835417 0.344546 120
543 543 0.5947040 0.373333 0.347642 1077
627 627 0.5650670 0.872500 0.357587 371
667 667 0.4677710 0.694583 0.398008 998
668 668 0.4394000 0.880000 0.358200 2
694 694 0.2487420 0.404583 0.376871 532
722 722 0.2361130 0.441250 0.407346 205
726 726 0.2203330 0.823333 0.316546 9
最终,你可以用颜色编码使他们具象化。
##具象化
plot(df$days.casual,lmfit$fitted.values,col=ifelse(hatvalues>quantile(hatvalues,0.95),'red','blue'))
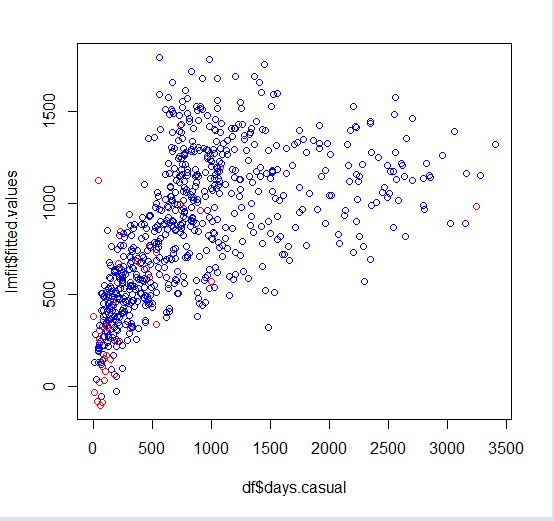
就是这样!这是进行残差分析和其重要性的简单概述。
原文标题:
Doing Residual Analysis Post Regression in R
原文链接:
https://dzone.com/articles/doing-residual-analysis-post-regression-in-r
编辑:王菁
校对:龚力
译者简介

张睿毅,北京邮电大学大二物联网在读。我是一个爱自由的人。在邮电大学读第一年书我就四处跑去蹭课,折腾整一年惊觉,与其在当下焦虑,不如在前辈中沉淀。于是在大二以来,坚持读书,不敢稍歇。资本主义国家的科学观不断刷新我的认知框架,同时因为出国考试很早出分,也更早地感受到自己才是那个一直被束缚着的人。太多真英雄在社会上各自闪耀着光芒。这才开始,立志终身向遇到的每一个人学习。做一个纯粹的计算机科学里面的小学生。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织