支持向量机(SVM)的分析及python实现
(本文所有代码都是基于python3.6的,数据及源码下载:传送门
引言
今天我们算是要来分享一个“高级”的机器学习算法了——SVM。大家自学机器学习一般都会看斯坦福的CS229讲义,初学者们大都从回归开始步入机器学习的大门。诚然回归学习起来与使用起来都很简单,但是这能达到我们的目的么?肯定不够的,要知道,我们可以做的不仅仅是回归。如果我们把机器学习算法看作是一种带斧子,剑,刀,弓,匕首等的武器,你有各种各样的工具,但你应该学会在正确的时间使用它们。打个比方,我们通常认为“回归”是一种能够有效地切割和切割数据的剑,但它不能处理高度复杂的数据。相反,“支持向量机”就像一把锋利的刀——它适用于更小的数据集(因为在大数据集上,由于SVM的优化算法问题,它的训练复杂度会很高),但它在构建模型时更加强大和有效。
什么是支持向量机
“支持向量机”(SVM)是一种监督机器学习算法,可用于分类或回归挑战。然而,它主要用于分类问题。在这个算法中,我们将每一个数据项作为一个点在n维空间中(其中n是你拥有的特征数)作为一个点,每一个特征值都是一个特定坐标的值。然后,我们通过查找区分这两个类的超平面来进行分类。如下图所示:

支持向量仅仅是个体观察的坐标。支持向量机是将两个类最好隔离的边界(超平面/行)。
支持向量机是如何工作的
上面我们介绍了支持向量机用超平面分隔两个类的过程,那么现在的问题是“我们怎样才能确定正确的超平面”?别担心,这个并没有你想象的那么难。
确定正确的超平面(场景1)
这儿我们有三个确定的超平面(A,B和C),现在确定正确的超平面来将五角星与圆分隔。
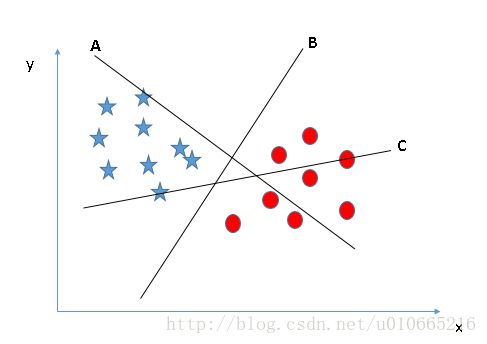
你需要记住一个经验法则来确定正确的超平面:“选择能更好地隔离两个类的超平面”。在这个场景中,超平面“B”出色地完成了这项工作。
确定正确的超平面(场景2)
这儿我们有三个确定的超平面(A,B和C),现在确定正确的超平面来将五角星与圆分隔。

在这里,最大化最近的数据点(或类)和超平面之间的距离将帮助我们确定正确的超平面。这段距离称为间隔(margin)。让我们看看下面的图形:

直观上我们会选择两类训练样本”正中间“的划分超平面C,因为该平面对训练样本局部扰动的容忍性最好。超平面A和B因为太过靠近两个类的分隔界,很容易受到训练集局限性或噪声的影响导致分类结果鲁棒性不好。
确定正确的超平面(场景3)
使用前面的规则来确定正确的超平面.
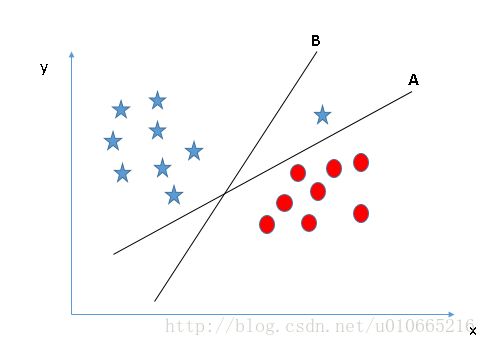
有些人可能选择了超平面B,因为它比A有更大的间距。但是,这里有一个问题,SVM选择了超平面的前提是:在最大化边距之前准确地分类了。在这里,超平面 B有一个分类错误,A已分类正确。因此,选择的超平面是A。
我们能将两个类正确分类么(场景4)

如图,另一端的一颗五角星就像五角星类的异常值。SVM有一个特性,可以忽略异常值,并找到最大间隔的超平面。因此,我们可以说,SVM对于异常值是健壮的。

找到超平面分隔两个类(场景5)
在下面的场景中,我们并不能找到一个线性超平面将两个类进行分隔。
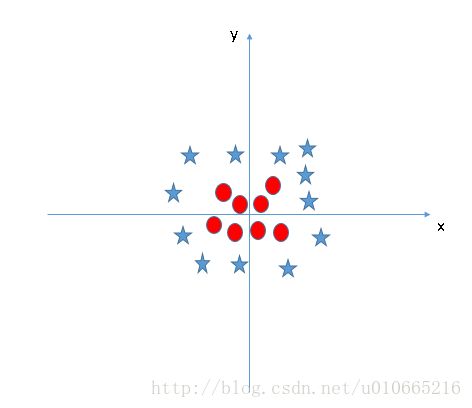
SVM可以解决这个问题。思路很简单,它通过引入额外特征来解决这个问题。它增加了一个新的特征 z=x2+y2 。现在让我们在z轴与x轴上画出这些点。
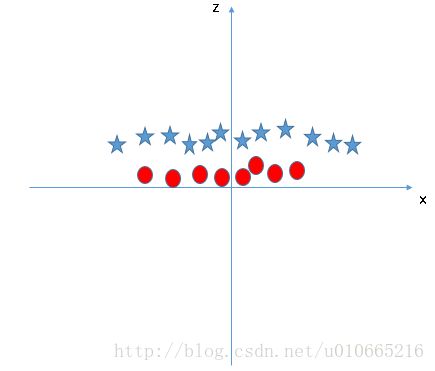
在以上的情况下,要考虑的要点是:
1. 因为z是x和y的平方之和,z的所有值都是正的。
2. 在原始的图中,红色的圆圈靠近x和y轴的原点,导致z和红色的圆圈相对较低,而五角星从原点到z的值更高。
在SVM中,在这两个类之间寻找一个线性的超平面是很容易的。但是,另一个问题是,我们是否应该手动添加这个特性来拥有一个超平面。答案是否定的,SVM有一个叫做kernel技巧的技术。这些函数是利用低维的输入空间,将其转换为高维空间,即它将不可分离的问题转化为可分离问题,这些函数称为核。在非线性分离问题中,它是很有用的。简单地说,它执行一些非常复杂的数据转换,然后根据您定义的标签或输出,找出分离数据的过程。
当我们看原始输入空间的超平面时它看起来像一个圆:

现在我们就来详细分析下SVM的工作原理
间隔与支持向量
在前面的分析中,我们知道SVM的工作原理就是:找到离分隔超平面最近的点,确保它们离分隔面的距离尽可能的远。这里点到分隔面的距离的两倍被称为间隔,支持向量就是离分隔超平面最近的那些点。在样本空间中,划分超平面可通过如下形式来描述:
其中 w=(w1;w2;...;wd) 为法向量,决定了超平面的方向;b为位移项决定了超平面与原点之间的距离。下面我们将其记为 (w,b) 。样本空间中任意点x到超平面 (w,b) 的距离可写为:
这里的常数b就类似于逻辑回归中的截距 w0
这里有了超平面,就可以讨论分类器问题了。
寻找最大间隔
确定分类器
我们确定一个分类器,对任意的实数,当 wTx+b>1,yi=1;wTx+b<−1,yi=−1 。有了分类器,那么我们的目标就是找到最小间隔的数据点,然后将其最大化并求出参数 w,b 。这就可以写作:
很显然 label⋅(wTxi+b)⩾1,i=1,2,...,m ,为了最大化间隔只需要最大化
我们知道上式本身是个凸二次规划的问题,能够使用现成的优化计算包求解,但我们可以有更高效的办法。
对偶问题
对上式使用拉格朗日乘子法可得到其对偶问题。则该问题的拉格朗日函数可写为
令 L(w,b,α) 对 w 和 b 的偏导为0可得:
则将上式代入L得最终的优化目标函数:
约束条件为:
求解出 α 后,求出 w 与 b 即可得到模型。
接下来,我们就是根据上面最后三个式子进行优化。有人或许会说,使用二次规划求解工具来求解上述最优化问题,这种工具是一种在线性约束条件下优化具有多个变量的而此目标函数的软件。这个工具需要强大的计算能力。于是Platt提出了一个称为SMO(序列最小化优化)的强大算法。
SMO
Platt的SMO算法是将大优化问题分解为许多小优化问题求解的,并且对它们顺序求解的结果与将它们作为整体求解的结果是完全一致的,时间还要短得多。
SMO算法的工作原理是:每次循环中选择两个alpha进行优化处理。一旦找到一对合适的alpha,那么就增大其中一个同时减小另一个。这里所谓的合适就是指两个alpha必须在间隔边界之外,或还没进过区间化处理或者不在边界上。(这个实现起来比较复杂,不作证明与实现)
核函数
前面在场景5里面我们有提到kernel技巧。我们SVM在处理线性不可分的问题是,通常将数据从一个特征空间转换到另一个特征空间。在新的特征空间下往往有比较清晰的测试结果。我们总结得到,如果原始空间是有限维的,即属性有限,那么一定存在一个高维特征空间使样本可分。
SVM中优化目标函数是写成内积的形式,向量的内积就是俩哥哥向量相乘得到单个标量或数值,我们假设 ϕ(x) 表示将 x 映射后的特征向量,那么优化目标函数变成:
要想直接求解 ϕ(xi)Tϕ(xj) 是困难的。为了避开这个障碍,就设想了一个函数:
就是 xi与xj 在特征空间的内积等于它们在原始样本空间中通过函数 k(⋅,⋅) 计算的结果。这样的函数就是核函数。核函数不仅仅应用于支持向量机,很多其他的机器学习算法也都应用到核函数,SVM比较流行的核函数称作径向基核函数(常用的核函数有线性核,多项式核,拉普拉斯核,sigmoid核,高斯核)。具体公式表现如下:
其中 σ 是用户定义的确定到达率或者说函数值跌落到0的速度参数。
在python中使用SVM
在Python中,scikit- learn是一个广泛使用的用于实现机器学习算法的库,SVM也可以在scikit- learning库中找到并使用。
基本应用
#Import Library
from sklearn import svm
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc(kernel='linear', c=1, gamma=1)
# there is various option associated with it, like changing kernel, gamma and C value. Will discuss more # about it in next section.Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)调参
优化机器学习算法的参数值,能有效地提高模型的性能。让我们看一下SVM可用的参数列表。
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma=0.0, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, random_state=None)我将讨论对模型性能有更高影响的一些重要参数“kernel”、“gamma”和“C”。
核函数我们已经讨论过了。在这里,我们有各种各样的选择,如“linear”(线性)、“rbf”(径向基”、“poly”(多项式)等(默认值是“rbf”)。这里的“rbf”和“poly”对于非线性超平面是有用的。我们使用sklearn中的测试数据集来进行测试。
不同kernel对比:
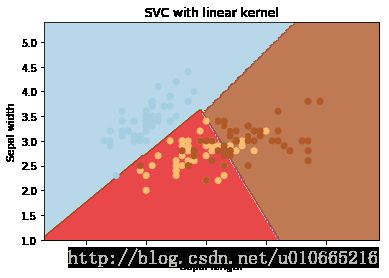


不同gamma对比:



“rbf”、“poly”和“sigmoid”的内核系数。更高gamma值,将尝试精确匹配每一个训练数据集,可能会导致泛化误差和引起过度拟合问题。
不同C对比:


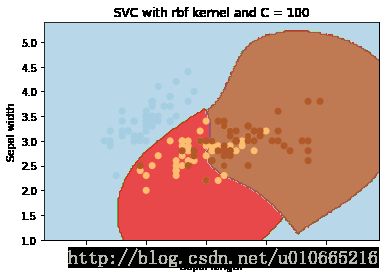
误差项的惩罚参数C。它还控制了平滑决策边界和正确分类训练点之间的权衡。即限制条件:
总结
支持向量机是一种分类器。之所以称为”机“是因为它会产生一个二值决策的结果,即它是一种决策”机“。有人认为支持向量机是监督学习中最好的定式算法。支持向量机试图通过求解一个二次优化问题来最大化分类间隔。
核方法或者说核技巧会将数据从一个低维空间映射到一个高维空间。
支持向量机是一个二分类器。当其解决多分类问题时需要用额外的方法对其进行扩展。而且SVM的效果也对优化参数和所用核函数中的参数敏感。