RCNN 系列之SPPNet详解
RCNN系列:RCNN,SPPNet,Fast RCNN,Faster RCNN,R-FCN。这一系列是个递进关系,也是目标检测使用two-stage方法的一个发展过程。想要更好的理解Faster RCNN和R-FCN,只能把这算法都梳理清楚了,才能明白这个递进过程。
本篇讲解的是SPPNet。2015年发表在IEEE。
SPPNet为何出现?
之前的网络,比如LeNet,AlexNet,ZF,VGG等,它们的输入都是固定大小的,为什么要固定大小呐?原因就在最后连接的全连接层上。全连接层的输入一定是固定大小的。这一点很容易理解,因为全连接层网络就是传统的神经网络,传统的神经网络的输入层必定是固定大小的。而卷积神经网络的conv层的输入并不需要固定大小,
如果对卷积不够熟悉的话,可以移步: http://blog.csdn.net/u010725283/article/details/78593410。
看完连接中的文章就明白为什么conv层不用固定大小了。
那么conv层不用固定大小,FC层的输入又要固定大小,那么在这两者之间加上一层SPP即可解决这个问题了。
下图即是SPPNet和其他的网络不同。

以上也即回答了SPPNet是什么和能做什么,总结一下,SPPNet就是为了能够让CNN能够输入不同尺度的图片。
SPP如何实现的?
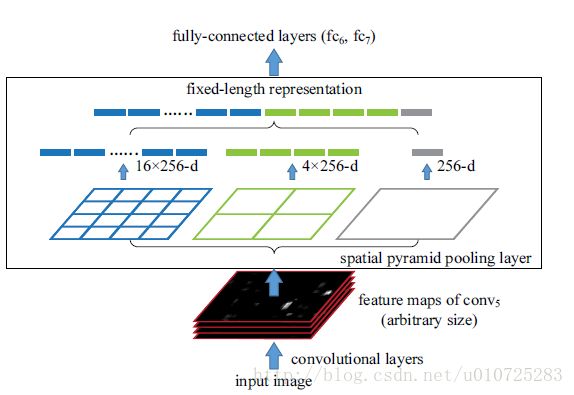
SPP(spatial pyramid pooling),中文名字就是空间金字塔池化。我的理解就是一种编码方式。以上图举例,黑色图像就是conv5出来的feature map,之前我们输入的图片是固定大小的,那么在conv5输出的feature map同样具有统一的大小。那现在如果输入不是固定的大小了,那么conv5输出的feature map是不同的尺寸。我们再以两种大小13*13,10*10的feature map来举例,这两个feature map大小不同,我们使用三种尺度的filter来做pooling,但最终的结果是可以得到4*4,2*2,1大小的256channels的feature map。那么再把这些feature map 级联在一起,就可以有固定大小的输出了。其实就是无论多大的feature map输入到SPP中,SPP都会输出一个固定的k*M大小输出。M就是我们选择的4*4+2*2+1,k就是输入feature map的通道数。
说的那么好,这种方法到底work 不work呐?
那就是论文的实验部分了,当然,深度学习论文中的实验部分非常关键,都是一些作者的训练深度网络的调参技巧。这一部分可以参考论文了,没有什么难点。
SPPNet现在已经完成了分类功能,那么怎么用它来做检测呐?
做检测首先要和RCNN做对比:

上图对比,
RCNN的整个过程是这样的:
- 通过selective search算法为每一张待检测图片提取出2000左右的候选框;
- 每张图片中的候选框调整到227*277大小,然后分别输入到CNN中提取特征;
- 提取到的特征后,利用svm对这些特征进行分类识别;
- 利用NMS算法对结果进行抑制处理。
2000个左右的proposal都要使用CNN来提取特征,计算量是很大的。然后利用这些特征进行分类时,同样需要很大的内存。
SPPNet的整个过程:
- 同样是使用selective search算法为每一张待检测的图片提取出2000左右的候选框,这一点和RCNN相同;
- 特征提取阶段,整个图片输入到SPPNet中,提取出整张图片的feature map,然后将原图上的候选框映射到feature map上。然后对各个候选框对应的feature map上的块做金字塔空间池化,提取出固定长度的特征向量;
- 使用SVM算法对得到的特征向量分类识别;
- 使用NMS做极大值抑制。
SPPNet和RCNN最大的不同就在于第二步处理上,对一张图片只做一次特征提取,显然会提高效率,速度得到很大的提升。
其中第二步将原图上的候选框映射到feature map上算是比较关键的点,怎么做映射呐?
假设(x',y')表示特征图上的坐标点,(x,y)表示原图上的坐标点,那么我们希望通过
(x,y)来求解
(x',y'),作者给出的计算公式如下:

其中,S是SPPNet中所有的strides的乘积,包含了池化和卷积的stride。
对以上公式的理解,要建立在卷积的过程上,我们再看一遍卷积的过程:

假设上图的左上角的点和右下角的点标出的区域就是我们要的候选区域,那么它对应的feature map即是右图。
我们就是利用这个区域两个点的坐标来求出来feature map上的对应的区域即可。
当然feature map上的一个点其实是对应了原图上的一个区域,我们也称作感受野。那么这样映射肯定会有误差的。这里不做过多的计较了。
总结:由于只关心检测过程,那么SPPNet对RCNN最大的提高即是:
RCNN对每个候选区域提取特征,
SPPNet
对整张图片提取特征然后根据候选区域去映射出候选区域的特征。
当然能够这样做的原因是在于SPP层,SPP层的存在可以让CNN输入不同大小的图片。
参考:
http://ufldl.stanford.edu/wiki/index.php/%E5%8D%B7%E7%A7%AF%E7%89%B9%E5%BE%81%E6%8F%90%E5%8F%96
http://blog.csdn.net/u010725283/article/details/78593410
Spatial Pyramid Pooling in Deep Convolutional
Networks for Visual Recognition